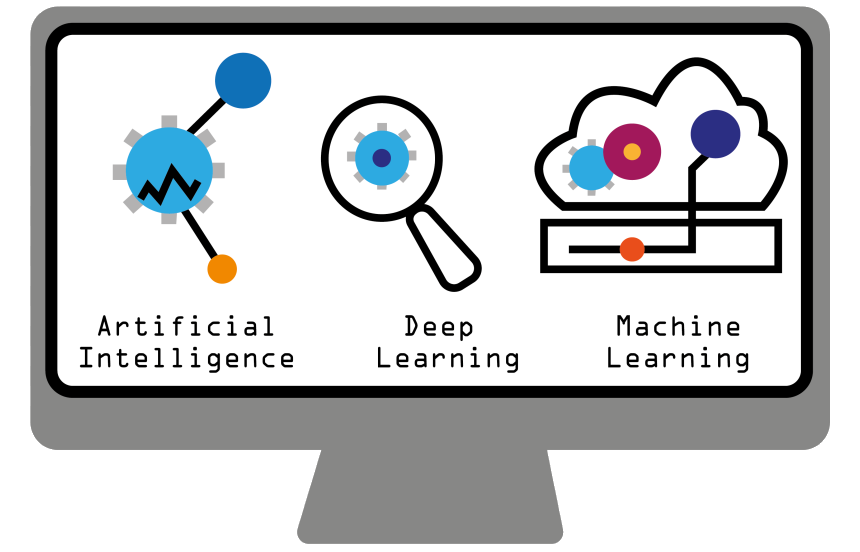
Nous sommes actuellement à un stade où l’on cherche à ce que les machines soient dotées d’une plus grande intelligence, atteignent une pensée autonome et une grande capacité d’apprentissage. Le deep learning ou apprentissage en profondeur est un concept relativement nouveau allant dans cette perspective. Il est étroitement lié à l’intelligence artificielle (IA) et fait partie des approches algorithmiques d’apprentissage automatique.
Qu’est-ce que le deep learning ?
Le deep learning ou apprentissage profond est défini comme un ensemble d’algorithmes qui se compose d’un réseau de neurones artificiels capables d’apprendre, s’inspirant du réseau de neurones du cerveau humain. En ce sens, il est considéré comme un sous-domaine de l’apprentissage automatique. L’apprentissage profond est lié aux modèles de communication d’un cerveau biologique, ce qui lui permet de structurer et de traiter les informations.
L’une des principales caractéristiques de l’apprentissage profond est qu’il permet d’apprendre à différents niveaux d’abstraction. Autrement dit, l’utilisateur peut hiérarchiser les informations en concepts. De même, une cascade de couches de neurones est utilisée pour l’extraction et la transformation des informations.
Le deep learning peut apprendre de deux manières : l’apprentissage supervisé et l’apprentissage non supervisé. Cela permet au processus d’être beaucoup plus rapide et plus précis. Dans certains cas, l’apprentissage profond est connu sous le nom d’apprentissage neuronal profond ou de réseaux neuronaux profonds. En effet, la définition la plus précise est que l’apprentissage profond imite le fonctionnement du cerveau humain.
Grâce à l’ère du Cloud Computing et du Big Data, le deep learning a connu une croissance significative. Avec lui, un haut niveau de précision a été atteint. Et cela a causé tellement d’étonnements, car il se rapproche chaque jour de la puissance perceptive d’un être humain.
Le deep learning fonctionne grâce à des réseaux de neurones profonds. Il utilise un grand nombre de processeurs fonctionnant en parallèle.
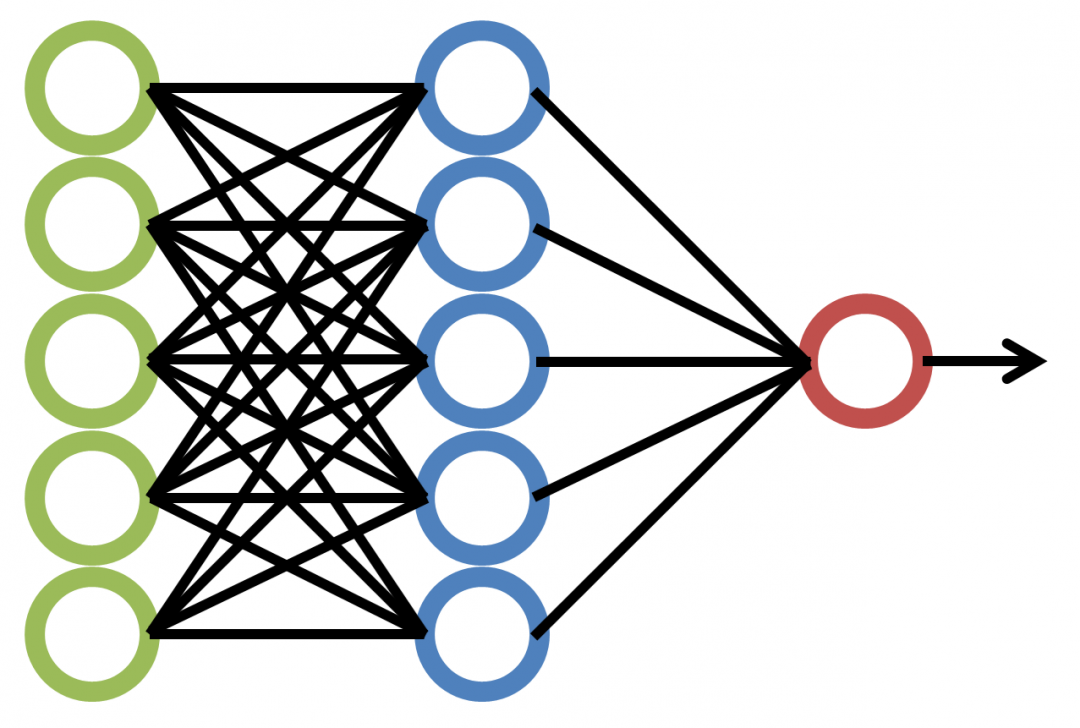
Les réseaux de neurones sont regroupés en trois couches différentes : couche d’entrée, couche cachée et couche de sortie. La première couche, comme son nom l’indique, reçoit les données d’entrée. Ces informations sont transmises aux couches cachées qui effectuent des calculs mathématiques permettant d’établir de nouvelles entrées. Enfin, la couche de sortie est chargée de fournir un résultat.
Mais, les réseaux de neurones ne fonctionnent pas si on ne tient pas compte de deux facteurs. Le premier est qu’il faut beaucoup de puissance de calcul. Le second fait référence au gigantesque volume de données auquel ils doivent accéder pour s’entraîner.
Pour sa part, les réseaux de neurones artificiels peuvent être entraînés à l’aide d’une technique appelée rétropropagation. Elle consiste à modifier les poids des neurones pour qu’ils donnent un résultat exact. En ce sens, ils sont modifiés en fonction de l’erreur obtenue et de la participation de chaque neurone.
Pour son bon fonctionnement, l’utilisation d’un processeur graphique est également importante. Autrement dit, un GPU dédié est utilisé pour le traitement graphique ou les opérations en virgule flottante. Pour traiter un tel processus, l’ordinateur doit être super puissant afin de pouvoir fonctionner avec un minimum de marge d’erreur.
L’apprentissage en profondeur a permis de produire de meilleurs résultats dans les tâches de perception informatique, car il imite les caractéristiques architecturales du système nerveux. En fait, ces avancées peuvent lui permettre d’intégrer des fonctions telles que la mémoire sémantique, l’attention et le raisonnement. L’objectif est que le niveau d’intelligence artificielle soit équivalent au niveau d’intelligence humain, voire le dépasser grâce à l’innovation technologique.
Quelles sont les applications du deep learning dans l’analyse du Big Data ?
Le deep learning dans l’analyse du Big Data est devenu une priorité de la science des données. On peut en effet identifier trois applications.
Indexation sémantique
La recherche d’informations est une tâche clé de l’analyse du Big Data. Le stockage et la récupération efficaces des informations sont un problème croissant. Les données en grande quantité telles que des textes, des images, des vidéos et des fichiers audio sont collectées dans divers domaines. Par conséquent, les stratégies et solutions qui étaient auparavant utilisées pour le stockage et la récupération d’informations sont remises en question par ce volume massif de données.
L’indexation sémantique s’avère être une technique efficace, car elle facilite la découverte et la compréhension des connaissances. Ainsi, les moteurs de recherche ont la capacité de fonctionner plus rapidement et plus efficacement.
Effectuer des tâches discriminantes
Tout en effectuant des tâches discriminantes dans l’analyse du Big Data, les algorithmes d’apprentissage permettent aux utilisateurs d’extraire des fonctionnalités non linéaires compliquées à partir des données brutes. Il facilite également l’utilisation de modèles linéaires pour effectuer des tâches discriminantes en utilisant les caractéristiques extraites en entrée.
Cette approche présente deux avantages. Premièrement, l’extraction de fonctionnalités avec le deep learning ajoute de la non-linéarité à l’analyse des données, associant ainsi étroitement les tâches discriminantes à l’IA. Deuxièmement, l’application de modèles analytiques linéaires sur les fonctionnalités extraites est plus efficace en termes de calcul. Ces deux avantages sont importants pour le Big Data, car ils permettent d’accomplir des tâches complexes comme la reconnaissance faciale dans les images, la compréhension de millions d’images, etc.
Balisage d’images et de vidéos sémantiques
Les mécanismes d’apprentissage profond peuvent faciliter la segmentation et l’annotation des scènes d’images complexes. Le deep learning peut également être utilisé pour la reconnaissance de scènes d’action ainsi que pour le balisage de données vidéo. Il utilise une analyse de la variable indépendante pour apprendre les caractéristiques spatio-temporelles invariantes à partir de données vidéo. Cette approche aide à extraire des fonctionnalités utiles pour effectuer des tâches discriminantes sur des données d’image et vidéo.
Le deep learning a réussi à produire des résultats remarquables dans l’extraction de fonctionnalités utiles. Cependant, il reste encore un travail considérable à faire pour une exploration plus approfondie qui comprend la détermination d’objectifs appropriés dans l’apprentissage de bonnes représentations de données et l’exécution d’autres tâches complexes dans l’analyse du Big Data.
Le Machine learning est un type d’intelligence artificielle (IA) qui permet aux ordinateurs d’apprendre sans être explicitement programmés. Il se concentre sur le développement de programmes informatiques qui peuvent changer lorsqu’ils sont exposés à de nouvelles données.
Le processus d’apprentissage automatique est similaire à celui de l’exploration de données. Les deux systèmes recherchent dans les données pour trouver des modèles. Cependant, au lieu d’extraire les données pour la compréhension humaine, le Machine learning utilise ces données pour détecter des modèles dans ces données et ajuster les actions du programme en conséquence. Par exemple, Facebook utilise l’apprentissage automatique pour ajuster chaque contenu en fonction du profil d’un utilisateur.
Dans le domaine en constante évolution de l’intelligence artificielle, les réseaux de neurones, ou neural networks en anglais, émergent comme des piliers fondamentaux de la technologie. Ces constructions inspirées du cerveau humain ont révolutionné la manière dont les machines apprennent et interprètent des données.
Cet article plongera au cœur des neural networks, explorant leur fonctionnement, leurs applications et leur impact croissant sur des domaines aussi variés que la reconnaissance d’images, le traitement du langage naturel et la résolution de problèmes complexes.
Introduction aux Neural Networks
Les Neural Networks, également connus sous le nom de réseaux de neurones artificiels, constituent une pierre angulaire de l’intelligence artificielle et du domaine du machine learning. Les réseaux neuronaux représentent des modèles mathématiques sophistiqués conçus pour analyser des données et exécuter des missions complexes. À la base, un réseau de neurones est constitué de plusieurs couches interconnectées, chacune contenant des « neurones » artificiels qui traitent et transmettent les informations.
L’objectif fondamental des neural networks est d’apprendre à partir des données. Ils sont capables de détecter des motifs, des tendances et des relations au sein de la data, ce qui les rend particulièrement adaptés à des tâches telles que la reconnaissance d’images, la traduction automatique, la prédiction de séquences et bien plus encore. En ajustant les poids et les biais des connexions entre les neurones en fonction des données d’entraînement, les neural networks sont en mesure de généraliser leurs apprentissages et d’appliquer ces connaissances à de nouvelles données, ce qui en fait des outils puissants pour résoudre une variété de problèmes complexes.
Fonctionnement des Neurones Artificiels
Les éléments fondamentaux des réseaux de neurones, appelés neurones artificiels, s’inspirent du fonctionnement des neurones biologiques du cerveau humain. Chaque neurone artificiel reçoit des signaux d’entrée pondérés, qui sont sommés. Si cette somme dépasse un seuil, le neurone s’active, générant ainsi une sortie. Cette sortie devient l’entrée pour les neurones de la couche suivante. Les connexions entre les neurones sont liées à des poids, qui dictent l’importance de chaque connexion dans le calcul de la sortie. Les neurones artificiels apprennent en ajustant ces poids avec les données d’entraînement.
Les réseaux de neurones se déploient en couches : entrée, cachées et sortie. Les données d’entrée passent par la couche d’entrée, puis traversent les couches cachées où les calculs se déroulent. La couche de sortie fournit le résultat final. Des fonctions d’activation insérées dans les neurones introduisent des seuils non linéaires, capturant ainsi des relations complexes entre les données. Par des algorithmes d’apprentissage, les poids des connexions s’ajustent pour réduire la différence entre prédictions et sorties réelles, optimisant ainsi la généralisation du réseau pour obtenir des résultats précis sur de nouvelles données.
Les Différents Types de Neural Networks
Les réseaux de neurones, base fondamentale de l’apprentissage profond, se diversifient en types variés, adaptés à des tâches spécifiques. Parmi eux se trouvent les réseaux de neurones feedforward, aussi appelés perceptrons multicouches (MLP), qui comportent des couches successives de neurones. Ils sont utilisés pour la classification, la régression et la reconnaissance de motifs.
Les réseaux de neurones convolutifs (CNN), quant à eux, se focalisent sur les données structurées comme les images. Ils emploient des couches de convolution pour extraire des caractéristiques, suivies de sous-échantillonnage pour réduire les données. Les CNN excellent dans la reconnaissance d’images, la détection d’objets et la segmentation. D’autre part, les réseaux de neurones récurrents (RNN) se concentrent sur les séquences, comme le langage naturel. Leur architecture gère les dépendances temporelles et les entrées variables, utiles pour la traduction, la génération de texte et l’analyse de sentiment. Chaque type de réseau de neurones présente des avantages selon les données et les objectifs d’apprentissage.
Deep Learning et Couches Profondes dans les Neural Networks
Le Deep Learning, une sous-branche de l’apprentissage automatique, s’est révélé être une avancée majeure dans la réalisation de tâches complexes en utilisant des réseaux de neurones profonds. L’idée fondamentale derrière le Deep Learning est de construire des réseaux de neurones comportant plusieurs couches de traitement, également appelées couches profondes. Ces couches multiples permettent aux réseaux de capturer des représentations hiérarchiques et abstraites des données, améliorant ainsi leur capacité à résoudre des problèmes de plus en plus complexes.
Les couches profondes d’un réseau de neurones sont composées de neurones connectés en série, chacun effectuant une transformation mathématique des données qu’il reçoit en entrée. Les premières couches du réseau sont généralement responsables de l’extraction de caractéristiques simples, telles que les bords ou les formes basiques, tandis que les couches ultérieures combinent ces caractéristiques pour former des représentations plus complexes et sémantiques. L’ensemble du processus d’apprentissage vise à ajuster les poids et les biais des neurones afin de minimiser l’erreur entre les sorties prédites du réseau et les véritables étiquettes.
L’avantage clé des réseaux de neurones profonds réside dans leur capacité à apprendre des modèles de données à différents niveaux d’abstraction, ce qui les rend adaptés à une variété de tâches, de la reconnaissance d’images à la traduction automatique. Cependant, la profondeur accrue des réseaux ajoute également à la complexité de l’entraînement et à la nécessité de techniques avancées pour éviter le surapprentissage. Malgré ces défis, le Deep Learning a propulsé les performances de l’apprentissage automatique à de nouveaux sommets, ouvrant la voie à des applications innovantes et à des avancées significatives dans divers domaines.
Generative Adversarial Networks (GAN)
Les Réseaux Générateurs Adversaires (GAN) représentent une avancée révolutionnaire dans le domaine de l’intelligence artificielle, en particulier dans la génération de contenu réaliste comme des images, des vidéos et même du texte. Les GAN ont été introduits en 2014 par Ian Goodfellow et ses collègues, et depuis lors, ils ont suscité un grand engouement pour leur capacité à créer des données nouvelles et authentiques à partir de zéro.
L’architecture des GAN est basée sur deux réseaux neuronaux profonds antagonistes : le générateur et le discriminateur. Le générateur crée des données synthétiques, tandis que le discriminateur essaie de faire la distinction entre les données réelles et générées. Au fil de l’entraînement, le générateur s’améliore en essayant de tromper le discriminateur, et celui-ci s’améliore en distinguant de mieux en mieux entre les deux types de données.
Le processus de compétition entre le générateur et le discriminateur permet aux GAN de produire des données de haute qualité qui sont difficilement distinguables des données réelles. Cette technologie a eu un impact majeur sur la création d’art numérique, la synthèse de vidéos, la génération de scénarios pour les simulations et même la création de visages humains synthétiques réalistes. Cependant, les GAN ne sont pas sans leurs défis, notamment en ce qui concerne la stabilité de l’entraînement et le contrôle de la qualité des données générées. Malgré cela, les GAN continuent de susciter un intérêt croissant et ouvrent de nouvelles perspectives passionnantes pour la création et la manipulation de contenu numérique.
Tendances Futures dans le Domaine des Neural Networks
Le domaine des réseaux neuronaux connaît actuellement une croissance exponentielle, avec des avancées et des tendances futures qui ouvrent de nouvelles perspectives passionnantes. L’une de ces tendances est l’expansion continue du Deep Learning vers des domaines tels que la vision par ordinateur, le traitement du langage naturel et même la science des données. Les architectures de réseaux neuronaux de pointe, telles que les réseaux neuronaux convolutifs (CNN) et les réseaux récurrents, sont constamment affinées pour obtenir des performances encore meilleures dans des tâches complexes comme la traduction automatique, la compréhension du langage naturel et la reconnaissance d’objets.
Une autre tendance prometteuse est l’intégration de l’intelligence artificielle dans les objets quotidiens via l’Internet des Objets (IoT). Les réseaux neuronaux embarqués sur des dispositifs connectés permettront des interactions plus intelligentes et personnalisées avec nos environnements. De plus, la montée en puissance du traitement automatisé des langues naturelles et la génération de contenu multimédia par les réseaux neuronaux soulèvent des questions passionnantes sur la créativité, l’éthique et les limites de l’IA.
Alors que l’industrie continue de s’appuyer sur les réseaux neuronaux pour résoudre des problèmes de plus en plus complexes, la collaboration interdisciplinaire, les innovations algorithmiques et les percées matérielles joueront un rôle crucial dans la définition des prochaines tendances. Les réseaux neuronaux ne cessent d’évoluer et de remodeler le paysage technologique, ouvrant la voie à un avenir où l’intelligence artificielle sera de plus en plus intégrée dans notre quotidien.
Depuis les premiers travaux de recherche dans les années 1950, l’Intelligence artificielle a pour but de créer des systèmes informatiques et des machines capables de réaliser des tâches exigeant normalement une intelligence humaine.
Elle vise à développer des algorithmes et des modèles permettant aux machines d’apprendre, de raisonner, de reconnaître des motifs, de prendre des décisions et de résoudre des problèmes de manière autonome.
Après une longue période de stagnation surnommée « hiver de l’IA », l’intérêt pour cette technologie a connu une résurgence majeure au cours des dernières années grâce aux avancées dans le domaine de l’apprentissage automatique. En particulier, l’utilisation des réseaux neurones profonds et du deep learning ont permis l’émergence de nouveaux cas d’usage.
Le machine learning permet aux ordinateurs d’apprendre à partir de données et de s’améliorer avec l’expérience. C’est ce qui permet à Amazon de recommander des produits, à Gmail de suggérer des réponses aux messages, ou à Spotify de vous conseiller de nouvelles musiques.
De même, le traitement du langage naturel (NLP) est une technique d’IA permettant aux machines de comprendre et d’interagir avec le langage humain. Les chatbots de service client et les assistants vocaux comme Apple Siri reposent sur cette technologie.
Avec l’apparition récente des Larges Modèles de Langage comme OpenAI GPT ou Google PaLM, de nouveaux outils ont vu le jour en 2022 : les IA génératives, telles que ChatGPT ou Bard.
Désormais, l’Intelligence artificielle est capable de générer n’importe quel type de contenu écrit, visuel ou même audio à partir d’un simple prompt entré par l’utilisateur.
C’est une révolution, mais il ne s’agit que d’un début. Dans un futur proche, l’IA servira de cerveau à des robots de forme humanoïde capables d’effectuer toutes sortes de tâches manuelles comme le Tesla Optimus.
À plus long terme, les recherches pourraient mener à la naissance d’une « Intelligence artificielle générale » qui serait équivalente ou même supérieure à l’intelligence humaine…
Il ne fait aucun doute que l’IA va changer le monde et permettre d’automatiser de nombreuses tâches intellectuelles ou manuelles. En contrepartie, beaucoup de métiers risquent de disparaître et plusieurs experts redoutent une vague de chômage sans précédent.
Toutefois, cette technologie va aussi créer des millions de nouveaux emplois. À mesure qu’elle évoluera, de nouveaux cas d’usage apparaîtront et la demande en experts capables de créer, de gérer ou d’appliquer l’Intelligence artificielle va s’accroître.
Afin de profiter de ces nouvelles opportunités professionnelles, suivre une formation en IA est un choix très pertinent pour votre carrière. Voici pour quelles raisons.
Pourquoi suivre une formation d’Intelligence artificielle ?
Selon le Forum Économique Mondial, le nombre d’emplois remplacés par l’IA sera largement surpassé par le nombre d’emplois créés. D’ici 2025, plus de 97 millions de nouveaux postes pourraient voir le jour.
Mieux encore : il s’agirait de rôles « plus adaptés à la nouvelle division du travail entre les humains, les machines et les algorithmes ».
Par conséquent, apprendre à maîtriser l’Intelligence artificielle dès à présent peut être un précieux sésame pour les futurs métiers de l’IA ou pour incorporer la technologie à votre profession actuelle.
La technologie va continuer de s’améliorer au cours des prochaines années, et s’étendre à des secteurs et champs d’application toujours plus diversifiés.
Elle est déjà utilisée dans de nombreuses industries telles que la finance, la médecine, la sécurité ou l’automobile et sera bientôt utilisée dans tous les domaines.
Face à la forte demande, les professionnels de l’IA peuvent bénéficier d’une rémunération élevée. Selon Talent.com, leur salaire médian en France atteint 45 000€ par an et dépasse 70 000€ pour les plus expérimentés.
L’ingénieur en Intelligence artificielle ou ingénieur IA est un professionnel utilisant les techniques d’IA et de Machine Learning pour développer des systèmes et applications visant à aider les entreprises à gagner en efficacité.
Cet expert se focalise sur le développement d’outils, de systèmes et de processus permettant d’appliquer l’IA à des problèmes du monde réel. Les algorithmes sont entraînés par les données, ce qui les aide à apprendre et à améliorer leurs performances.
Ainsi, un ingénieur IA permet à une organisation de réduire ses coûts, d’accroître sa productivité et ses bénéfices, et à prendre les meilleures décisions stratégiques. Selon Glassdoor, son salaire moyen atteint 40 000 euros en France et 120 000 dollars aux États-Unis.
De son côté, l’ingénieur en Machine Learning ou ML Engineer recherche, conçoit et construit l’IA utilisée pour le machine learning. Il maintient et améliore les systèmes existants, et collabore avec les Data Scientists développant les modèles pour construire les systèmes IA.
Au quotidien, ce professionnel mène des expériences et des tests, effectue des analyses statistiques et développe des systèmes de machine learning. Son salaire dépasse 50 000 euros en France selon Glassdoor, et 125 000 dollars aux États-Unis.
Un autre métier lié à l’IA est celui de Data Engineer. Il se charge de collecter, gérer et convertir les données brutes en informations exploitables pour les data scientists et autres analystes métier. Le salaire moyen est de 115 592 dollars aux États-Unis et 45 000 euros en France d’après Glassdoor.
De même, le Data Scientist utilise les données pour répondre aux questions et résoudre les problèmes d’une entreprise. Il développe des modèles prédictifs utilisés pour prédire les résultats, et peut utiliser les techniques de machine learning. Son salaire médian est de 48 000 euros en France et 126 000 dollars aux États-Unis.
L’ingénieur logiciel ou Software Engineer a lui aussi un rôle à jouer dans l’Intelligence artificielle. Il utilise le code informatique pour créer ou améliorer tout type de programme. Son salaire moyen atteint 55 000 euros en France et 107 000 dollars aux États-Unis.
Selon un rapport de McKinsey, en 2022, 39% des entreprises ont recruté des ingénieurs logiciels et 35% ont employé des Data Engineers pour des postes liés à l’IA.
Enfin, l’Intelligence artificielle sera très bientôt incorporée aux robots et les ingénieurs en robotique feront donc aussi partie des métiers de l’IA.
Ils se chargent de concevoir de nouveaux produits ou d’assembler des prototypes pour les tester, et observent leurs performances. Ce métier combinant l’ingénierie mécanique et électrique avec l’informatique permet de percevoir un salaire dépassant 42 000 euros par an et 100 000 dollars aux États-Unis.
Il ne s’agit là que de quelques exemples de métiers de l’IA. À l’avenir, de nombreuses autres professions vont apparaître comme celle du Prompt Engineer chargé de concevoir les prompts pour obtenir les meilleurs résultats avec un outil comme ChatGPT.
Quel que soit le rôle que vous souhaitez exercer dans le domaine de l’IA, il est essentiel de suivre une formation pour acquérir l’expertise requise.
Comment suivre une formation d’Intelligence artificielle ?
Pour lancer votre carrière dans l’Intelligence artificielle, vous pouvez obtenir une certification professionnelle afin de démontrer votre expertise aux employeurs.
Parmi les certifications IA les plus reconnues à l’heure actuelle, on compte la certification « MIT: Artificial Intelligence: Implications for Business Strategy », les certificats d’ingénieur, consultant et scientifique IA de l’USAII, ou encore le titre d’Artificial Intelligence Engineer ARTIBA.
Afin d’obtenir un diplôme et d’assimiler toutes les compétences indispensables pour travailler dans l’IA. Vous pouvez choisir DataScientest. Nos formations Machine Learning Engineer, Data Engineer ou Data Scientist vous permettront d’obtenir l’expertise requise pour exercer le métier de vos rêves.
Vous découvrirez notamment les fondamentaux de l’Intelligence artificielle, le machine learning, le traitement naturel du langage (NLP), la vision par ordinateur (Computer Vision), ou encore les enjeux éthiques liés à l’IA.
Depuis ces dernières années, les Data Scientist sont très recherchés par les entreprises. Ces professionnels travaillent avec d’importantes quantités de données ou Big Data. Leur rôle est de faire un croisement entre les données, les traiter et en déduire des conclusions qui permettent aux dirigeants de l’entreprise de prendre des décisions stratégiques en adéquation avec leurs objectifs.
En ce sens, un Data Scientist est un expert indispensable pour toute organisation qui souhaite se développer en anticipant les choix de ses clients grâce à une analyse des données les concernant.
Aujourd’hui, il s’agit d’un des métiers du Big Data (Data Analyst, Data Engineer…), dont la rémunération est l’une des plus élevées. Par considération de l’engouement des entreprises pour les compétences et l’expérience en Data Science, beaucoup se ruent pour décrocher un poste. Cependant, certains trouvent l’idée de devenir un Scientifique des données en freelance plus intéressant.
Le Data Scientist indépendant
Le Data Scientist connaît par cœur ce qu’est de gérer et d’analyser d’importantes quantités de données dans le genre du Big Data. Sa principale tâche est d’identifier des éléments grâce à l’analyse de données, et surtout le traitement de données qu’il a préalablement effectué pour la mise en place d’une stratégie apportant une solution à un problème.
Un freelance Data Scientist est donc un professionnel de la science des données en mission freelance. Tout comme un Scientifique des données en CDI dans une entreprise, il connaît tout ce qu’il faut faire avec le Big Data. Il anticipe les besoins de l’entreprise pour affronter ceux de ses clients.
Pour ce faire, il va :
–Déterminer les besoins de l’entreprise après exploration, analyse et traitement des données
–Conseiller les parties prenantes et les équipes par rapport à ces besoins
–Construire un modèle statistique
–Mettre au point des outils d’analyse pour la collecte de données
–Référencer et structurer les sources de données
–Structurer et faire la synthèse de ces sources
–Tirer parti des informations tirées des résultats
–Construire des modèles prédictifs
Compétences pour devenir Data Scientist freelance
Pour devenir Data Scientist indépendant, il faut bien évidemment avoir les compétences d’un Scientifique de données, à savoir :
Fondamentaux de la science des données
Statistiques
Connaissances en programmation (Python, R, SQL, Scala)
Devenir un Data Scientist, que ce soit en interne (dans une entreprise) ou en indépendant, il est nécessaire de suivre une formation spécifique à la Data Science avec ou sans aucune base sur les mathématiques et les statistiques.
En effet, la Science des données nécessite des connaissances en mathématiques, en statistique et en donnée informatique, et d’une certaine manière, en marketing. Être un Data Scientist, c’est devenir un expert dans la Data Science capable d’analyser les données dans le respect de la politique de confidentialité. Il en tire ensuite des informations précieuses permettant d’apporter des réponses aux problèmes actuels et des solutions aux besoins futurs.
Conditions pour devenir Data Scientist indépendant
Une fois que la certitude de pouvoir se lancer en freelance et d’assumer une variété de tâches est présente, il est possible de commencer à penser à passer dans l’environnement indépendant. Voici quelques éléments indispensables pour se lancer :
Expérience dans une variété de missions
Cette expérience peut résulter des études, d’une carrière en entreprise ou même d’un bénévolat. Pour un débutant, l’idéal est de proposer un service de consultant dans une entreprise locale pour acquérir de l’expérience tout en explorant ce qu’il faut pour être un freelance. Mais, il est essentiel d’avoir une expérience bien enrichie pour démontrer qu’une entreprise est très intéressée (ex : chef de projet data).
Portfolio des réalisations
Il est essentiel d’avoir un portfolio qui démontre le niveau de compétence. Cela devrait inclure plusieurs types de projets différents qui mettent en valeur la capacité à effectuer plusieurs types de travail tels que le développement et le test de diverses hypothèses, le nettoyage et l’analyse des données et l’explication de la valeur des résultats finaux.
Support du portfolio
Étant donné que l’un des avantages d’être indépendant est la possibilité de travailler à distance, il y a de fortes chances de décrocher un emploi à distance. Cela signifie que le premier contact avec des clients potentiels sera probablement en ligne. Un bon moyen de présenter les travaux déjà réalisés est de créer un site Web personnel afin de rendre le portfolio facile à parcourir. Il est important d’afficher clairement les moyens de contact.
S’inscrire sur une plateforme de recrutement en ligne
Un Data Scientist indépendant utilise généralement une plateforme en ligne ou un annuaire indépendant pour trouver du travail. Il y en a beaucoup où les entreprises publient des offres d’emploi et les freelances se vendent, ou où les entreprises contactent des freelances avec un projet data en tête.
Avoir de l’initiative pour trouver du travail
Bien que les plateformes de recrutement offrent la possibilité de soumissionner pour des emplois, un Data Scientist en freelance peut également sortir des sentiers battus dans la recherche d’un travail précieux et agréable. Il faut ne pas parfois chercher loin et penser « local » comme des entrepreneurs ou des start-ups qui pourraient bénéficier de compétences en Data Science.
Être leader dans son domaine
Au fur et à mesure que la situation d’indépendant prend de l’ampleur, il est important de mettre en valeur les connaissances et les compétences techniques dans le domaine de la Science des données. Par exemple, il est très vendeur d’être actif sur les forums en ligne pour les Data Scientists ou d’écrire des blogs ou des articles de leadership éclairé pour le site Web personnel. Les employeurs prendront note de ses connaissances, de cette perspicacité et de cette volonté de se démarquer lorsqu’ils recherchent un Data Scientist indépendant.
Avoir la volonté d’apprendre continuellement
Être dans un domaine nouveau et passionnant signifie qu’il faut être ouvert à tous et apprendre davantage sur la Data Science pour répondre aux besoins des futurs clients et plus encore. En ce sens, il ne faut pas hésiter à s’accorder du temps et les ressources nécessaires pour le perfectionnement professionnel comme la formation technique.
Pourquoi devenir Data Scientist indépendant ?
Maintenant que certaines des étapes clés à suivre sont connues, il est possible de se lancer dans une carrière de Data Scientist indépendant. Cependant, beaucoup se demandent pourquoi devenir un Scientifique des données en freelance.
Après tout, partir seul peut être un parcours intimidant. Il peut être effrayant de se demander où trouver du travail et si on gagne assez d’argent pour que cela en vaille la peine.
Si la présence d’un employeur, de collaborateurs et d’un lieu de travail n’est pas si importante, le statut d’indépendant est intéressant pour un Data Scientist. Voici quelques bonnes raisons de se lancer dans une carrière de freelance.
La place du marché
Le marché du travail indépendant en général a augmenté pour diverses raisons. Les employeurs sont de plus en plus à l’aise avec une main-d’œuvre distante et sont plus ouverts à l’embauche d’entrepreneurs plutôt que d’employés. Le marché des Data Scientists a également augmenté. Les entreprises comprennent de plus en plus la valeur de la Science des données et souhaitent que les efforts créatifs les aident à fournir des analyses et à traduire les informations en idées.
La flexibilité
En tant qu’indépendant, un Data Scientist travaille selon un horaire de travail flexible. Parfois, il doit travailler le week-end pour accélérer un projet. Mais parfois, il peut prendre un après-midi pour se reposer ou faire autre chose. C’est un réel avantage pour beaucoup. La flexibilité de travailler à distance, de n’importe où, est aussi un autre avantage d’être en freelance.
La diversité du travail
Il existe des profils de personnes qui aiment travailler sur une variété de projets pour une variété de clients. Une carrière de Data Scientist indépendant peut être dans ce cas le choix idéal.
La transformation digitale des entreprises est en marche ! Ce terme qui englobe tous les changements liés à l’intégration de nouvelles technologies dans la société contient le Big Data comme l’un de ses piliers les plus solides. Pour les entreprises, l’explosion des « grosses données » est au cœur des problématiques actuelles qu’elles doivent affronter. Cela nécessite la création de moyens efficaces pour les recevoir et les utiliser au mieux, permise par des professionnels aguerris des Data Sciences.
Les cabinets de conseil en stratégie sont des acteurs majeurs dans cette digitalisation de l’entreprise. Ils accompagnent les autres entreprises dans leur stratégie de transformation digitale, soit en tant que cabinets spécialisés, soit pour les cabinets généralistes en intégrant un segment dédié à leur offre d’expertise. Mais ils sont eux-mêmes sujets de cette transformation digitale et doivent intégrer de nouvelles compétences à leur cœur de métiers pour des propositions à plus forte valeur ajoutée.
Pourquoi intégrer les Data Sciences au conseil en stratégie ?
Aujourd’hui, la Data Science, ou science des données est utilisée par les entreprises comme outil d’analyse pour aider à la décision. Et plus il y a de données, plus le recours aux spécialistes de la data science est indispensable.
Le cas des cabinets de conseils en stratégie en est le parfait exemple. Ces derniers ont comme mission de répondre à une problématique précise pour le compte de leurs clients. L’expertise attendue d’eux repose sur la conduite de recherches et d’analyses stratégiques à partir de données fournies directement par les clients ou de données externes. Opérant sur une grande variété de secteurs, ils stockent donc un nombre de données très important.
Mais si les data sont historiquement au cœur du métier de consultant, les temps changent et les technologies avec. Pour fournir la meilleure analyse possible et garder un avantage concurrentiel, les cabinets se doivent d’évoluer au rythme de ces avancées. L’amélioration du CRM grâce à la personnalisation de la relation client, l’optimisation et la prédiction des coûts, la sécurisation et la détection de fraude, la vérification de l’authenticité de produits… sont tant d’exemples permis aujourd’hui par des méthodes et algorithmes très poussés au centre des outils utilisés dans les Data Sciences.
L’utilisation des Data Sciences intervient à chaque niveau de la chaine de valeur ; du début de la réflexion à la solution fournie au client en passant par le suivi. La conjoncture des 3 V qui définissent les Big Data – Volume, Vélocité, Variété – permet de mieux répondre aux due diligences et en un temps plus restreint.
C’est dans cette optique que le BCG a vu naître sa nouvelle entité dédiée à la Data Science : BCG Gamma. Avec Cedric Villani (médaille Fields 2010) comme conseiller scientifique, et l’INRIA (l’institut national de recherche en sciences du numérique) comme partenaire, le message porté par cette initiative est clair : mêler la recherche au monde de l’entreprise pour améliorer les performances. L’équipe est composée de 250 personnes : des experts scientifiques maitrisant les techniques mathématiques et statistiques liées à l’intelligence artificielle, au machine et deep learning, mais également des consultants experts dans les secteurs conseillés par le cabinet, concentrés sur l’aspect analytique des données.
Les profils des data-consultants
S’ils étaient absents du monde du conseil il y a encore 5 ans, les Data Sciences y sont aujourd’hui indispensables. Le recours à cette nouvelle science ne se fait plus seulement à travers l’utilisation ponctuelle de l’expertise d’acteurs de la tech dans le cadre de partenariats. Aujourd’hui, les Data Scientists arrivent au sein même des cabinets de conseils. Et demain, ils se mêleront à part entière aux consultants.
Chez ces férus d’informatique et de nouvelles technologies, les nouvelles façons de s’intégrer aux grands cabinets de conseil sont multiples. Toutefois, deux grandes tendances dominent : (1) être une fonction support (2) être un consultant à part entière.
L’équipe BCG Gamma réunit des doubles profils « consultants-data scientists » autour des problématiques classiques du grand groupe de conseil dans les différents secteurs où il opère. Ils sont pleinement intégrés au groupe et ont le même objectif final que tout consultant : conseiller le client en lui apportant une expertise poussée. Mais le moyen pour y parvenir diffère : « Là où un consultant utilisera Excel pour créer un modèle d’analyse, nous avons recours à des algorithmes pour modéliser des volumes de données plus complexes » (Thomas Lewiner, BCG Gamma). Aussi, à la différence du consultant type, les consultants « geeks » n’ont pas suivi un parcours en école de commerce ou d’ingénieur, mais des formations dédiées aux data sciences, en informatique, allant parfois jusqu’au doctorat (46%). Ces consultants s’inscrivent pleinement dans la transformation digitale des entreprises par leur utilisation des Data Sciences qui accélèrent et optimisent l’arrivée vers le résultat voulu.
Dans d’autres cabinets, les data scientists ne sont pas consultants mais forment une équipe bien distincte dont la vocation unique est de gérer les données.
C’est par exemple le cas de PMP ou d’EY qui se sont dotés en 2016 de leurs « Data Lab » ou « EY Digital Lab », choisissant de s’inscrire pleinement dans l’ère de la transformation digitale sans dénaturer la fonction de consultant. Ces deux laboratoires de la donnée ont comme rôle d’assurer une fonction support pour les différentes entités des groupes. Les talents de ces laboratoires s’occupent de traiter et gérer les données avant que les consultants ne les analysent pour en fournir une interprétation.
L’enjeu est de taille pour ces data scientists, car s’ils exercent leur métier sans se confondre aux consultants, ils doivent bien s’adapter à ces derniers. Pour générer un gain de temps grâce au Big Data, ils doivent donc parvenir à vulgariser leur langage afin qu’il soit exploitable au maximum et parfaitement intégré dans la chaine de valeur.
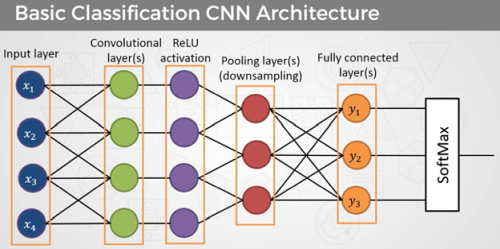
Le convolutional neural network est une forme spéciale du réseau neuronal artificiel. Il comporte plusieurs couches de convolution et est très bien adapté à l’apprentissage automatique et aux applications avec Intelligence artificielle (IA) dans le domaine de la reconnaissance d’images et de la parole, de la vente et du marketing ciblé et bien plus encore.
Introduction au convolutional neural network
L’appellation convolutional neural network signifie « réseau neuronal convolutif » en Français. L’abréviation est CNN. Il s’agit d’une structure particulière d’un réseau de neurones artificiels spécialement conçu pour l’apprentissage automatique et le traitement d’images ou de données audio.
Dans une certaine mesure, son fonctionnement est calqué sur les processus biologiques derrières les réflexions du cerveau humain. La structure est similaire à celle du cortex visuel d’un cerveau. Le convolutional neural network se compose de plusieurs couches. La formation d’un réseau de neurones convolutifs se déroule généralement de manière supervisée. L’un des fondateurs du réseau de neurones convolutifs est Yann Le Cun.
Mise en place d’un convolutional neural network
Des neurones selon une structure entièrement ou partiellement maillés à plusieurs niveaux composent les réseaux de neurones conventionnels. Ces structures atteignent leurs limites lors du traitement d’images, car il faudrait disposer d’un nombre d’entrées correspondant au nombre de pixels. Le nombre de couches et les connexions entre elles seraient énormes et ne seraient gérables que par des ordinateurs très puissants. Différentes couches composent un réseau neuronal convolutif. Son principe de base est un réseau neuronal à propagation avant ou feedforward neural network partiellement maillé.
Les couches individuelles de CNN sont :
Convolutional layers ou couches de convolution (CONV)
Pooling layers ou couches de Pooling (POOL)
ReLU layers ou couches d’activation ReLU (Rectified Linear Units)
Fully Connected layers ou couches Fully Connected (FC)
La couche de Pooling suit la couche de convolution et cette combinaison peut être présente plusieurs fois l’une derrière l’autre. La couche de Pooling et la couche de convolution étant des sous-réseaux maillés localement, le nombre de connexions dans ces couches reste limité et dans un cadre gérable, même avec de grandes quantités d’entrées. Une couche Fully Connected forme la fin de la structure.
Les tâches individuelles de chacune des couches
La couche de convolution est le plan de pliage réel. Elle est capable de reconnaître et d’extraire des caractéristiques individuelles dans les données d’entrée. Dans le traitement d’image, il peut s’agir de caractéristiques telles que des lignes, des bords ou certaines formes. Les données d’entrée sont traitées sous la forme d’une matrice. Pour ce faire, on utilise des matrices d’une taille définie (largeur x hauteur x canaux).
La couche de Pooling se condense et réduit la résolution des entités reconnues. À cette fin, elle utilise des méthodes telles que la mise en commun maximale ou la mise en commun de la valeur moyenne. La mise en commun élimine les informations inutiles et réduit la quantité de données. Cela ne réduit pas les performances du Machine Learning. Au contraire, la vitesse de calcul augmente en raison du volume de données réduit.
La couche d’activation ReLU permet un entraînement plus rapide et plus efficace en définissant les valeurs négatives sur zéro et en conservant les valeurs positives. Seules les fonctionnalités activées passent à la couche suivante.
La couche Fully Connected forme la fin d’un convolutional neural network CNN. Elle rejoint les séquences répétées des couches de convolution et de Pooling. Toutes les caractéristiques et tous les éléments des couches en amont sont liés à chaque caractéristique de sortie. Les neurones entièrement connectés peuvent être disposés dans plusieurs plans. Le nombre de neurones dépend des classes ou des objets que le réseau de neurones doit distinguer.
La méthode de travail à l’exemple de la reconnaissance d’image
Un CNN peut avoir des dizaines ou des centaines de couches qui apprennent à détecter différentes caractéristiques d’une image. Les filtres sont appliqués à chaque image d’apprentissage à différentes résolutions. La sortie de chaque image alambiquée est utilisée comme entrée pour la couche suivante. Les filtres peuvent aller de caractéristiques très simples telles que la luminosité et les contours à des caractéristiques plus complexes comme des spécificités qui définissent l’objet de manière unique.
Fonctionnalités d’apprentissage
Comme d’autres réseaux de neurones, une couche d’entrée, d’une couche de sortie et de nombreuses couches intermédiaires cachées composent un CNN. Ces couches effectuent des opérations qui modifient les données afin d’apprendre les caractéristiques spécifiques de ces données. Ces opérations se répètent en dizaines ou centaines de couches. Ainsi, chaque couche apprenne à identifier des caractéristiques différentes.
Poids partagé et valeurs de biais
Comme un réseau de neurones traditionnel, un CNN se compose de neurones avec des poids et des biais. Le modèle apprend ces valeurs au cours du processus de formation et les met continuellement à jour à chaque nouvel exemple de formation. Cependant, dans le cas des CNN, les valeurs des poids et des biais sont les mêmes pour tous les neurones cachés dans une couche spécifique.
Cela signifie que tous les neurones cachés détectent la même caractéristique telle qu’une bordure ou un point dans différentes régions de l’image. Cela permet au réseau de tolérer la traduction d’objets dans une image. Par exemple, un réseau formé à la reconnaissance des voitures pourra le faire partout où la voiture se trouve sur l’image.
Couches de classification
Après avoir appris les fonctionnalités multicouches, l’architecture d’un CNN passe à la classification. L’avant-dernière couche est entièrement connectée et produit un vecteur K-dimensionnel. Ici, K est le nombre de classes que le réseau pourra prédire. Ce vecteur contient les probabilités pour chaque classe de toute image classée. La couche finale de l’architecture CNN utilise une couche de classification pour fournir la sortie de classification.
Avantages d’un CNN dans le domaine de la reconnaissance d’images
Comparé aux réseaux neuronaux conventionnels, le CNN offre de nombreux avantages :
Il convient aux applications d’apprentissage automatique et d’Intelligence artificielle avec de grandes quantités de données d’entrée telles que la reconnaissance d’images.
Le réseau fonctionne de manière robuste et est insensible à la distorsion ou à d’autres changements optiques.
Il peut traiter des images enregistrées dans différentes conditions d’éclairage et dans différentes perspectives. Les caractéristiques typiques d’une image sont ainsi facilement identifiées.
Il nécessite beaucoup moins d’espace de stockage que les réseaux de neurones entièrement maillés. Le CNN est divisé en plusieurs couches locales partiellement maillées. Les couches de convolution réduisent considérablement les besoins de stockage.
Le temps de formation d’un CNN est également considérablement réduit. Grâce à l’utilisation de processeurs graphiques modernes, les CNN peuvent être formés de manière très efficace.
Il est la technologie de pointe pour le Deep Learning et la classification dans la reconnaissance d’images (image recognition).
Application d’un CNN dans le domaine du marketing
Le CNN est présent dans divers domaines depuis ces dernières années. La biologie l’utilise principalement pour en savoir plus sur le cerveau. En médecine, il fonctionne parfaitement pour la prédiction de tumeurs ou d’anomalies ainsi que pour l’élaboration de diagnostics complexes et de traitements à suivre en fonction des symptômes. Un autre domaine dans lequel il est couramment utilisé est celui de l’environnement. Il permet d’analyser les tendances et les modèles ou les prévisions météorologiques. Dans le domaine de la finance, il est couramment utilisé dans tout ce qui concerne la prévision de l’évolution des prix, l’évaluation ou l’identification du risque de contrefaçon.
Un CNN a de ce fait une application directe dans de nombreux domaines. Et pour faire face à l’accroissement de la quantité de données disponibles, il est également utilisé dans le marketing. En effet, dans le domaine des affaires et plus particulièrement en marketing, il a plusieurs usages :
Prédiction des ventes
Identification des modèles de comportement
Reconnaissance des caractères écrits
Prédiction du comportement des consommateurs
Personnalisation des stratégies marketing
Création et compréhension des segments d’acheteurs plus sophistiqués
Automatisation des activités marketing
Création de contenu
De toutes ses utilisations, la plus grande se trouve dans l’analyse prédictive. Le CNN aide les spécialistes du marketing à faire des prédictions sur le résultat d’une campagne, en reconnaissant les tendances des campagnes précédentes.
Actuellement, avec l’apparition du Big Data, cette technologie est vraiment utile pour le marketing. Les entreprises ont accès à beaucoup données. Grâce au travail de leur équipe experte dans la data science (data scientist, data analyst, data engineer), le développement de modèles prédictifs est beaucoup plus simple et précis. Les spécialistes du marketing pourront ainsi mieux ciblés les prospects alignés sur leurs objectifs.
Un Master Big Data peut signifier un débouché vers de nombreuses entreprises. Ces dernières ont en effet besoin de personnel professionnel pour gérer des données massives. Une formation en Big Data sert à obtenir des informations pertinentes permettant d’aider à la prise de décision. Et cela est essentiel dans la stratégie et la gestion de toute organisation, de la plus petite start up à la plus grande multinationale.
À grande échelle, le volume de données est énorme. Cela peut aller des transactions bancaires aux incidents de circulation en passant par les enregistrements des patients dans les hôpitaux, etc. Des milliards de données sont produites chaque seconde. En ce sens, une formation initiale ou continue dans le domaine du Big Data est l’un des pré-requis pour pouvoir travailler sur ces quantités colossales d’informations.
Quelques raisons de faire un Master Big Data
Il y a plusieurs raisons pour lesquelles il est tout à fait envisageable de se spécialiser dans le Big Data. En effet, un métier Big Data tel que le data analyst est un projet professionnel à la fois motivant et enrichissant.
Préparation aux défis
Le Master Big Data est intéressant pour la raison suivant : le professionnel se prépare à faire face à de nouveaux défis. Parmi ces derniers, on peut citer la vente, le Business Intelligence (BI), la gestion de bases de données, etc.
Vision globale
Le professionnel apprend à avoir une vision beaucoup plus globale de la nature des données. Sur cet aspect, il peut remarquer la différence dans leurs types et leur origine. Ainsi, il peut prendre une excellente décision lors de leur utilisation.
Développement des compétences techniques
Dans le Big Data, il est important que le professionnel soit capable de développer différentes techniques. Celles-ci lui permettront de faire une analyse des données. Comme pour le cas des data scientists, le développement d’une Intelligence artificielle via la Machine Learning permet de construire des modèles prédictifs.
Utilisation d’outils
Un Master Big Data permet de savoir comment utiliser les différents outils nécessaires à l’analyse des données, à leur bonne segmentation, à la description du client, etc.
Forte demande
Actuellement, les entreprises ont une très forte demande pour les métiers du Big Data. Par conséquent, un Master Big Data est une excellente voie pour se former dans l’un des domaines du Big Data qui sont requis par les meilleures entreprises du monde.
De meilleures opportunités d’emploi
Le Big Data est actuellement l’un des sujets les plus évoqués sur le marché du travail. La recherche d’expériences professionnelles est en hausse en raison du salaire élevé. Par conséquent, suivre un cursus Master Big Data augmente les chances de postuler pour de meilleurs emplois.
Une meilleure préparation
Un Master Big data permet d’avoir un profil et un cursus beaucoup plus spécialisés qui sont plus intéressants pour les entreprises. De cette manière, les possibilités sont plus larges et importantes.
Les sujets traités tout au long d’un Master Big Data
Un cursus Master Big Data peut se composé de différents modules de formation. Leur nombre dépend de l’école ou de l’université qui le propose. À titre d’exemple, celui de l’Université Paris 8 est une formation continue sur plusieurs domaines. Par exemple, l’Intelligence artificielle, les systèmes d’information, le Big Data et l’apprentissage automatique.
Pour faire simple, un Master Big Data consiste avant tout à inculquer aux étudiants le contenu de la partie calcul ou traitement du Big Data : développement de l’infrastructure, du stockage et du traitement des données. Ensuite, il y a la partie analytique de la data science qui porte sur le traitement, le nettoyage et la compréhension des données ainsi que l’application algorithmique et la visualisation des données.
Une fois ces bases acquises, les étudiants passent vers la partie concernant le Business Intelligence en mettant l’accent sur la réception et l’application pratique des données. Bien évidemment, des matières optionnelles peuvent être ajoutées au cursus afin d’acquérir des compétences spécifiques comme la gestion de projet Big Data, le Cloud Computing ou le Deep Learning.
Les compétences développées durant un Master Big Data
Programmation en R pour les méthodes statistiques et Python pour le Machine Learning.
Utilisation des plateformes telles qu’AWS, BigML, Tableau Software, Hadoop, MongoDB.
Gestion et récupération d’informations à l’aide de systèmes de gestion de bases de données relationnelles et NoSQL.
Traitement des données distribué et application des modèles MapReduce et Spark.
Configuration du framework Hadoop et utilisation des conteneurs.
Visualisation des données et de reporting pour l’évaluation des modèles de classification et des processus métier.
Procédures ETL et utilisation appropriée des stratégies à l’aide d’outils de pointe.
Conception de stratégies de Business Intelligence et intégration du Big Data avec le Data Warehouse.
Les points forts d’un Master Big Data
Ceux qui souhaitent faire Master Big Data sont formés tout au long d’un cursus d’avant-garde. De plus, des mises à jour du contenu sont constamment enseignées en raison de l’évolution des technologies. Chaque étudiant acquière un profil professionnel qui répond aux besoins réels du marché.
En effet, le cursus comprend des phases pratiques. Ici, l’étudiant est formé aux nouvelles technologies liées au Big Data et aux outils les plus utilisés sur le marché du travail. Il travaille entre autre sur des projets pour développer et mettre en œuvre des solutions Big Data en situation réelle.
Par ailleurs, étant donné que des séminaires sur le domaine du Big Data sont souvent organisés, les étudiants en Master Big Data sont invités à y participer. Par exemple : des échanges avec des enseignants chercheurs, des chefs d’entreprise, etc. L’objectif est de compléter leurs connaissances des outils de Cloud Computing, Business Intelligence, Machine Learning, méthodologies de projet Big Data, etc.
Les débouchés avec un Master Big Data
Les professionnels du Big Data sont parmi les plus demandés par les entreprises. Ils seront également les plus recherchés à l’avenir. Les organisations se concentrent sur la collecte de données et l’analyse des informations clients ainsi que sur l’interprétation des données massives.
Le besoin de profils analytiques dans différents secteurs d’activité croît dans les entreprises. Par conséquent, elles requièrent plus d’analyse de données et de développement d’Intelligences Artificielles. C’est pour cette raison que les métiers du Big Data ci-dessous sont les postes en ligne de mire des détenteurs d’un Master Big Data.
1. Chief data officer
Le chief data officer (CDO) est le responsable des données au plus haut niveau sur le plan technologique, commercial et sécuritaire. Il est chargé de la gestion des données en tant qu’actif de l’entreprise. Ses fonctions comprennent la stratégie d’exploitation des données et la gouvernance des données.
2. Digital analyst
Sa mission est de donner du sens aux données collectées grâce à différents outils de mesure en ligne. À travers des rapports, des présentations et des tableaux de bord, il formule des recommandations stratégiques pour aligner les objectifs de l’entreprise sur ceux qu’il a pu mesurer en ligne. Il développe également des propositions d’optimisation pour les sites en ligne et conçoit des stratégies de mesure. Une connaissance approfondie du marketing, de la stratégie commerciale et des compétences en communication sont nécessaires pour qu’il ait la capacité de rendre compte des résultats.
3. Data analyst
Il vise à donner du sens aux données collectées à partir des projets d’intégration Big Data et transforme ces données en informations utiles et pertinentes pour l’entreprise. Il est en charge de la gestion et de l’infrastructure des données, de la gestion des connaissances et de la direction des plans d’analyse de données dans des environnements tels que les réseaux sociaux. Une connaissance de la programmation, des bibliothèques d’analyse de données, des outils d’Intelligence artificielle et des rapports est requise.
4. Data scientist
Le data scientist réalise des algorithmes d’apprentissage automatique qui seront capables d’automatiser les modèles prédictifs, c’est-à-dire, de prédire et de classer automatiquement les nouvelles informations. Pour ce faire, il possède des compétences en statistiques et mathématiques appliquées.
Ce professionnel est en charge de la conception et de la gestion de gros volumes de données. Il prépare les bases de données d’une manière alignée sur les objectifs de l’entreprise. Ainsi, d’autres professionnels peuvent effectuer l’analyse des données pertinentes.
6. Business Intelligence analyst
Ce professionnel utilise des méthodes et des techniques analytiques pour comprendre le client et son impact sur l’entreprise. Il identifie les opportunités de monétisation grâce à l’analyse des données. Pour ce faire, il crée des stratégies centrées sur la relation client à partir de l’analyse des comportements issus du croisement des données CRM internes avec des données externes générées par l’interaction sociale. Cependant, il doit avoir un diplôme d’ingénieur, en statistiques ou en mathématiques ainsi que des compétences en gestion de bases de données et langages de programmation (ex : Python).
7. Expert en éthique et confidentialité des données
C’est l’un des profils qui sera demandé à l’avenir. En effet, il s’adaptera rapidement à tous les changements à venir dans un environnement très complexe et ambigu.
La data science ou science des données est une science appliquée. Elle fait appel à des méthodes et des connaissances issues de nombreux domaines tels que les mathématiques, les statistiques et l’informatique, notamment la programmation informatique. Depuis le début de ce millénaire, la data science est une discipline indépendante.
Il existe des cours spécifiques pour la science des données. Les personnes travaillant dans ce domaine sont connues sous le nom de data scientists ou scientifiques des données. Tout mathématicien, informaticien, programmeur, physicien, économiste d’entreprise ou statisticien qui a acquis ses connaissances en se spécialisant dans les tâches de science des données peut devenir un data scientist.
Le but de la data science est de générer des connaissances à partir de données. Dans l’environnement Big Data, la science des données est utilisée pour analyser des ensembles de données en grandes quantités avec l’apprentissage automatique (machine learning) et l’intelligence artificielle (IA). La science des données est utilisée dans diverses industries et domaines spécialisés.
Pour faire simple, les objectifs de la data science sont de :
Établir un moteur de recommandation à partir des données clients (sur le site, sur les réseaux sociaux…)
Aujourd’hui, les moteurs de recommandation de produits sont capables de rencontrer un client en temps réel. Par exemple, les magasins qui utilisent les recommandations de produits ont la possibilité de personnaliser chacune de leurs pages. Sur chacune d’elles, ils proposent des offres qui attirent le client de la page d’accueil à la page de paiement.
Fournir une aide à la décision
La prise de décision basée sur les données est définie comme l’utilisation de faits, de mesures et de données. Il est ainsi possible de guider les parties prenantes dans une entreprise à prendre des décisions stratégiques. Lorsqu’une organisation tire pleinement parti de la valeur de ses données, tous ceux qui y travaillent ont la capacité de prendre de meilleures décisions.
Optimiser et automatiser les processus internes
Les entreprises cherchent constamment à simplifier les tâches. Elles veulent également réduire les coûts. Cela est possible grâce à la data science. Il peut être aussi optimisé afin de gagner en efficacité et en compétitivité.
Soutenir les parties prenantes dans la gestion de l’entreprise
Outre l’aide à la prise de décision, la data science permet de recouper des données pertinentes pour apporter des éléments concrets. Sur ces derniers, les différents responsables d’une entreprise pourront baser leurs actions.
De développer des modèles prédictifs
Par le biais de l’analyse prédictive, la data science permet de prédire les événements futurs. En règle générale, les données sont utilisées pour créer un modèle mathématique afin de détecter les tendances les plus importantes. Ce modèle prédictif est ensuite appliqué aux données actuelles pour prédire les événements futurs ou suggérer des mesures à prendre pour obtenir des résultats optimaux.
La data science est une science interdisciplinaire qui utilise et applique des connaissances et des méthodes provenant de divers domaines. Les mathématiques et les statistiques constituent l’essentiel de ces connaissances. Ce sont les bases permettant au data scientist d’évaluer les données, de les interpréter, de décrire les faits ou de faire des prévisions. Dans le cadre de l’analyse prédictive, les statistiques inductives sont souvent utilisées en plus d’autres méthodes statistiques pour anticiper les événements futurs.
Un autre groupe de connaissances appliquées dans la science des données est la technologie de l’information et l’informatique. La technologie de l’information fournit des processus et des systèmes techniques de collecte, d’agrégation, de stockage et d’analyse des données. Les éléments importants dans ce domaine sont les bases de données relationnelles, les langages de requête de bases de données structurées tels que SQL (Structured Query Language), le langage de programmation et de script sur des outils tels que Python et bien plus encore.
En plus des connaissances scientifiques spécifiques, la data science accède à ce que l’on appelle la connaissance de l’entreprise (connaissance du domaine ou savoir-faire de l’entreprise). Elle est nécessaire pour comprendre les processus dans une organisation particulière ou une entreprise d’un secteur spécifique. La connaissance du domaine peut concerner des compétences commerciales : marketing de produits et services, savoir-faire logistique, expertise médicale.
La relation entre le Big Data et la data science
En raison de l’augmentation continuelle des volumes de données à traiter ou à analyser, le terme Big Data s’est imposé. Le Big Data est au cœur du traitement des données. Il concerne les méthodes, procédures, solutions techniques et systèmes informatiques. Ceux-ci sont capables de faire face au flux de données et au traitement de grandes quantités de données sous la forme souhaitée.
Le Big Data est un domaine important de la data science. La science des données fournit des connaissances et des méthodes pour collecter et stocker de nombreuses données structurées ou non structurées (par exemple dans un data lake ou lac de données), les traiter à l’aide de processus automatisés et les analyser. La science des données utilise, entre autres, l’exploration de données ou data mining, l’apprentissage statistique, l’apprentissage automatique (machine learning), l’apprentissage en profondeur (deep learning) et l’intelligence artificielle (IA).
Les personnes impliquées dans la science des données sont les scientifiques des données ou data scientists. Ils acquièrent leurs compétences soit en suivant une formation en data science, soit en se spécialisant dans le métier de data scientist.
Les scientifiques des données sont souvent des informaticiens, des mathématiciens ou des statisticiens. Ils sont également des programmeurs, des experts en bases de données ou des physiciens qui ont reçu une formation complémentaire en science des données.
En plus des connaissances spécifiques, un data scientist doit être en mesure de présenter clairement les modèles. Il les génère à partir des données et de les rapprocher de divers groupes cibles. Il doit également avoir des compétences appropriées en communication et en présentation. En effet, un data scientist a un rôle de conseiller ou de consultant auprès de la direction d’une entreprise. Les termes data scientist et data analyst sont souvent confondus dans l’environnement d’une entreprise. Parfois, leurs tâches et domaines d’activité se chevauchent.
L’analyste de données effectue une visualisation de données classique et pratique. De son côté, le data scientist poursuit une approche plus scientifique. Pour ce faire, il utilise des méthodes sophistiquées comme l’utilisation de l’intelligence artificielle ou de l’apprentissage automatique et des techniques avancées d’analyse et de prédiction.
Domaines d’application de la data science
Il n’y a pratiquement pas de limites aux applications possibles de la science des données. L’utilisation de la data science est logique partout où de grandes quantités de données sont générées et que des décisions doivent être prises sur la base de ces données. La science des données est d’une grande importance dans certains entreprises et activités : santé, logistique, vente au détail en ligne et en magasin, assurance, finance, industrie et manufacturing.
La Computer Vision ou vision par ordinateur est une technologie d’intelligence artificielle permettant aux machines d’imiter la vision humaine. Découvrez tout ce que vous devez savoir : définition, fonctionnement, histoire, applications, formations…
Depuis maintenant plusieurs années, nous sommes entrés dans l’ère de l’image. Nos smartphones sont équipés de caméras haute définition, et nous capturons sans cesse des photos et des vidéos que nous partageons au monde entier sur les réseaux sociaux.
Les services d’hébergement vidéo comme YouTube connaissent une popularité explosive, et des centaines d’heures de vidéo sont mises en ligne et visionnées chaque minute. Ainsi, l’internet est désormais composé aussi bien de texte que d’images.
Toutefois, s’il est relativement simple d’indexer les textes et de les explorer avec des moteurs de recherche tels que Google, la tâche est bien plus difficile en ce qui concerne les images. Pour les indexer et permettre de les parcourir, les algorithmes ont besoin de connaître leur contenu.
Pendant très longtemps, la seule façon de présenter le contenu d’une image aux ordinateurs était de renseigner sa méta-description lors de la mise en ligne. Désormais, grâce à la technologie de » vision par ordinateur » (Computer Vision), les machines sont en mesure de » voir « les images et de comprendre leur contenu.
Qu’est ce que la vision par ordinateur ?
La Computer Vision peut être décrite comme un domaine de recherche ayant pour but de permettre aux ordinateurs de voir. De façon concrète, l’idée est de transmettre à une machine des informations sur le monde réel à partir des données d’une image observée.
Pour le cerveau humain, la vision est naturelle. Même un enfant est capable de décrire le contenu d’une photo, de résumer une vidéo ou de reconnaître un visage après les avoir vus une seule fois. Le but de la vision par ordinateur est de transmettre cette capacité humaine aux ordinateurs.
Il s’agit d’un vaste champ pluridisciplinaire, pouvant être considéré comme une branche de l’intelligence artificielle et du Machine Learning. Toutefois, il est aussi possible d’utiliser des méthodes spécialisées et des algorithmes d’apprentissage général n’étant pas nécessairement liés à l’intelligence artificielle.
De nombreuses techniques en provenance de différents domaines de science et d’ingénierie peuvent être exploitées. Certaines tâches de vision peuvent être accomplies à l’aide d’une méthode statistique relativement simple, d’autres nécessiteront de vastes ensembles d’algorithmes de Machine Learning complexes.
En 1966, les pionniers de l’intelligence artificielleSeymour Papert et Marvin Minsky lance le Summer Vision Project : une initiative de deux mois, rassemblant 10 hommes dans le but de créer un ordinateur capable d’identifier les objets dans des images.
Pour atteindre cet objectif, il était nécessaire de créer un logiciel capable de reconnaître un objet à partir des pixels qui le composent. À l’époque, l’IA symbolique – ou IA basée sur les règles – était la branche prédominante de l’intelligence artificielle.
Les programmeurs informatiques devaient spécifiermanuellement les règles de détection d’objets dans les images. Or, cette approche pose problème puisque les objets dans les images peuvent apparaître sous différents angles et différents éclairages. Ils peuvent aussi être altérés par l’arrière-plan, ou obstrués par d’autres objets.
Les valeurs de pixels variaient donc fortement en fonction de nombreux facteurs, et il était tout simplement impossible de créer des règlesmanuellement pour chaque situation possible. Ce projet se heurta donc aux limites techniques de l’époque.
Quelques années plus tard, en 1979, le scientifique japonais Kunihiko Fukushima créa un système de vision par ordinateur appelé » neocognitron « en se basant sur les études neuroscientifiques menées sur le cortex visuel humain. Même si ce système échoua à effectuer des tâches visuelles complexes, il posa les bases de l’avancée la plus importante dans le domaine de la Computer Vision…
La révolution du Deep Learning
La Computer Vision n’est pas une nouveauté, mais ce domaine scientifique a récemment pris son envol grâce aux progrès effectués dans les technologies d’intelligence artificielle, de Deep Learninget de réseaux de neurones.
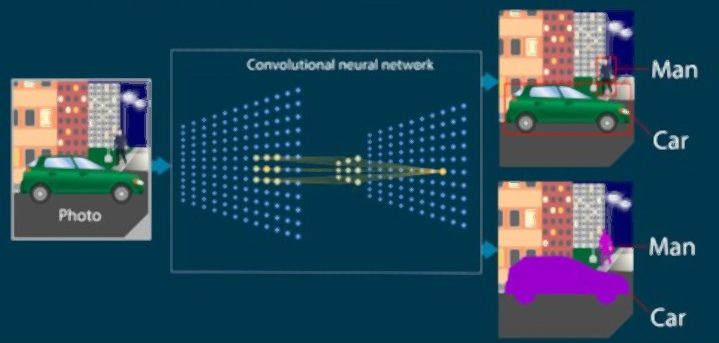
Dans les années 1980, le Français Yan LeCun crée le premier réseau de neurones convolutif : une IA inspirée par le neocognitron de Kunihiko Fukushima. Ce réseau est composé de multiples couches de neurones artificiels, des composants mathématiques imitant le fonctionnement de neurones biologiques.
Lorsqu’un réseau de neurones traite une image, chacune de ses couches extrait des caractéristiques spécifiques à partir des pixels. La première couche détectera les éléments les plus basiques, comme les bordures verticales et horizontales.
À mesure que l’on s’enfonce en profondeur dans ce réseau, les couches détectent des caractéristiques plus complexes comme les angles et les formes. Les couches finales détectent les éléments spécifiques comme les visages, les portes, les voitures. Le réseau produit enfin un résultat sous forme de tableau de valeurs numériques, représentant les probabilités qu’un objet spécifique soit découvert dans l’image.
L’invention de Yann LeCun est brillante, et a ouvert de nouvelles possibilités. Toutefois, son réseau de neurones était restreintpar d’importantes contraintes techniques. Il était nécessaire d’utiliser d’immenses volumes de données et des ressources de calcul titanesques pour le configurer et l’utiliser. Or, ces ressources n’étaient tout simplement pas disponibles à cette époque.
Dans un premier temps, les réseaux de neurones convolutifs furent donc limités à une utilisation dans les domaines tels que les banques et les services postaux pour traiter des chiffres et des lettres manuscrites sur les enveloppes et les chèques.
Il a fallu attendre 2012 pour que des chercheurs en IA de Toronto développentle réseau de neurones convolutif AlexNet et triomphent de la compétition ImageNet dédiée à la reconnaissance d’image. Ce réseau a démontré que l’explosion du volume de données et l’augmentation de puissance de calcul des ordinateurs permettaient enfin d’appliquer les » neural networks » à la vision par ordinateur.
Ce réseau de neurones amorça la révolution du Deep Learning : une branche du Machine Learning impliquant l’utilisation de réseaux de neurones à multiples couches. Ces avancées ont permis de réaliser des bonds de géants dans le domaine de la Computer Vision. Désormais, les machines sont même en mesure de surpasser les humains pour certaines tâches de détection et d’étiquetage d’images.
Comment fonctionne la vision par ordinateur
Les algorithmes de vision par ordinateur sont basés sur la » reconnaissance de motifs « . Les ordinateurs sont entraînés sur de vastes quantités de données visuelles. Ils traitent les images, étiquettent les objets, et trouvent des motifs (patterns) dans ces objets.
Par exemple, si l’on nourrit une machine avec un million de photos de fleurs, elle les analysera et détectera des motifs communs à toutes les fleurs. Elle créera ensuite un modèle, et sera capable par la suite de reconnaître une fleurchaque fois qu’elle verra une image en comportant une.
Les algorithmes de vision par ordinateur reposent sur les réseaux de neurones, censés imiter le fonctionnement du cerveau humain. Or, nous ne savons pas encore exactement comment le cerveau et les yeux traitent les images. Il est donc difficile de savoir à quel point les algorithmes de Computer Vision miment ce processus biologique.
Les machines interprètent les images de façon très simple. Elles les perçoivent comme des séries de pixels, avec chacun son propre ensemble de valeurs numériques correspondant aux couleurs. Une image est donc perçue comme une grille constituée de pixels, chacun pouvant être représenté par un nombre généralement compris entre 0 et 255.
Bien évidemment, les chosesse compliquent pour les images en couleur. Les ordinateurs lisent les couleurs comme des séries de trois valeurs : rouge, vert et bleu. Là encore, l’échelle s’étend de 0 à 255. Ainsi, chaque pixel d’une image en couleur à trois valeurs que l’ordinateur doit enregistrer en plus de sa position.
Chaque valeur de couleur est stockée en 8 bits. Ce chiffre est multiplié par trois pour une image en couleurs, ce qui équivaut à 24 bits par pixel. Pour une image de 1024×768 pixels, il faut donc compter 24 bits par pixels soit presque 19 millions de bits ou 2,36 mégabytes.
Vous l’aurez compris : il faut beaucoup de mémoire pour stocker une image. L’algorithme de Computer Vision quant à lui doit parcourir un grand nombre de pixels pour chaque image. Or, il faut généralement plusieurs dizaines de milliers d’images pour entraîner un modèle de Deep Learning.
C’est la raison pour laquelle la vision par ordinateur est une discipline complexe, nécessitant une puissance de calcul et une capacité de stockage colossales pour l’entraînement des modèles. Voilà pourquoi il a fallu attendre de nombreuses années pour que l’informatique se développe et permette à la Computer Vision de prendre son envol.
Les différentes applications de Computer Vision
La vision par ordinateur englobe toutes les tâches de calcul impliquant le contenu visuel telles que les images, les vidéos ou même les icônes. Cependant, il existe de nombreuses branchesdans cette vaste discipline.
La classification d’objet consiste à entraîner un modèle sur un ensemble de données d’objets spécifiques, afin de lui apprendre à classer de nouveaux objets dans différentes catégories. L’identification d’objet quant à elle vise à entraîner un modèle à reconnaître un objet.
Parmi les applications les plus courantes de vision par ordinateur, on peut citer la reconnaissance d’écriture manuscrite. Un autre exemple est l’analyse de mouvement vidéo, permettant d’estimer la vélocité des objets dans une vidéo ou directement sur la caméra.
Dans la segmentation d’image, les algorithmes répartissent les images dans plusieurs ensembles de vues. La reconstruction de scène permet de créer un modèle 3D d’une scène à partir d’images et de vidéos.
Enfin, la restauration d’imageexploite le Machine Learning pour supprimer le » bruit » (grain, flou…) sur des photos. De manière générale, toute application impliquant la compréhension des pixels par un logiciel peut être associée à la Computer Vision.
Quels sont les cas d’usages de la Computer Vision ?
La Computer Vision fait partie des applications du Machine Learning que nous utilisons déjà au quotidien, parfois sans même le savoir. Par exemple, les algorithmes de Googleparcourent des cartes pour en extraire de précieuses données et identifier les noms de rues, les commerces ou les bureaux d’entreprises.
De son côté, Facebook exploite la vision par ordinateurafin d’identifier les personnes sur les photos. Sur les réseaux sociaux, elle permet aussi de détecter automatiquement le contenu problématique pour le censurer immédiatement.
Les entreprises de la technologie sont loin d’être les seules à se tourner vers cette technologie. Ainsi, le constructeur automobile Ford utilise la Computer Vision pour développer ses futurs véhicules autonomes. Ces derniers reposent sur l’analyse en temps réel de nombreux flux vidéo capturés par la voiture et ses caméras.
Il en va de même pour tous les systèmes de voitures sans pilote comme ceux de Tesla ou Nvidia. Les caméras de ces véhicules capturent des vidéos sous différents angles et s’en servent pour nourrir le logiciel de vision par ordinateur.
Ce dernier traite les images en temps réel pour identifier les bordures des routes, lire les panneaux de signalisation, détecter les autres voitures, les objets et les piétons. Ainsi, le véhicule est en mesure de conduire sur autoroute et même en agglomération, d’éviter les obstacles et de conduire les passagers jusqu’à leur destination.
La santé
Dans le domaine de la santé, la Computer Vision connaît aussi un véritable essor. La plupart des diagnostics sont basés sur le traitement d’image : lecture de radiographies, scans IRM…
Google s’est associé avec des équipes de recherche médicalepour automatiser l’analyse de ces imageries grâce au Deep Learning. D’importants progrès ont été réalisés dans ce domaine. Désormais, les IA de Computer Vision se révèlent plus performantes que les humains pour détecter certaines maladies comme la rétinopathie diabétique ou divers cancers.
Le sport
Dans le domaine du sport, la vision par ordinateur apporte une précieuse assistance. Par exemple, la Major League Baseballutilise une IA pour suivre la balle avec précision. De même, la startup londonienne Hawk-Eye déploie son système de suivi de balle dans plus de 20 sports comme le basketball, le tennis ou le football.
La reconnaissance faciale
Une autre technologie reposant sur la Computer Vision est la reconnaissance faciale. Grâce à l’IA, les caméras sont en mesure de distinguer et de reconnaître les visages. Les algorithmes détectent les caractéristiques faciales dans les images, et les comparent avec des bases de données regroupant de nombreux visages.
Cette technologie est utilisée sur des appareils grand public comme les smartphones pour authentifier l’utilisateur. Elle est aussi exploitée par les réseaux sociaux pour détecter et identifier les personnes sur les photos. De leur côté, les autorités s’en servent pour identifier les criminels dans les flux vidéo.
La réalité virtuelle et augmentée
Les nouvelles technologies de réalité virtuelle et augmentée reposent également sur la Computer Vision. C’est elle qui permet aux lunettes de réalité augmentée de détecter les objets dans le monde réelet de scanner l’environnement afin de pouvoir y disposer des objets virtuels.
Par exemple, les algorithmes peuvent permettre aux applications AR de détecter des surfaces planes comme des tables, des murs ou des sols. C’est ce qui permet de mesurer la profondeur et les dimensionsde l’environnement réel pour pouvoir y intégrer des éléments virtuels.
Les limites et problèmes de la Computer Vision
La vision par ordinateur présente encore des limites. En réalité, les algorithmes se contentent d’associer des pixels. Ils ne » comprennent » pas véritablement le contenu des images à la manière du cerveau humain.
Pour cause, comprendre les relations entre les personnes et les objets sur des images nécessite un sens commun et une connaissance du contexte. C’est précisément pourquoi les algorithmes chargés de modérer le contenu sur les réseaux sociaux ne peuvent faire la différence entre la pornographie et une nudité plus candide comme les photos d’allaitement ou les peintures de la Renaissance.
Alors que les humains exploitent leur connaissance du monde réel pour déchiffrer des situations inconnues, les ordinateurs en sont incapables. Ils ont encore besoin de recevoir des instructions précises, et si des éléments inconnusse présentent à eux, les algorithmes dérapent. Un véhicule autonome sera par exemple pris de cours face à un véhicule d’urgence garé de façon incongrue.
Même en entraînant une IA avec toutes les données disponibles, il est en réalité impossible de la préparer à toutes les situations possibles. La seule façon de surmonter cette limite serait de parvenir à créer une intelligence artificielle générale, à savoir une IA véritablement similaire au cerveau humain.
Comment se former à la Computer Vision ?
Si vous êtes intéressé par la Computer Vision et ses multiples applications, vous devez vous former à l’intelligence artificielle, au Machine Learning et au Deep Learning. Vous pouvez opter pour les formations DataScientest.
Le Machine Learning et le Deep Learning sont au coeur de nos formations Data Scientist et Data Analyst. Vous apprendrez à connaître et à manier les différents algorithmes et méthodes de Machine Learning, et les outils de Deep Learning comme les réseaux de neurones, les GANs, TensorFlow et Keras.
Ces formations vous permettront aussi d’acquérir toutes les compétences nécessaires pour exercer les métiers de Data Scientist et de Data Analyst. À travers les différents modules, vous pourrez devenir expert en programmation, en Big Data et en visualisation de données.
Nos différentes formations adoptent une approche innovante de Blended Learning, alliant le présentiel au distanciel pour profiter du meilleur des deux mondes. Elles peuvent être effectuées en Formation Continue, ou en BootCamp.
Pour le financement, ces parcours sont éligibles au CPF et peuvent être financés par Pôle Emploi via l’AIF. À l’issue du cursus, les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne. Parmi nos alumnis, 93% trouvent un emploi immédiatementaprès l’obtention du diplôme. N’attendez plus, et découvrez nos formations.