
La capacité à comprendre et à expliquer les décisions prises par les modèles d’Intelligence Artificielle ou de Machine Learning est devenue primordiale. Ces technologies sophistiquées s’intègrent de plus en plus dans des domaines critiques tels que la santé, la finance ou encore la sécurité. Les solutions comme SHAP (SHapley Additive exPlanations) connaissent un essor fulgurant.
SHAP s’inspire des concepts de la théorie des jeux coopératifs, et offre une méthode rigoureuse et intuitive pour décomposer les prédictions des modèles en contributions individuelles de chaque caractéristiques.
Fondements théoriques de SHAP
Il est nécessaire d’analyser un tant soi peu les racines théoriques de SHAP afin de comprendre sa valeur ajoutée mais également la raison qui le rend efficace pour interpréter des modèles parfois complexes.
Théorie des jeux coopératifs
Cette théorie, une branche de la théorie des jeux, se concentre sur l’analyse des stratégies pour les groupes d’agents qui peuvent former des coalitions et partager des récompenses. Au cœur de cette théorie se trouve la notion de “valeur équitable”, une façon de distribuer les gains (ou les pertes) parmi les participants d’une manière qui reflète leur contribution individuelle. C’est dans ce contexte que la Valeur de Shapley.

La Valeur de Shapley
Il s’agit d’un concept mathématique, introduit par Lloyd Shapley en 1953, servant à déterminer la part juste de chaque joueur dans un jeu coopératif. Elle est calculée en considérant toutes les permutations possibles de joueurs et en évaluant l’impact marginal de chaque joueur lorsqu’il rejoint une coalition. En d’autres termes, elle mesure la contribution moyenne d’un joueur à la coalition, en tenant compte de toutes les combinaisons possibles dans lesquelles ce joueur pourrait contribuer.

Lien avec SHAP
Dans le contexte du machine learning, SHAP utilise la Valeur de Shapley pour attribuer une « valeur d’importance » à chaque caractéristique d’un modèle prédictif. Chaque caractéristique d’une instance de données est considérée comme un « joueur » dans un jeu coopératif où le « gain » est la prédiction du modèle.

Implications de la Valeur de Shapley en IA
Cette valeur représente une avancée significative dans l’interprétabilité des modèles d’IA. Elle permet non seulement de quantifier l’impact de chaque caractéristique de manière juste et cohérente, mais offre aussi une transparence qui aide à construire la confiance dans les modèles d’apprentissage automatique.
Comment fonctionne SHAP ?
Au cœur de SHAP se trouve l’idée de décomposer une prédiction spécifique en un ensemble de valeurs attribuées à chaque caractéristique d’entrée. Ces valeurs sont calculées de manière à refléter l’impact de chaque caractéristique sur l’écart entre la prédiction actuelle et la moyenne des prédictions sur l’ensemble des données. Pour y parvenir, SHAP explore toutes les combinaisons possibles de caractéristiques et leurs contributions à la prédiction. Ce processus utilise la Valeur de Shapley, que nous avons abordée précédemment, pour assurer une répartition équitable et précise de l’impact parmi les caractéristiques.
Prenons un exemple
Imaginons un modèle prédictif utilisé dans le secteur financier pour évaluer le risque de crédit. SHAP peut révéler comment des caractéristiques telles que le score de crédit, le revenu annuel et l’historique de remboursement contribuent à la décision finale du modèle. Si un client se voit refuser un crédit, SHAP peut indiquer quelles caractéristiques ont le plus influencé cette décision négative, fournissant ainsi des indicateurs pertinents.
Utilisation avec Python
Python propose une bibliothèque pour SHAP. Cette dernière permet aux utilisateurs de tirer pleinement parti des avantages de SHAP pour l’interprétabilité des modèles.
Installation
La première étape, est bien sûr l’installation de la bibliothèque
pip install shap |
Une fois installée, il ne reste plus qu’à l’importer dans votre environnement :
import shap |
Préparation des données
Supposons que vous ayez un modèle de Machine Learning déjà entraîné, tel qu’un modèle de forêt aléatoire pour la classification (RandomForestClassifier). Vous aurez donc besoin d’un ensemble de données pour l’analyse :
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier import pandas as pd # Load and prepare datas data = pd.read_csv(‘my_amazing_dataset.csv’) X = data.drop(‘target’, axis=1) y = data[‘target’] # Split train and test set X_train, X_test, y_train, y_test = # Train the model model = RandomForestClassifier(random_state=42) model.fit(X_train, y_train) |
Analyse SHAP
Après entraînement du modèle, l’utilisation de SHAP vous permettra d’analyser l’impact des caractéristiques. Pour la poursuite de cet exemple, nous pouvons utiliser le Explainer Tree.
# Create Explainer Tree explainer = shap.TreeExplainer(model) # Compute SHAP Values on the test set shap_values = explainer.shap_values(X_test) |
Visualisation des résultats
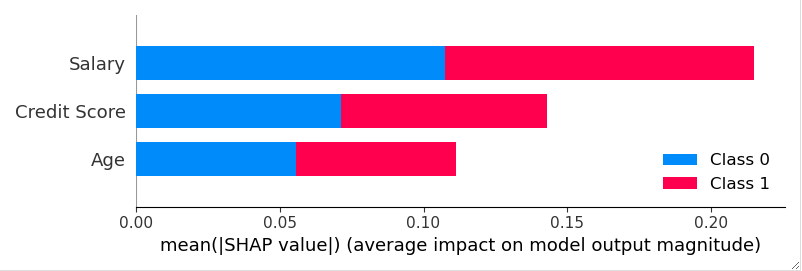
SHAP offre bien évidemment diverses options de visualisation pour interpréter les résultats. Ainsi, pour avoir un résumé quant à l’importance des caractéristiques :
shap.summary_plot(shap_values, X_test) |
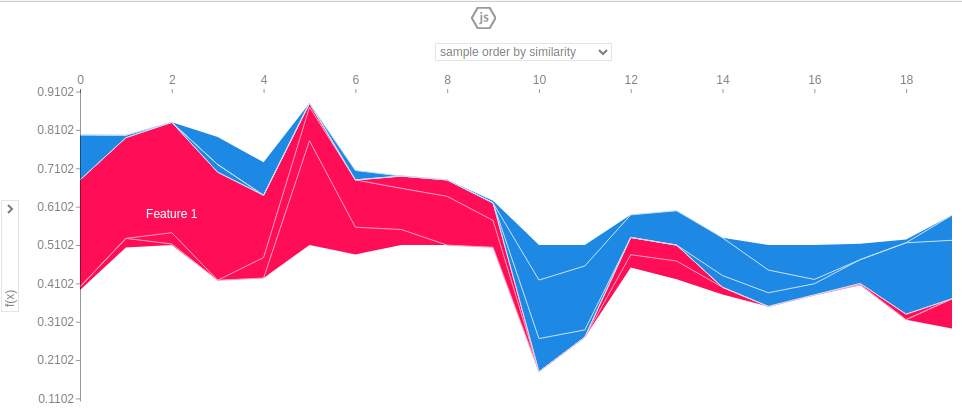
Il est également possible d’examiner l’impact d’une caractéristique spécifique :
# Need to initialize javascript in order to display the plots shap.initjs() # View impact shap.plots.force(explainer.expected_value[0], shap_values[0]) |
Pour conclure
SHAP (SHapley Additive exPlanations) est un outil puissant et polyvalent pour l’interprétabilité des modèles de Machine Learning. En s’appuyant sur les principes de la théorie des jeux coopératifs et de la Valeur de Shapley, il offre une méthode rigoureuse pour décomposer et comprendre les contributions des caractéristiques individuelles dans les prédictions d’un modèle.
L’utilisation de la bibliothèque SHAP en Python démontre sa facilité d’intégration et de mise en œuvre dans le workflow de data science. De plus, avec une Intelligence Artificielle devenant de plus en plus omniprésente, l’interprétabilité des modèles ne peut pas se permettre d’être sous-estimée.




