Nous entendons tous parler du terme « Machine Learning », qui peut se décomposer en trois grandes catégories :
- L’apprentissage supervisé
- L’apprentissage non supervisé
- L’apprentissage par renforcement
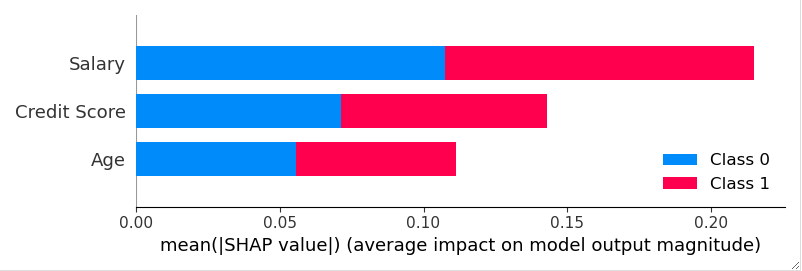
En apprentissage supervisé, un programme informatique reçoit un ensemble de données qui est étiqueté avec des valeurs de sorties correspondantes, ainsi on pourra alors « s’entrainer » sur ce modèle et une fonction sera déterminée. Cette fonction, ou algorithme pourra par la suite être utilisé sur de nouvelles données afin de prédire leurs valeurs de sorties correspondantes. C’est le cas par exemple de la Régression Linéaire, des Arbres de décisions, SVM (Support Vector Machine)…
En voici une illustration :
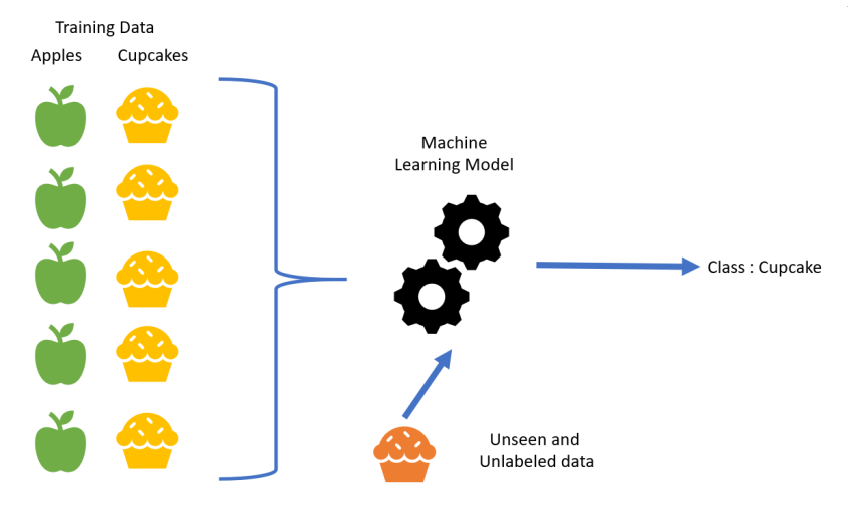
Pour l’Homme, il s’agit du même principe. De par son expérience, il va mémoriser une grande quantité d’informations et face à une situation, il va pouvoir se remémorer une situation similaire et émettre une conclusion.
Dans l’apprentissage non-supervisé, l’ensemble des données n’a pas de valeurs de sorties spécifiques. Puisqu’il n’y a pas de bonnes réponses à tirer, l’objectif de l’algorithme est donc de trouver lui-même tous les modèles intéressants à partir des données. Certains des exemples bien connus d’apprentissage non supervisé comprennent les algorithmes de Clustering comme KMeans, DB-Scan et de réduction de dimension comme l’ACP (Analyse en Composantes Principales) et les réseaux de neurones.
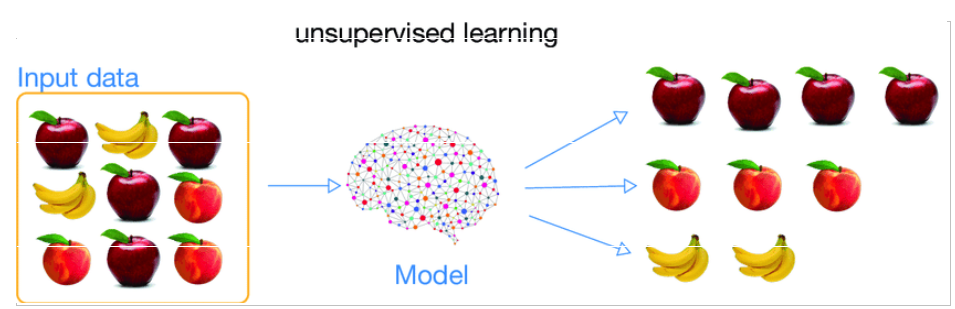
Chez l’Homme, le principe est le même, certains critères vous nous permettre de différencier ce que se présente sous yeux et donc de déterminer différentes classes.
Dans l’apprentissage par renforcement, les « bonnes réponses » contiennent des récompenses, que l’algorithme doit maximiser en choisissant les actions à prendre.
Essentiellement, l’apprentissage par renforcement consiste à trouver le bon équilibre entre l’exploration et l’exploitation, ou l’exploration ouvre la possibilité de trouver des récompenses plus élevées, ou risque de n’obtenir aucunes récompenses. Les jeux tels que les Dames sont basés sur ce principe.
Le psychologue BF Skinner (1938), a observé le même résultat au cours d’une expérience sur les rats ou un levier offrait une récompense tandis qu’un autre administrait un choc. Le constat est simple, la punition a entrainé une diminution de la pression du levier de choc.
En comparant le Machine Learning à l’apprentissage d’un Humain, on observe donc beaucoup de similitude mais évidemment, il existe encore des différences fondamentales entre les deux :
Bien que les algorithmes d’apprentissage supervisé fournissent un aperçu complet de l’environnement, ils nécessitent une grande quantité de données pour que le modèle soit construit, ce qui peut être un peu lourd en termes de calculs.
A l’inverse, l’Homme a besoin de beaucoup moins de données pour être capable de faire des prédictions notamment en extrapolant les concepts qu’il a en mémoire. Le Machine Learning lui ne pourra pas le faire car les programmes n’interprètent pas des concepts mais des données.
Un autre problème survient quand on parle de sur-apprentissage ou « Overfitting » en anglais, qui se produit lorsque les données d’apprentissage utilisées pour construire un modèle expliquent très voire « trop » bien les données mais ne parviennent pas à faire des prédictions utiles pour de nouvelles données. L’Homme aura donc plus de flexibilité dans son raisonnement alors que les algorithmes de Machine Learning seront eux plus rigides.
En conclusion, le Machine Learning a souvent été comparé au raisonnement Humain, même si les deux ne sont pas exactement les mêmes.
Chez l’Homme, l’apprentissage a été façonné par des processus évolutifs pour devenir ce qu’il est aujourd’hui. Bien que de nombreuses théories ont tenté de d’expliquer ses mécanismes, sa nature dynamique conduit à dire que différentes stratégies peuvent être utilisées simultanément ou séparément, selon la situation. Il est donc difficile de le comparer au Machine Learning. Après tout, le Machine Learning a été programme par les humains… ainsi, de nouveaux concepts verront le jour pour pouvoir sans cesse améliorer nos algorithmes d’apprentissage qui sont déjà très efficace pour la prise de décision sur de large bases de données. Une Machine dotée d’une conscience ne verra sans doute jamais le jour, mais d’ici peu, la capacité de prise de décision des automates supplantera celle des humains dans quasiment tous les domaines