Les APIs permettent de connecter Power BI à des sources de données externes. Découvrez tout ce que vous devez savoir sur ces interfaces, et comment maîtriser la plateforme de Microsoft.
Il existe plusieurs façons d’assembler les données pour les rapports Power BI. Outre les fichiers Excel et les bases de données sur site ou sur le cloud, les APIs sont de plus en plus utilisées.
De nombreuses organisations fournissent des données par le biais d’APIs, dont les agences gouvernementales, les entreprises de médias, les fournisseurs de services logiciels ou même les ONG.
Ces outils peuvent aussi être utilisés en interne par les entreprises souhaitant intégrer des données entre de multiples systèmes. C’est l’un des cas d’usage les plus courants de Power BI et autres plateformes de reporting.
Même si la source de données principale d’un rapport est généralement interne, comme une Data Warehouse, il est possible d’enrichir les données existantes grâce à une API.
Il peut s’agir par exemple de données économiques et démographiques de la Banque Mondiale, des données des réseaux sociaux, des taux d’échange actuels ou même d’informations sur Wikipedia. Il existe de nombreuses APIs permettant d’obtenir de telles données.
Qu’est-ce que Power BI ?
Power BI est la plateforme de Business Intelligence de Microsoft. Cet outil self-service permet à tous les employés d’une entreprise d’analyser et de visualiser les données.
Il s’agit d’une suite logicielle regroupant plusieurs composants pour la collecte, l’analyse et la visualisation de données, le reporting et la création de tableaux de bord.
Les avantages de Power BI sont une interface intuitive, une accessibilité sur PC, mobile et cloud, et une connectivité avec de nombreux logiciels et sources de données.
Qu’est-ce qu’une API ?
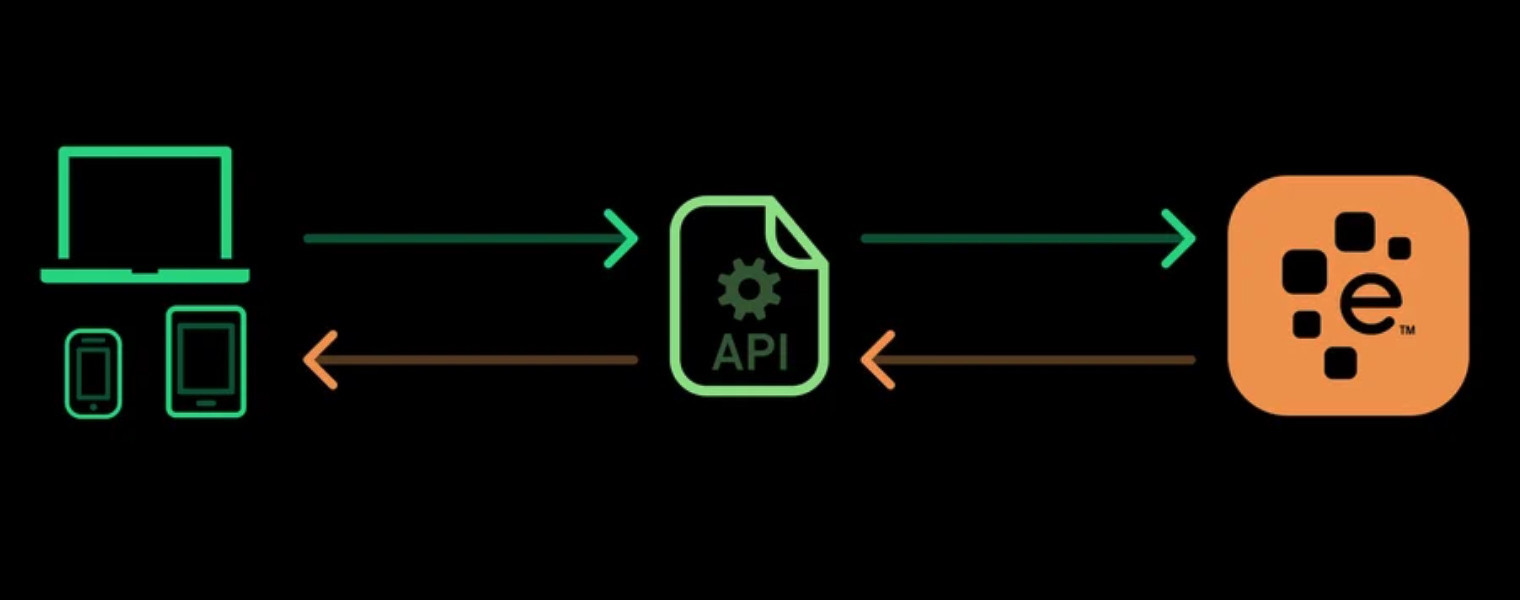
Le terme API est l’acronyme de « Application Programming Interface ». Il existe une large diversité d’APIs dans le domaine de l’informatique.
Différentes technologies permettent de délivrer les APIs, comme REST et SOAP. Chacun a ses propres mécanismes et capacités, et peut retourner les données dans différents formats comme JSON ou XML.
Heureusement, chaque API s’accompagne d’une documentation détaillant son fonctionnement. Elle indique notamment les définitions, les valeurs de requêtes autorisées, les limitations, des exemples d’usage et les formats de données.
Les APIs gratuites et publiques ne requièrent aucune authentification, mais les APIs privées et commerciales peuvent exiger une clé ou un mot de passe.
Les APIs de données web comme celle de Wikipedia permettent d’effectuer une requête en entrant une simple adresse URL dans un navigateur web.
Qu’est-ce qu’une API REST ?
Une API REST est un style d’architecture logicielle conçue pour guider le développement et le design de l’architecture du World Wide Web. Elle définit un ensemble de contraintes pour la façon dont l’architecture système doit se comporter.
Les APIs REST offrent une façon flexible et légère d’intégrer les applications. Elles permettent d’effectuer des recherches en envoyant des requêtes à un service, et renvoient des résultats en provenance de celui-ci.
Les éléments composant l’API Rest sont les headers indiquant le mode d’authentification et les types de contenu, la méthode d’appel telle que POST et GET, le endpoint sous forme d’URL et les données textuelles au format JSON.
Pour accéder à la REST API de Power BI, il est nécessaire de demander au préalable un token avec lequel vous pourrez appeler l’API et exécuter les fonctions.
À quoi sert la REST API de Power BI ?
La REST API de Power PI délivre des endpoints de service pour l’intégration, l’administration, la gouvernance ou les ressources utilisateurs. Elle permet d’organiser le contenu Power BI, d’exécuter des opérations administratives ou encore d’intégrer du contenu en provenance de Power BI.

Maîtriser la REST API de Power BI
Son avantage est de permettre de construire des applications personnalisées délivrant les données sur un tableau de bord Power BI à l’aide d’un accès programmatique aux composants du tableau de bord : datasets, tableaux, lignes…
Elle permet de créer, d’obtenir ou de modifier des ensembles de données, des tableaux, des couloirs, des groupes, ou encore des tableaux de bord. Voici comment procéder pour établir une connexion entre Power BI et une source de données via la REST API.
La première étape est d’enregistrer une application à partir du Portail Développeur de Power BI. Vous devez ensuite conférer à l’utilisateur l’autorisation d’accéder à l’application, et générer un token d’accès à l’aide de la méthode POST.
Par la suite, vous pouvez utiliser la REST API de Power BI pour assembler les données dont vous avez besoin. Il peut s’agir par exemple d’une liste de rapports ou d’ensembles de données en provenance de votre espace de travail personnel.
Qu’est-ce que la DAX REST API de Power BI ?
Depuis le mois d’août 2021, la nouvelle API REST de Power BI permet d’effectuer des requêtes de datasets en utilisant le langage DAX. Cette API REST DAX évite les dépendances aux librairies client Analysis Services, et ne requiert pas de connexion aux endpoints XMLA.
Il est possible dans presque n’importe quel environnement de développement moderne et sur n’importe quelle plateforme dont les applications no-code Power Apps, les langages basés JavaScript ou le langage Python. Toute technologie permettant l’authentification avec Azure Active Directory et la construction d’une requête web est compatible.
Qu’est-ce que la Client API de Power BI ?
L’API Client de Power BI est une librairie client side permettant de contrôler programmatiquement le contenu intégré Power BI en utilisant JavaScript ou TypeScript.
Cette API permet la communication entre les éléments de Power BI tels que les rapports et les tableaux de bord, et le code d’application. Ainsi, vous pouvez concevoir une expérience utilisateur selon votre propre design.

Comment connecter Power BI à une API ?
La connexion entre Power BI est une API nécessite d’utiliser un connecteur de source de données web. On entre ensuite le endpoint de l’API et ses paramètres en guise d’URL.
Après avoir fourni les détails d’authentification requis par l’API, il ne reste qu’à formater les résultats de la requête dans un format de tableau pouvant être intégré au modèle Power BI.
Par défaut, Power BI essayera automatiquement de convertir les résultats JSON vers un format de tableau. Le format XML requiert un peu plus d’efforts, et les étapes spécifiques peuvent varier.
Comment apprendre à manier Power BI ?
Une connexion API apporte de nombreux avantages pour le reporting sur Power BI. Elle peut notamment permettre d’enrichir les données grâce à des sources externes, ou fournir une façon plus flexible de connecter ses données au cloud. Il existe de nombreuses APIs disponibles gratuitement sur le web.
Toutefois, pour maîtriser Power BI et toutes ses fonctionnalités, vous pouvez choisir DataScientest. Nous proposons une formation Power BI permettant à un débutant d’acquérir la maîtrise complète de l’outil en seulement cinq jours.
Notre cursus s’effectue intégralement à distance, via internet. En tant que Microsoft Learning Partner, DataScientest vous permet d’obtenir la certification PL-300 Power BI Data Analyst Associate à la fin du parcours.
Pour le financement, notre organisme est reconnu par l’Etat est éligible au Compte Personnel de Formation. N’attendez plus, et découvrez DataScientest !
Découvrir la formation Power BI
Vous savez tout sur Power BI et les APIs. Pour plus d’informations sur le même sujet, découvrez notre dossier complet sur Power BI et notre dossier sur la Business Intelligence.