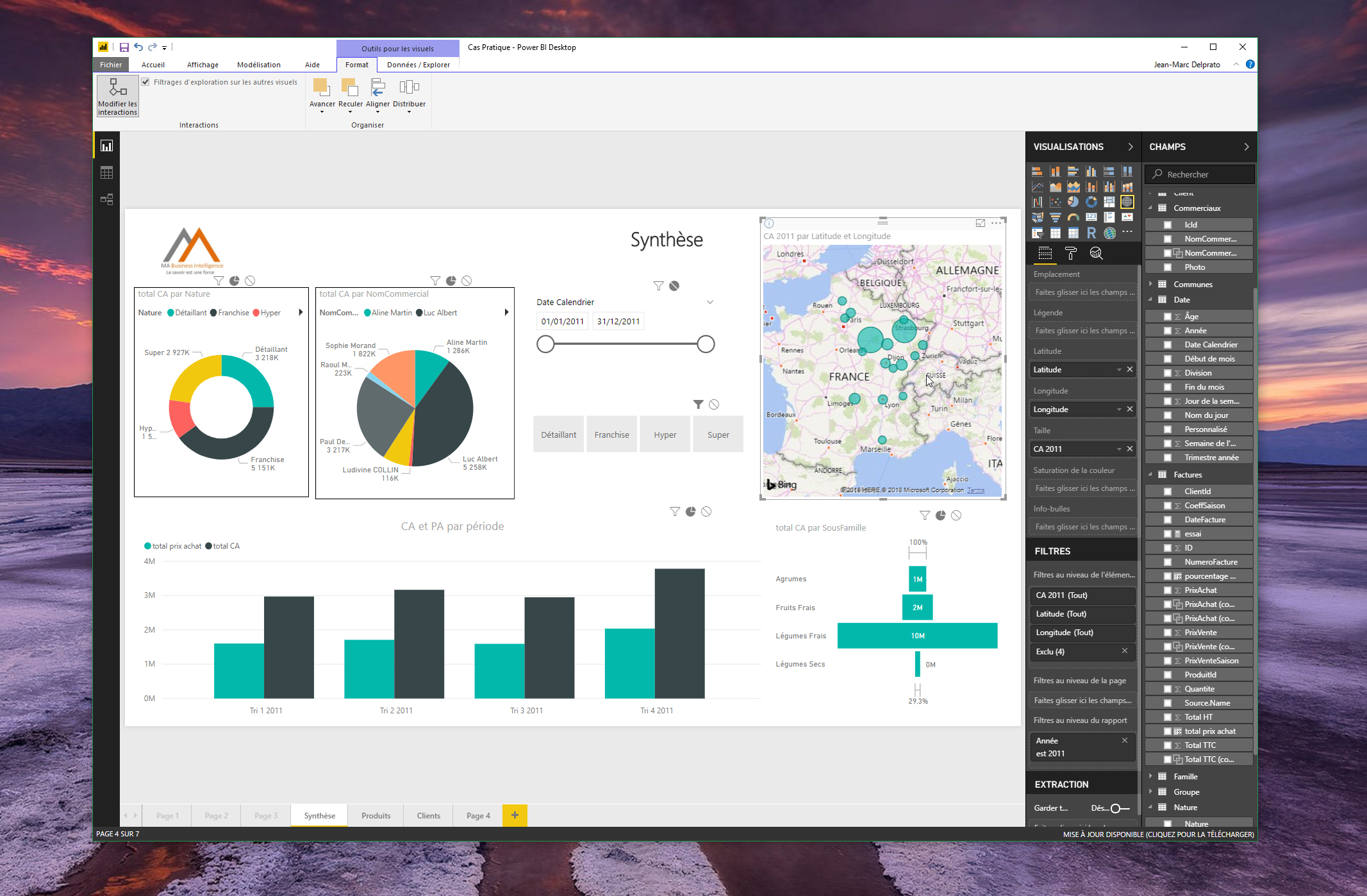
La bibliothèque Pandas est certainement la plus utile pour les data scientist sous le langage Python. Elle permet d’explorer, transformer, visualiser et comprendre vos données afin d’en retirer le maximum d’informations. Voyons ensemble dans quelles cas l’utiliser et ses fonctions les plus courantes.
Si vous évoluez dans la data science, vous avez sûrement entendu parler de la bibliothèque Pandas. Son nom n’a rien à voir avec ce petit animal d’Asie qui ressemble à un ours. Le nom «Pandas» est une contraction des mots «Panel Data» et «Python Data Analysis». Pandas est donc une bibliothèque open-source proposant différentes fonctions qui permettent la manipulation et l’analyse de données en Python de manière simple et intuitive. C’est donc une bibliothèque polyvalente qui vous permettra de réaliser facilement des analyses de données complexes. La bibliothèque Pandas permet également de créer facilement des graphes, très utiles dans la Data Analyse.
Première force de Pandas, elle se base sur la bibliothèque Numpy
Grand avantage de Pandas, elle se base sur la très populaire bibliothèque Numpy. Cette bibliothèque fournit une pléiade de structures de données et d’opérations qui permettent de traiter des données numériques et des données chronologiques. La bibliothèque Pandas est également importante car ses données sont souvent utilisées comme base pour les fonctions de plotting de Matplotlib, une autre bibliothèque renommée utilisant le langage Python. Les données issues de Pandas sont aussi très utiles dans l’analyse statistique en SciPy, les algorithmes de Machine Learning en Scikit-learn. La bibliothèque Pandas est également très utilisée dans le traitement et l’analyse des données tabulaires (vous pourrez stocker vos données sous le format .csv, .tsv et .xlsx) en entrant des requêtes de type SQL.
Les Séries, les Dataframes et le Panel : les principales structures de données de Python Panda
Si vous utilisez Pandas, vous travaillerez principalement avec deux structures de données, les Séries et les Dataframes.
Les Séries : Une Série est un tableau unidimensionnel étiqueté qui peut contenir des données de n’importe quel type (entier, chaîne, flottant, objets python, etc.). En d’autres mots, les séries sont équivalentes aux colonnes dans un tableau Excel. Les étiquettes des axes sont collectivement appelées index.
Pandas en général est utilisé pour les données de séries chronologiques financières ou des données économiques. Ce langage dispose de nombreux assistants intégrés pour gérer les données financières. Grâce à Numpy, vous pourrez facilement gérer de grands tableaux multidimensionnels pour le calcul scientifique.

- charger des données provenant de différentes sources.
- réaliser facilement des statistiques et calculer la moyenne, la médiane, le maximum et le minimum de chaque colonne et les corrélations entre chacune d’entre elles.
- nettoyer facilement les données en supprimant les valeurs manquantes ou en filtrant les lignes ou les colonnes selon certains critères.
- visualiser les données avec l’aide de Matplotlib. Tracez des barres, des lignes, des histogrammes, des bulles, etc.
- elle permet de stocker les données nettoyées et transformées dans un CSV, TSV ou XLSX.
La Dataframe vous permet également de créer vos propres fonctions Python pour effectuer certaines tâches de calcul et les appliquer aux données de vos Dataframes.
En utilisant les Séries et les Dataframes on peut donc facilement manipuler des données et les représenter.
Enfin, le Panel est un conteneur important pour les données en 3 dimensions. Les noms des 3 axes sont destinés à décrire les opérations impliquant des données de panel et, en particulier, l’analyse économétrique de ces données. L’analyse économétrique est une analyse quantitative, permettant de vérifier l’existence de certaines relations entre des phénomènes économiques et de mesurer concrètement ces relations sur la base d’observations de faits réels. On peut par exemple observer les notes des élèves d’une classe et les comparer sur les devoirs rendus durant les trois trimestres d’une année scolaire.
Pandas, un langage essentiel en Data Science et en Machine Learning
Pandas est un outil particulièrement populaire en science des données il est particulièrement reconnu pour le traitement et l’analyse des données. En effet, Pandas est très utile dans le nettoyage, la transformation, la manipulation et l’analyse de données. En d’autres mots, Pandas aide les Data Scientists à mettre de l’ordre dans leurs données ce qui représente selon certains près de 80% de leur travail.
En ce qui concerne le Machine Learning, Pandas est tout aussi reconnu comme un outil de choix. Ces fonctions permettent notamment d’explorer, de transformer mais aussi de créer une visualisation de la donnée.
En effet, Pandas est souvent accompagné de la bibliothèque Scikit-learn, c’est le package de machine learning de Python. L’utilisation de Scikit-learn intervient dans un deuxième temps après le passage de Pandas dans la première phase d’exploration de la donnée dans un projet de Data Science.