Il y a beaucoup de discussions sur ce qu’est la Data Science ou Science des données. Mais, nous pouvons la résumer par la phrase suivante : « La Data Science est la discipline du 21e siècle qui convertit les données en connaissances utiles ».
La Data Science combine plusieurs domaines, dont les statistiques, les méthodes scientifiques (scientific methods) et l’analyse des données (analyzing data). Elle permet d’extraire de la valeur dans les données, de la collecte de celles-ci (Data Collections) à l’analyse prédictive (Predictive Analytics) en passant par la présentation des résultats (Data Visualization). Le praticien de la Science des données est le Data Scientist qui travaille de près avec d’autres experts du Big Data tels que le Data Analyst et le Data Engineer (Data Science Team).
Qu’est-ce que la Data Science ?
En termes simples, la Science des données consiste à appliquer l’analyse prédictive pour tirer le meilleur parti des informations d’une entreprise. Il ne s’agit pas d’un produit, mais d’un ensemble d’outils (parfois Open source) et de techniques interdisciplinaires intégrant les statistiques (statistical analysis et statistical modeling), l’informatique (computer science) et les technologies de pointe (Artificial Intelligence AI et Machine Learning models) qui aident le Data Scientist à transformer les données en informations stratégiques (actionable insights).
La plupart des entreprises sont aujourd’hui submergées de données et ne les utilisent probablement pas à leur plein potentiel. C’est là qu’intervient le Data Scientist qui met à leur service ses compétences uniques en matière de Science des données pour les aider à transformer les informations en données stratégiques significatives et en véritable avantage concurrentiel (Data Driven Marketing).
En appliquant la Data Science, une organisation peut prendre des décisions en toute confiance et agir en conséquence, car elle travaille avec des faits et la méthode scientifique, plutôt qu’avec des intuitions et des suppositions.
Que font exactement les Data Scientists ?
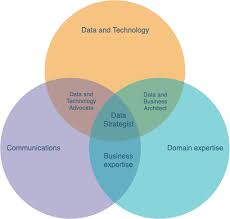
Les Data Scientists sont des experts dans trois groupes de disciplines :
– Les statistiques et les mathématiques appliquées
– L’informatique
– L’expertise commerciale
Si les Scientifiques des données peuvent avoir une expertise en physique, en ingénierie, en mathématiques et dans d’autres domaines techniques ou scientifiques, ils doivent également comprendre les objectifs stratégiques de l’entreprise pour laquelle ils travaillent afin d’offrir de réels avantages commerciaux.
Le travail quotidien d’un Data Scientist consiste à :
– Définir un problème ou une opportunité commerciale
– Gérer et à analyser toutes les données pertinentes pour le problème
– Construire et tester des modèles pour fournir des aperçus et des prédictions
– Présenter les résultats aux parties prenantes de l’entreprise
– Écrire du code informatique pour exécuter la solution choisie
Lorsqu’il fait du codage, il applique ses connaissances d’une combinaison de langages utilisés pour la gestion des données et l’analyse prédictive tels que Python, R, SAS et SQL/PostgreSQL.
Enfin, le Data Scientist est également chargé d’analyser et de communiquer les résultats commerciaux réels.
En raison du grand nombre de compétences spécifiques impliquées, les scientifiques de données qualifiés sont difficiles à identifier et à recruter. En outre, leur maintien au sein d’une équipe interne est coûteux pour une organisation.
Pourquoi la Data Science est-elle soudainement si importante ?
La théorie mathématique et statistique qui sous-tend la Data Science est importante depuis des décennies. Mais, les tendances technologiques récentes ont permis la mise en œuvre industrielle de ce qui n’était auparavant que de la théorie. Ces tendances font naître un nouveau niveau de demande pour la Science des données et un niveau d’excitation sans précédent quant à ce qu’elle peut accomplir :
– L’essor du Big Data et de l’Internet des objets (IoT)
La transformation numérique du monde des affaires a donné lieu à une énorme quantité de données (amounts of data) et différents jeux de données (data sets) sur les clients, les concurrents, les tendances du marché et d’autres facteurs clés. Comme ces données proviennent de nombreuses sources et peuvent être non structurées, leur gestion est un défi. Il est difficile, voire impossible pour les groupes internes (analystes d’entreprise traditionnels et équipes informatiques travaillant avec les systèmes existants) de gérer et d’appliquer cette technologie par eux-mêmes.
– La nouvelle accessibilité de l’Intelligence artificielle (IA)
L’Artificial Intelligence (Intelligence artificielle) et la Machine Learning (apprentissage automatique) qui relevaient autrefois de la science-fiction sont désormais monnaie courante et arrivent juste à temps pour relever le défi du Big Data. Le volume, la variété et la vitesse des données ayant augmenté de manière exponentielle, la capacité à détecter des modèles et à faire des prédictions dépasse la capacité de la cognition humaine et des techniques statistiques traditionnelles. Aujourd’hui, l’Intelligence artificielle et l’apprentissage automatique sont nécessaires pour effectuer des tâches robustes de classification, d’analyse et de prédiction des données.
– Les gains énormes en puissance de calcul
La Data Science ne serait pas possible sans les récentes améliorations majeures de la puissance de calcul. Une percée cruciale a été de découvrir que les processeurs informatiques conçus pour restituer des images dans les jeux vidéos seraient également adaptés aux applications d’apprentissage automatique et d’Intelligence artificielle. Ces puces informatiques avancées sont capables de gérer des algorithmes mathématiques et statistiques extrêmement sophistiqués et fournissent des résultats rapides même pour les défis les plus complexes, ce qui les rend idéales pour les applications de science des données.
– Nouvelles techniques de stockage des données, y compris l’informatique dématérialisée
La Data Science dépend d’une capacité accrue à stocker des données de toutes sortes à un coût raisonnable. Les entreprises peuvent désormais stocker raisonnablement des pétaoctets (ou des millions de gigaoctets) de données, qu’elles soient internes ou externes, structurées ou non structurées, grâce à une combinaison hybride de stockage sur site et en nuage.
– Intégration de systèmes
La Data Science met en relation toutes les parties de votre organisation. Une intégration étroite et rapide des systèmes est donc essentielle. Les technologies et systèmes conçus pour déplacer les données en temps réel doivent s’intégrer de manière transparente aux capacités de modélisation automatisée qui exploitent les algorithmes de Machine Learning pour prédire un résultat. Les résultats doivent ensuite être communiqués aux applications en contact avec la clientèle, avec peu ou pas de latence, afin d’en tirer un avantage.
Quels avantages une entreprise peut-elle tirer de la Data Science ?

La Data Science peut offrir un large éventail de résultats financiers et d’avantages stratégiques, en fonction du type d’entreprise, de ses défis spécifiques et de ses objectifs stratégiques.
Par exemple, une société de services publics pourrait optimiser un réseau intelligent pour réduire la consommation d’énergie en s’appuyant sur des modèles d’utilisation et de coûts en temps réel. Un détaillant pourrait appliquer la Science des données aux informations du point de vente pour prédire les achats futurs et sélectionner des produits personnalisés.
Les constructeurs automobiles utilisent activement la Data Science pour recueillir des informations sur la conduite dans le monde réel et développer des systèmes autonomes grâce à la Machine Learning. Les fabricants industriels utilisent la Science des données pour réduire les déchets et augmenter le temps de fonctionnement des équipements.
Dans l’ensemble, la Data Science et l’Intelligence artificielle sont à l’origine des avancées en matière d’analyse de texte, de reconnaissance d’images et de traitement du langage naturel qui stimulent les innovations dans tous les secteurs.
La Science des données peut améliorer de manière significative les performances dans presque tous les domaines d’une entreprise de ces manières, entre autres :
– Optimisation de la chaîne d’approvisionnement
– Augmentation de la rétention des employés
– Compréhension et satisfaction des besoins des clients
– Prévision avec précision des paramètres commerciaux
– Suivi et amélioration de la conception et des performances des produits.
La question n’est pas de savoir ce que la Data Science peut faire. Une question plus juste serait de savoir ce qu’il ne peut pas faire. Une entreprise dispose déjà d’énormes volumes d’informations stockées ainsi que d’un accès à des flux de données externes essentiels. La Science des données peut tirer parti de toutes ces informations pour améliorer pratiquement tous les aspects des performances d’une organisation, y compris ses résultats financiers à long terme.
Quel est l’avenir de la Data Science ?
La Data Science est de plus en plus automatisée et le rythme de l’automatisation va sûrement se poursuivre.
Historiquement, les statisticiens devaient concevoir et ajuster les modèles statistiques manuellement sur une longue période, en utilisant une combinaison d’expertise statistique et de créativité humaine. Mais aujourd’hui, alors que les volumes de données et la complexité des problèmes d’entreprise augmentent, ce type de tâche est si complexe qu’il doit être traité par l’Intelligence artificielle, l’apprentissage automatique et l’automatisation. Cette tendance se poursuivra à mesure que le Big Data prendra de l’ampleur.
L’Intelligence artificielle et l’apprentissage automatique sont souvent associés à l’élimination des travailleurs humains. Mais, ils ne font en réalité qu’accroître l’essor des Citizen Data Scientists, ces professionnels de la Data Science sans formation formelle en mathématiques et statistiques.
En conclusion, rien n’indique que l’automatisation remplacera les spécialistes des données, les ingénieurs de données et les professionnels des DataOps qualifiés. Il faut autant de créativité humaine que possible à différentes étapes pour tirer parti de toute la puissance de l’automatisation et de l’Intelligence artificielle.