La data science ou science des données est une science appliquée. Elle fait appel à des méthodes et des connaissances issues de nombreux domaines tels que les mathématiques, les statistiques et l’informatique, notamment la programmation informatique. Depuis le début de ce millénaire, la data science est une discipline indépendante.
Il existe des cours spécifiques pour la science des données. Les personnes travaillant dans ce domaine sont connues sous le nom de data scientists ou scientifiques des données. Tout mathématicien, informaticien, programmeur, physicien, économiste d’entreprise ou statisticien qui a acquis ses connaissances en se spécialisant dans les tâches de science des données peut devenir un data scientist.
Le but de la data science est de générer des connaissances à partir de données. Dans l’environnement Big Data, la science des données est utilisée pour analyser des ensembles de données en grandes quantités avec l’apprentissage automatique (machine learning) et l’intelligence artificielle (IA). La science des données est utilisée dans diverses industries et domaines spécialisés.
Pour faire simple, les objectifs de la data science sont de :
Établir un moteur de recommandation à partir des données clients (sur le site, sur les réseaux sociaux…)
Aujourd’hui, les moteurs de recommandation de produits sont capables de rencontrer un client en temps réel. Par exemple, les magasins qui utilisent les recommandations de produits ont la possibilité de personnaliser chacune de leurs pages. Sur chacune d’elles, ils proposent des offres qui attirent le client de la page d’accueil à la page de paiement.
Fournir une aide à la décision
La prise de décision basée sur les données est définie comme l’utilisation de faits, de mesures et de données. Il est ainsi possible de guider les parties prenantes dans une entreprise à prendre des décisions stratégiques. Lorsqu’une organisation tire pleinement parti de la valeur de ses données, tous ceux qui y travaillent ont la capacité de prendre de meilleures décisions.
Optimiser et automatiser les processus internes
Les entreprises cherchent constamment à simplifier les tâches. Elles veulent également réduire les coûts. Cela est possible grâce à la data science. Il peut être aussi optimisé afin de gagner en efficacité et en compétitivité.
Soutenir les parties prenantes dans la gestion de l’entreprise
Outre l’aide à la prise de décision, la data science permet de recouper des données pertinentes pour apporter des éléments concrets. Sur ces derniers, les différents responsables d’une entreprise pourront baser leurs actions.
De développer des modèles prédictifs
Par le biais de l’analyse prédictive, la data science permet de prédire les événements futurs. En règle générale, les données sont utilisées pour créer un modèle mathématique afin de détecter les tendances les plus importantes. Ce modèle prédictif est ensuite appliqué aux données actuelles pour prédire les événements futurs ou suggérer des mesures à prendre pour obtenir des résultats optimaux.
La data science est une science interdisciplinaire qui utilise et applique des connaissances et des méthodes provenant de divers domaines. Les mathématiques et les statistiques constituent l’essentiel de ces connaissances. Ce sont les bases permettant au data scientist d’évaluer les données, de les interpréter, de décrire les faits ou de faire des prévisions. Dans le cadre de l’analyse prédictive, les statistiques inductives sont souvent utilisées en plus d’autres méthodes statistiques pour anticiper les événements futurs.
Un autre groupe de connaissances appliquées dans la science des données est la technologie de l’information et l’informatique. La technologie de l’information fournit des processus et des systèmes techniques de collecte, d’agrégation, de stockage et d’analyse des données. Les éléments importants dans ce domaine sont les bases de données relationnelles, les langages de requête de bases de données structurées tels que SQL (Structured Query Language), le langage de programmation et de script sur des outils tels que Python et bien plus encore.
En plus des connaissances scientifiques spécifiques, la data science accède à ce que l’on appelle la connaissance de l’entreprise (connaissance du domaine ou savoir-faire de l’entreprise). Elle est nécessaire pour comprendre les processus dans une organisation particulière ou une entreprise d’un secteur spécifique. La connaissance du domaine peut concerner des compétences commerciales : marketing de produits et services, savoir-faire logistique, expertise médicale.
La relation entre le Big Data et la data science
En raison de l’augmentation continuelle des volumes de données à traiter ou à analyser, le terme Big Data s’est imposé. Le Big Data est au cœur du traitement des données. Il concerne les méthodes, procédures, solutions techniques et systèmes informatiques. Ceux-ci sont capables de faire face au flux de données et au traitement de grandes quantités de données sous la forme souhaitée.
Le Big Data est un domaine important de la data science. La science des données fournit des connaissances et des méthodes pour collecter et stocker de nombreuses données structurées ou non structurées (par exemple dans un data lake ou lac de données), les traiter à l’aide de processus automatisés et les analyser. La science des données utilise, entre autres, l’exploration de données ou data mining, l’apprentissage statistique, l’apprentissage automatique (machine learning), l’apprentissage en profondeur (deep learning) et l’intelligence artificielle (IA).
Les personnes impliquées dans la science des données sont les scientifiques des données ou data scientists. Ils acquièrent leurs compétences soit en suivant une formation en data science, soit en se spécialisant dans le métier de data scientist.
Les scientifiques des données sont souvent des informaticiens, des mathématiciens ou des statisticiens. Ils sont également des programmeurs, des experts en bases de données ou des physiciens qui ont reçu une formation complémentaire en science des données.
En plus des connaissances spécifiques, un data scientist doit être en mesure de présenter clairement les modèles. Il les génère à partir des données et de les rapprocher de divers groupes cibles. Il doit également avoir des compétences appropriées en communication et en présentation. En effet, un data scientist a un rôle de conseiller ou de consultant auprès de la direction d’une entreprise. Les termes data scientist et data analyst sont souvent confondus dans l’environnement d’une entreprise. Parfois, leurs tâches et domaines d’activité se chevauchent.
L’analyste de données effectue une visualisation de données classique et pratique. De son côté, le data scientist poursuit une approche plus scientifique. Pour ce faire, il utilise des méthodes sophistiquées comme l’utilisation de l’intelligence artificielle ou de l’apprentissage automatique et des techniques avancées d’analyse et de prédiction.
Domaines d’application de la data science
Il n’y a pratiquement pas de limites aux applications possibles de la science des données. L’utilisation de la data science est logique partout où de grandes quantités de données sont générées et que des décisions doivent être prises sur la base de ces données. La science des données est d’une grande importance dans certains entreprises et activités : santé, logistique, vente au détail en ligne et en magasin, assurance, finance, industrie et manufacturing.
Avec l’essor des technologies numériques, la collecte et la gestion de données sont devenues des enjeux économiques stratégiques pour de nombreuses entreprises. Ces pratiques ont engendrées la naissance d’un tout nouveau secteur et de nouveaux emplois : la Data science.
IBM prévoyait une hausse de 28 % de la demande de profil Data Scientist en 2020. En effet, de nombreuses entreprises ont compris l’importance stratégique de l’exploitation de la donnée. La Data science étant au cœur de la chaîne d’exploitation de la donnée, cela explique la hausse de la demande des profils compétents dans ce domaine.
Tour d’horizon de la Data science
La Data science, ou science de la donnée, est le processus qui consiste à utiliser des algorithmes, des méthodes et des systèmes pour extraire des informations stratégiques à l’aide des données disponibles. Elle utilise l’analyse des données et le machine learning(soit l’utilisation d’algorithmes permettant à des programmes informatiques de s’améliorer automatiquement par le biais de l’expérience) pour aider les utilisateurs à faire des prévisions, à renforcer l’optimisation, ou encore à améliorer les opérations et la prise de décision.
Les équipes actuelles de professionnels de la science de la donnée sont censées répondre à de nombreuses questions. Leur entreprise exige, le plus souvent, une meilleure prévision et une optimisation basée sur des informations en temps réel appuyées par des outils spécifiques.
La science de la donnée est donc un domaine interdisciplinaire qui connaît une évolution rapide. De nombreuses entreprises ont largement adopté les méthodes de machine learning et d’intelligence artificielle (soit l’ensemble des techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine) pour alimenter de nombreuses applications. Les systèmes et l’ingénierie des données font inévitablement partie de toutes ces applications et décisions à grande échelle axées sur les données. Cela est dû au fait que les méthodes citées plus tôt sont alimentées par des collections massives d’ensembles de données potentiellement hétérogènes et désordonnées et qui, à ce titre, doivent être gérés et manipulés dans le cadre du cycle de vie global des données d’une organisation.
Ce cycle de vie global en data science commence par la collecte de données à partir de sources pertinentes, le nettoyage et la mise en forme de celles-ci dans des formats que les outils peuvent comprendre. Au cours de la phase suivante, des méthodes statistiques et d’autres algorithmes sont utilisés pour trouver des modèles et des tendances. Les modèles sont ensuite programmés et créés pour prédire et prévoir. Enfin, les résultats sont interprétés.
Pourquoi choisir l’organisme DataScientest pour se former en Data science ?
Vous êtes maintenant convaincu de l’importance de la maîtrise de la Data science pour renforcer votre profil employable et pour aider votre entreprise.
Les formations en Data Science de l’organisme DataScientest sont conçues pour former et familiariser les professionnels avec les technologies clés dans ce domaine, dans le but de leur permettre de profiter pleinement des opportunités offertes par la science de la donnée et de devenir des acteurs actifs dans ce domaine de compétences au sein de leurs organisations.
Ces formations, co-certifiées par la Sorbonne, ont pour ambition de permettre, à toute personne souhaitant valoriser la manne de données mise actuellement à sa disposition, d’acquérir un véritable savoir-faire opérationnel et une très bonne maîtrise des techniques d’analyse de données et des outils informatiques nécessaires.
L’objectif que se fixe DataScientest est de vous sensibiliser en tant que futurs décideurs des projets data, aux fortes problématiques des données à la fois sous l’angle technique (collecte, intégration, modélisation, visualisation) et sous l’angle managérial avec une compréhension globale des enjeux.
Pourquoi choisir la formule « formation continue » chez Datascientest ?
Pendant 6 mois, vous serez formés à devenir un(e) expert(e) en data science, en maîtrisant les fondements théoriques, les bonnes pratiques de programmation et les enjeux des projets de data science.
Vous serez capable d’accompagner toutes les étapes d’un projet de data science, depuis l’analyse exploratoire et la visualisation de données à l’industrialisation d’outils d’intelligence artificielle (IA) et de machine learning, en faisant des choix éclairés d’approches, de pratiques, d’outils et de technologies, avec une vision globale : data science, data analyse, data management et machine learning. Vous pourrez cibler les secteurs extrêmement demandés de la data science.
Ce type de formation vous permettra d’acquérir les connaissances et les compétences nécessaires pour devenir data analyst, data scientist, data engineer, ou encore data manager. En effet, elles couvrent les principaux axes de la science de la donnée.
Autonomie et gestion de son temps
Que votre souhait de vous former en data science provienne d’une initiative personnelle ou qu’il soit motivé par votre entreprise, si la data science est un domaine totalement nouveau pour vous, il conviendrait de vous orienter vers le format « formation continue » de DataScientest. Effectivement, cela vous permettra de consacrer le temps qu’il vous faut pour appréhender au mieux toutes les notions enseignées. Sur une période de 6 mois, à partir de votre inscription (il y a une rentrée par mois), vous pourrez gérer votre temps comme bon vous semble, sans contrainte, que vous ayez une autre activité ou non.
Aussi, pour de nombreux salariés, il est difficile de bloquer plusieurs jours par semaine pour se former. C’est pourquoi, de plus en plus d’entreprises sollicitent des formations en ligne, à distance, pour plus d’efficacité ; vous aurez la possibilité de gérer votre temps de manière à adapter au mieux vos besoins d’apprentissage avec votre temps disponible.
Profiter de l’expertise de dizaines de data scientists
La start-up a déjà formé plus de 1500 professionnels actifs et étudiants aux métiers de Data Analysts et Data Scientists et conçu plus de 2 000 heures de cours de tout niveau, de l’acquisition de données à la mise en production.
» Notre offre répond aux besoins des entreprises, justifie Yoel Tordjman, CEO de Datascientest. Elle s’effectue surtout à distance, ce qui permet de la déployer sur différents sites à moindre coût, et de s’adapter aux disponibilités de chacun, avec néanmoins un coaching, d’abord collectif, puis par projet, dans le but d’atteindre un taux de complétion de 100 %. «
S’exercer concrètement avec un projet fil-rouge
Tout au long de votre formation et au fur et à mesure que vos compétences se développent, vous allez mener un projet de Data Science nécessitant un investissement d’environ 80 heures parallèlement à votre formation. Ce sera votre projet ! En effet, ce sera à vous de déterminer le sujet et de le présenter à nos équipes. Cela vous permettra de passer efficacement de la théorie à la pratique et de s’assurer que vous appliquez les thèmes abordés en cours. C’est aussi un projet fortement apprécié des entreprises, car il confirme vos compétences et connaissances acquises à l’issue de votre formation en Data Science. Vous ne serez jamais seul parce que nos professeurs seront toujours à vos côtés et disponibles en cas de besoin ; nous vous attribuons un tuteur pour votre projet parmi nos experts en data science.
Datascientest – Une solution de formation clé-en-main pour faciliter votre apprentissage et votre quotidien au travail
Passionné(e) par le Big Data et l’intelligence artificielle ? :
Devenez expert(e) en Data Science et intégrez le secteur le plus recherché par les entreprises. Une fois diplômé, vous pourrez commencer votre carrière en répondant parfaitement aux besoins des entreprises qui font face à une profusion et multiplication de données.
Vous souhaitez échanger avec Datascientest France autour de votre projet ?
Leader français de la formation en Data Science. Datascientest offre un apprentissage d’excellence orienté emploi pour professionnels et particuliers, avec un taux de satisfaction de 94 %.
Pour plus d’informations, n’hésitez pas à contacter DataScientest :
Le langage de programmation de Python Software Foundation est une programmation orientée objet. Lorsque les data scientists parient sur Python pour le traitement des données volumineuses, ils sont conscients qu’il existe d’autres options populaires telles que R, Java ou SAS. Toutefois, Python demeure la meilleure alternative pour ses avantages dans l’analyse du Big Data.
Pourquoi choisir Python ?
Entre R, Java ou Python pour le Big Data, choisir le dernier (en version majeure ou version mineure) est plus facile après avoir lu les 5 arguments suivants :
1. Simplicité
Python est un langage de programmation interprété connu pour faire fonctionner les programmes avec le moins de chaînes de caractères et de lignes de code. Il identifie et associe automatiquement les types de données. En outre, il est généralement facile à utiliser, ce qui prend moins de temps lors du codage. Il n’y a pas non plus de limitation pour le traitement des données.
2. Compatibilité
Hadoop est la plateforme Big Data open source la plus populaire. La prise en charge inhérente à Python, peu importe la version du langage, est une autre raison de la préférer.
3. Facilité d’apprentissage
Comparé à d’autres langages, le langage de programmation de Guido Van Rossum est facile à apprendre même pour les programmeurs moins expérimentés. C’est le langage de programmation idéal pour trois raisons. Premièrement, elle dispose de vastes ressources d’apprentissage. Deuxièmement, elle garantit un code lisible. Et troisièmement, elle s’entoure d’une grande communauté. Tout cela se traduit par une courbe d’apprentissage progressive avec l’application directe de concepts dans des programmes du monde réel. La grande communauté Python assure que si un utilisateur rencontre des problèmes de développement, il y en aura d’autres qui pourront lui prêter main-forte pour les résoudre.
4. Visualisation de données
Bien que R soit meilleur pour la visualisation des données, avec les packages récents, Python pour le Big Data a amélioré son offre sur ce domaine. Il existe désormais des API qui peuvent fournir de bons résultats.
5. Bibliothèques riches
Python dispose d’un ensemble de bibliothèques riche. Grâce à cela, il est possible de faire des mises à jour pour un large éventail de besoins en matière de science des données et d’analyse. Certains de ces modules populaires apportent à ce langage une longueur d’avance : NumPy, Pandas, Scikit-learn, PyBrain, Cython, PyMySQL et iPython.
Que sont les bibliothèques en Python ?
La polyvalence de toutes les versions de Python pour développer plusieurs applications est ce qui a poussé son usage au-delà de celui des développeurs. En effet, il a attiré l’intérêt de groupes de recherche de différentes universités du monde entier. Il leur ont permis de développer des librairies pour toutes sortes de domaines : application web, biologie, physique, mathématiques et ingénierie. Ces bibliothèques sont constituées de modules qui ont un grand nombre de fonctions, d’outils et d’algorithmes. Ils permettent d’économiser beaucoup de temps de programmation et ont une structure facile à comprendre.
Le programme Python est considéré comme le langage de programmation pour le développement de logiciels, de pages Web, d’applications de bureau ou mobiles. Mais, il est également le meilleur pour le développement d’outils scientifiques. Par conséquent, les data scientists sont destinés à aller de pair avec Python pour développer tous leurs projets sur le Big Data.
Python et la data science
La data science est chargée d’analyser, de transformer les données et d’extraire des informations utiles pour la prise de décision. Et il n’y a pas besoin d’avoir des connaissances avancées en programmation pour utiliser Python afin d’effectuer ces tâches. La programmation et la visualisation des résultats sont plus simples. Il y a peu de lignes de code en Python et ses interfaces graphiques de programmation sont conviviales.
Dans le développement d’un projet de science des données, il existe différentes tâches pour terminer ledit projet, dont les plus pertinentes sont l’extraction de données, le traitement de l’information, le développement d’algorithmes (machine learning) et l’évaluation des résultats.
La Computer Vision ou vision par ordinateur est une technologie d’intelligence artificielle permettant aux machines d’imiter la vision humaine. Découvrez tout ce que vous devez savoir : définition, fonctionnement, histoire, applications, formations…
Depuis maintenant plusieurs années, nous sommes entrés dans l’ère de l’image. Nos smartphones sont équipés de caméras haute définition, et nous capturons sans cesse des photos et des vidéos que nous partageons au monde entier sur les réseaux sociaux.
Les services d’hébergement vidéo comme YouTube connaissent une popularité explosive, et des centaines d’heures de vidéo sont mises en ligne et visionnées chaque minute. Ainsi, l’internet est désormais composé aussi bien de texte que d’images.
Toutefois, s’il est relativement simple d’indexer les textes et de les explorer avec des moteurs de recherche tels que Google, la tâche est bien plus difficile en ce qui concerne les images. Pour les indexer et permettre de les parcourir, les algorithmes ont besoin de connaître leur contenu.
Pendant très longtemps, la seule façon de présenter le contenu d’une image aux ordinateurs était de renseigner sa méta-description lors de la mise en ligne. Désormais, grâce à la technologie de » vision par ordinateur » (Computer Vision), les machines sont en mesure de » voir « les images et de comprendre leur contenu.
Qu’est ce que la vision par ordinateur ?
La Computer Vision peut être décrite comme un domaine de recherche ayant pour but de permettre aux ordinateurs de voir. De façon concrète, l’idée est de transmettre à une machine des informations sur le monde réel à partir des données d’une image observée.
Pour le cerveau humain, la vision est naturelle. Même un enfant est capable de décrire le contenu d’une photo, de résumer une vidéo ou de reconnaître un visage après les avoir vus une seule fois. Le but de la vision par ordinateur est de transmettre cette capacité humaine aux ordinateurs.
Il s’agit d’un vaste champ pluridisciplinaire, pouvant être considéré comme une branche de l’intelligence artificielle et du Machine Learning. Toutefois, il est aussi possible d’utiliser des méthodes spécialisées et des algorithmes d’apprentissage général n’étant pas nécessairement liés à l’intelligence artificielle.
De nombreuses techniques en provenance de différents domaines de science et d’ingénierie peuvent être exploitées. Certaines tâches de vision peuvent être accomplies à l’aide d’une méthode statistique relativement simple, d’autres nécessiteront de vastes ensembles d’algorithmes de Machine Learning complexes.
En 1966, les pionniers de l’intelligence artificielleSeymour Papert et Marvin Minsky lance le Summer Vision Project : une initiative de deux mois, rassemblant 10 hommes dans le but de créer un ordinateur capable d’identifier les objets dans des images.
Pour atteindre cet objectif, il était nécessaire de créer un logiciel capable de reconnaître un objet à partir des pixels qui le composent. À l’époque, l’IA symbolique – ou IA basée sur les règles – était la branche prédominante de l’intelligence artificielle.
Les programmeurs informatiques devaient spécifiermanuellement les règles de détection d’objets dans les images. Or, cette approche pose problème puisque les objets dans les images peuvent apparaître sous différents angles et différents éclairages. Ils peuvent aussi être altérés par l’arrière-plan, ou obstrués par d’autres objets.
Les valeurs de pixels variaient donc fortement en fonction de nombreux facteurs, et il était tout simplement impossible de créer des règlesmanuellement pour chaque situation possible. Ce projet se heurta donc aux limites techniques de l’époque.
Quelques années plus tard, en 1979, le scientifique japonais Kunihiko Fukushima créa un système de vision par ordinateur appelé » neocognitron « en se basant sur les études neuroscientifiques menées sur le cortex visuel humain. Même si ce système échoua à effectuer des tâches visuelles complexes, il posa les bases de l’avancée la plus importante dans le domaine de la Computer Vision…
La révolution du Deep Learning
La Computer Vision n’est pas une nouveauté, mais ce domaine scientifique a récemment pris son envol grâce aux progrès effectués dans les technologies d’intelligence artificielle, de Deep Learninget de réseaux de neurones.
Dans les années 1980, le Français Yan LeCun crée le premier réseau de neurones convolutif : une IA inspirée par le neocognitron de Kunihiko Fukushima. Ce réseau est composé de multiples couches de neurones artificiels, des composants mathématiques imitant le fonctionnement de neurones biologiques.
Lorsqu’un réseau de neurones traite une image, chacune de ses couches extrait des caractéristiques spécifiques à partir des pixels. La première couche détectera les éléments les plus basiques, comme les bordures verticales et horizontales.
À mesure que l’on s’enfonce en profondeur dans ce réseau, les couches détectent des caractéristiques plus complexes comme les angles et les formes. Les couches finales détectent les éléments spécifiques comme les visages, les portes, les voitures. Le réseau produit enfin un résultat sous forme de tableau de valeurs numériques, représentant les probabilités qu’un objet spécifique soit découvert dans l’image.
L’invention de Yann LeCun est brillante, et a ouvert de nouvelles possibilités. Toutefois, son réseau de neurones était restreintpar d’importantes contraintes techniques. Il était nécessaire d’utiliser d’immenses volumes de données et des ressources de calcul titanesques pour le configurer et l’utiliser. Or, ces ressources n’étaient tout simplement pas disponibles à cette époque.
Dans un premier temps, les réseaux de neurones convolutifs furent donc limités à une utilisation dans les domaines tels que les banques et les services postaux pour traiter des chiffres et des lettres manuscrites sur les enveloppes et les chèques.
Il a fallu attendre 2012 pour que des chercheurs en IA de Toronto développentle réseau de neurones convolutif AlexNet et triomphent de la compétition ImageNet dédiée à la reconnaissance d’image. Ce réseau a démontré que l’explosion du volume de données et l’augmentation de puissance de calcul des ordinateurs permettaient enfin d’appliquer les » neural networks » à la vision par ordinateur.
Ce réseau de neurones amorça la révolution du Deep Learning : une branche du Machine Learning impliquant l’utilisation de réseaux de neurones à multiples couches. Ces avancées ont permis de réaliser des bonds de géants dans le domaine de la Computer Vision. Désormais, les machines sont même en mesure de surpasser les humains pour certaines tâches de détection et d’étiquetage d’images.
Comment fonctionne la vision par ordinateur
Les algorithmes de vision par ordinateur sont basés sur la » reconnaissance de motifs « . Les ordinateurs sont entraînés sur de vastes quantités de données visuelles. Ils traitent les images, étiquettent les objets, et trouvent des motifs (patterns) dans ces objets.
Par exemple, si l’on nourrit une machine avec un million de photos de fleurs, elle les analysera et détectera des motifs communs à toutes les fleurs. Elle créera ensuite un modèle, et sera capable par la suite de reconnaître une fleurchaque fois qu’elle verra une image en comportant une.
Les algorithmes de vision par ordinateur reposent sur les réseaux de neurones, censés imiter le fonctionnement du cerveau humain. Or, nous ne savons pas encore exactement comment le cerveau et les yeux traitent les images. Il est donc difficile de savoir à quel point les algorithmes de Computer Vision miment ce processus biologique.
Les machines interprètent les images de façon très simple. Elles les perçoivent comme des séries de pixels, avec chacun son propre ensemble de valeurs numériques correspondant aux couleurs. Une image est donc perçue comme une grille constituée de pixels, chacun pouvant être représenté par un nombre généralement compris entre 0 et 255.
Bien évidemment, les chosesse compliquent pour les images en couleur. Les ordinateurs lisent les couleurs comme des séries de trois valeurs : rouge, vert et bleu. Là encore, l’échelle s’étend de 0 à 255. Ainsi, chaque pixel d’une image en couleur à trois valeurs que l’ordinateur doit enregistrer en plus de sa position.
Chaque valeur de couleur est stockée en 8 bits. Ce chiffre est multiplié par trois pour une image en couleurs, ce qui équivaut à 24 bits par pixel. Pour une image de 1024×768 pixels, il faut donc compter 24 bits par pixels soit presque 19 millions de bits ou 2,36 mégabytes.
Vous l’aurez compris : il faut beaucoup de mémoire pour stocker une image. L’algorithme de Computer Vision quant à lui doit parcourir un grand nombre de pixels pour chaque image. Or, il faut généralement plusieurs dizaines de milliers d’images pour entraîner un modèle de Deep Learning.
C’est la raison pour laquelle la vision par ordinateur est une discipline complexe, nécessitant une puissance de calcul et une capacité de stockage colossales pour l’entraînement des modèles. Voilà pourquoi il a fallu attendre de nombreuses années pour que l’informatique se développe et permette à la Computer Vision de prendre son envol.
Les différentes applications de Computer Vision
La vision par ordinateur englobe toutes les tâches de calcul impliquant le contenu visuel telles que les images, les vidéos ou même les icônes. Cependant, il existe de nombreuses branchesdans cette vaste discipline.
La classification d’objet consiste à entraîner un modèle sur un ensemble de données d’objets spécifiques, afin de lui apprendre à classer de nouveaux objets dans différentes catégories. L’identification d’objet quant à elle vise à entraîner un modèle à reconnaître un objet.
Parmi les applications les plus courantes de vision par ordinateur, on peut citer la reconnaissance d’écriture manuscrite. Un autre exemple est l’analyse de mouvement vidéo, permettant d’estimer la vélocité des objets dans une vidéo ou directement sur la caméra.
Dans la segmentation d’image, les algorithmes répartissent les images dans plusieurs ensembles de vues. La reconstruction de scène permet de créer un modèle 3D d’une scène à partir d’images et de vidéos.
Enfin, la restauration d’imageexploite le Machine Learning pour supprimer le » bruit » (grain, flou…) sur des photos. De manière générale, toute application impliquant la compréhension des pixels par un logiciel peut être associée à la Computer Vision.
Quels sont les cas d’usages de la Computer Vision ?
La Computer Vision fait partie des applications du Machine Learning que nous utilisons déjà au quotidien, parfois sans même le savoir. Par exemple, les algorithmes de Googleparcourent des cartes pour en extraire de précieuses données et identifier les noms de rues, les commerces ou les bureaux d’entreprises.
De son côté, Facebook exploite la vision par ordinateurafin d’identifier les personnes sur les photos. Sur les réseaux sociaux, elle permet aussi de détecter automatiquement le contenu problématique pour le censurer immédiatement.
Les entreprises de la technologie sont loin d’être les seules à se tourner vers cette technologie. Ainsi, le constructeur automobile Ford utilise la Computer Vision pour développer ses futurs véhicules autonomes. Ces derniers reposent sur l’analyse en temps réel de nombreux flux vidéo capturés par la voiture et ses caméras.
Il en va de même pour tous les systèmes de voitures sans pilote comme ceux de Tesla ou Nvidia. Les caméras de ces véhicules capturent des vidéos sous différents angles et s’en servent pour nourrir le logiciel de vision par ordinateur.
Ce dernier traite les images en temps réel pour identifier les bordures des routes, lire les panneaux de signalisation, détecter les autres voitures, les objets et les piétons. Ainsi, le véhicule est en mesure de conduire sur autoroute et même en agglomération, d’éviter les obstacles et de conduire les passagers jusqu’à leur destination.
La santé
Dans le domaine de la santé, la Computer Vision connaît aussi un véritable essor. La plupart des diagnostics sont basés sur le traitement d’image : lecture de radiographies, scans IRM…
Google s’est associé avec des équipes de recherche médicalepour automatiser l’analyse de ces imageries grâce au Deep Learning. D’importants progrès ont été réalisés dans ce domaine. Désormais, les IA de Computer Vision se révèlent plus performantes que les humains pour détecter certaines maladies comme la rétinopathie diabétique ou divers cancers.
Le sport
Dans le domaine du sport, la vision par ordinateur apporte une précieuse assistance. Par exemple, la Major League Baseballutilise une IA pour suivre la balle avec précision. De même, la startup londonienne Hawk-Eye déploie son système de suivi de balle dans plus de 20 sports comme le basketball, le tennis ou le football.
La reconnaissance faciale
Une autre technologie reposant sur la Computer Vision est la reconnaissance faciale. Grâce à l’IA, les caméras sont en mesure de distinguer et de reconnaître les visages. Les algorithmes détectent les caractéristiques faciales dans les images, et les comparent avec des bases de données regroupant de nombreux visages.
Cette technologie est utilisée sur des appareils grand public comme les smartphones pour authentifier l’utilisateur. Elle est aussi exploitée par les réseaux sociaux pour détecter et identifier les personnes sur les photos. De leur côté, les autorités s’en servent pour identifier les criminels dans les flux vidéo.
La réalité virtuelle et augmentée
Les nouvelles technologies de réalité virtuelle et augmentée reposent également sur la Computer Vision. C’est elle qui permet aux lunettes de réalité augmentée de détecter les objets dans le monde réelet de scanner l’environnement afin de pouvoir y disposer des objets virtuels.
Par exemple, les algorithmes peuvent permettre aux applications AR de détecter des surfaces planes comme des tables, des murs ou des sols. C’est ce qui permet de mesurer la profondeur et les dimensionsde l’environnement réel pour pouvoir y intégrer des éléments virtuels.
Les limites et problèmes de la Computer Vision
La vision par ordinateur présente encore des limites. En réalité, les algorithmes se contentent d’associer des pixels. Ils ne » comprennent » pas véritablement le contenu des images à la manière du cerveau humain.
Pour cause, comprendre les relations entre les personnes et les objets sur des images nécessite un sens commun et une connaissance du contexte. C’est précisément pourquoi les algorithmes chargés de modérer le contenu sur les réseaux sociaux ne peuvent faire la différence entre la pornographie et une nudité plus candide comme les photos d’allaitement ou les peintures de la Renaissance.
Alors que les humains exploitent leur connaissance du monde réel pour déchiffrer des situations inconnues, les ordinateurs en sont incapables. Ils ont encore besoin de recevoir des instructions précises, et si des éléments inconnusse présentent à eux, les algorithmes dérapent. Un véhicule autonome sera par exemple pris de cours face à un véhicule d’urgence garé de façon incongrue.
Même en entraînant une IA avec toutes les données disponibles, il est en réalité impossible de la préparer à toutes les situations possibles. La seule façon de surmonter cette limite serait de parvenir à créer une intelligence artificielle générale, à savoir une IA véritablement similaire au cerveau humain.
Comment se former à la Computer Vision ?
Si vous êtes intéressé par la Computer Vision et ses multiples applications, vous devez vous former à l’intelligence artificielle, au Machine Learning et au Deep Learning. Vous pouvez opter pour les formations DataScientest.
Le Machine Learning et le Deep Learning sont au coeur de nos formations Data Scientist et Data Analyst. Vous apprendrez à connaître et à manier les différents algorithmes et méthodes de Machine Learning, et les outils de Deep Learning comme les réseaux de neurones, les GANs, TensorFlow et Keras.
Ces formations vous permettront aussi d’acquérir toutes les compétences nécessaires pour exercer les métiers de Data Scientist et de Data Analyst. À travers les différents modules, vous pourrez devenir expert en programmation, en Big Data et en visualisation de données.
Nos différentes formations adoptent une approche innovante de Blended Learning, alliant le présentiel au distanciel pour profiter du meilleur des deux mondes. Elles peuvent être effectuées en Formation Continue, ou en BootCamp.
Pour le financement, ces parcours sont éligibles au CPF et peuvent être financés par Pôle Emploi via l’AIF. À l’issue du cursus, les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne. Parmi nos alumnis, 93% trouvent un emploi immédiatementaprès l’obtention du diplôme. N’attendez plus, et découvrez nos formations.
Je viens tout juste de rejoindre les équipes d’Alphalyr, start-up parisienne spécialisée sur Google Analytics qui propose des prestations d’hygiène analytics, de la visualisation de données et du data coaching – j’adore ce concept ! Tout pour optimiser ses datas sur le web !
Et j’ai l’immense honneur d’y devenir Data Scientist – en herbe, d’accord, mais data scientist tout de même 🙂
La capacité à comprendre et à expliquer les décisions prises par les modèles d’Intelligence Artificielle ou de Machine Learning est devenue primordiale. Ces technologies sophistiquées s’intègrent de plus en plus dans des domaines critiques tels que la santé, la finance ou encore la sécurité. Les solutions comme SHAP (SHapley Additive exPlanations) connaissent un essor fulgurant.
SHAP s’inspire des concepts de la théorie des jeux coopératifs, et offre une méthode rigoureuse et intuitive pour décomposer les prédictions des modèles en contributions individuelles de chaque caractéristiques.
Fondements théoriques de SHAP
Il est nécessaire d’analyser un tant soi peu les racines théoriques de SHAP afin de comprendre sa valeur ajoutée mais également la raison qui le rend efficace pour interpréter des modèles parfois complexes.
Théorie des jeux coopératifs
Cette théorie, une branche de la théorie des jeux, se concentre sur l’analyse des stratégies pour les groupes d’agents qui peuvent former des coalitions et partager des récompenses. Au cœur de cette théorie se trouve la notion de “valeur équitable”, une façon de distribuer les gains (ou les pertes) parmi les participants d’une manière qui reflète leur contribution individuelle. C’est dans ce contexte que la Valeur de Shapley.
La Valeur de Shapley
Il s’agit d’un concept mathématique, introduit par Lloyd Shapley en 1953, servant à déterminer la part juste de chaque joueur dans un jeu coopératif. Elle est calculée en considérant toutes les permutations possibles de joueurs et en évaluant l’impact marginal de chaque joueur lorsqu’il rejoint une coalition. En d’autres termes, elle mesure la contribution moyenne d’un joueur à la coalition, en tenant compte de toutes les combinaisons possibles dans lesquelles ce joueur pourrait contribuer.
Lien avec SHAP
Dans le contexte du machine learning, SHAP utilise la Valeur de Shapley pour attribuer une « valeur d’importance » à chaque caractéristique d’un modèle prédictif. Chaque caractéristique d’une instance de données est considérée comme un « joueur » dans un jeu coopératif où le « gain » est la prédiction du modèle.
Implications de la Valeur de Shapley en IA
Cette valeur représente une avancée significative dans l’interprétabilité des modèles d’IA. Elle permet non seulement de quantifier l’impact de chaque caractéristique de manière juste et cohérente, mais offre aussi une transparence qui aide à construire la confiance dans les modèles d’apprentissage automatique.
Comment fonctionne SHAP ?
Au cœur de SHAP se trouve l’idée de décomposer une prédiction spécifique en un ensemble de valeurs attribuées à chaque caractéristique d’entrée. Ces valeurs sont calculées de manière à refléter l’impact de chaque caractéristique sur l’écart entre la prédiction actuelle et la moyenne des prédictions sur l’ensemble des données. Pour y parvenir, SHAP explore toutes les combinaisons possibles de caractéristiques et leurs contributions à la prédiction. Ce processus utilise la Valeur de Shapley, que nous avons abordée précédemment, pour assurer une répartition équitable et précise de l’impact parmi les caractéristiques.
Prenons un exemple
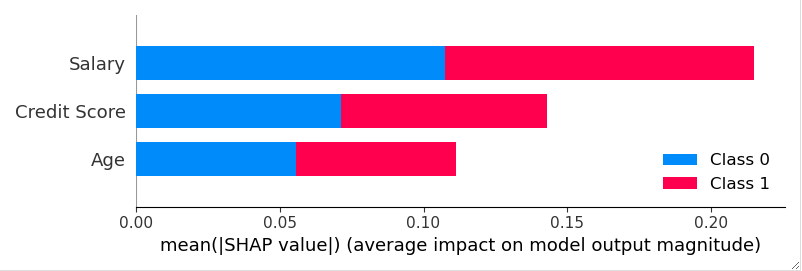
Imaginons un modèle prédictif utilisé dans le secteur financier pour évaluer le risque de crédit. SHAP peut révéler comment descaractéristiques telles que le score de crédit, le revenu annuel et l’historique de remboursement contribuent à la décision finale du modèle. Si un client se voit refuser un crédit, SHAP peut indiquer quelles caractéristiques ont le plus influencé cette décision négative, fournissant ainsi des indicateurs pertinents.
Utilisation avec Python
Python propose une bibliothèque pour SHAP. Cette dernière permet aux utilisateurs de tirer pleinement parti des avantages de SHAP pour l’interprétabilité des modèles.
Installation
La première étape, est bien sûr l’installation de la bibliothèque
pipinstallshap
Une fois installée, il ne reste plus qu’à l’importer dans votre environnement :
importshap
Préparation des données
Supposons que vous ayez un modèle de Machine Learning déjà entraîné, tel qu’un modèle de forêt aléatoire pour la classification (RandomForestClassifier). Vous aurez donc besoin d’un ensemble de données pour l’analyse :
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.ensembleimportRandomForestClassifier
importpandasaspd
# Load and prepare datas
data=pd.read_csv('my_amazing_dataset.csv')
X=data.drop('target', axis=1)
y=data['target']
# Split train and test set
X_train, X_test, y_train, y_test= train_test_split(X, y, test_size=0.2, random_state=42)
# Train the model
model=RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
Analyse SHAP
Après entraînement du modèle, l’utilisation de SHAP vous permettra d’analyser l’impact des caractéristiques. Pour la poursuite de cet exemple, nous pouvons utiliser le Explainer Tree.
# Create Explainer Tree
explainer=shap.TreeExplainer(model)
# Compute SHAP Values on the test set
shap_values=explainer.shap_values(X_test)
Visualisation des résultats
SHAP offre bien évidemment diverses options de visualisation pour interpréter les résultats. Ainsi, pour avoir un résumé quant à l’importance des caractéristiques :
shap.summary_plot(shap_values, X_test)
Il est également possible d’examiner l’impact d’une caractéristique spécifique :
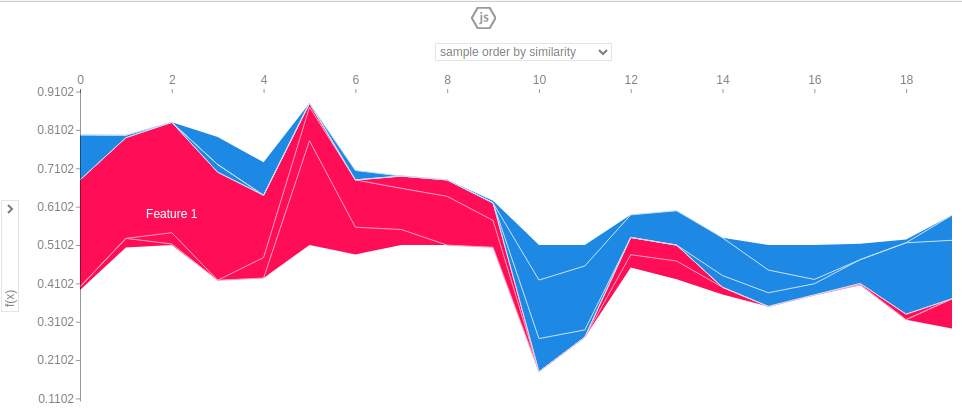
# Need to initialize javascript in order to display the plots
SHAP (SHapley Additive exPlanations) est un outil puissant et polyvalent pour l’interprétabilité des modèles de Machine Learning. En s’appuyant sur les principes de la théorie des jeux coopératifs et de la Valeur de Shapley, il offre une méthode rigoureuse pour décomposer et comprendre les contributions des caractéristiques individuelles dans les prédictions d’un modèle.
L’utilisation de la bibliothèque SHAP en Python démontre sa facilité d’intégration et de mise en œuvre dans le workflow de data science. De plus, avec une Intelligence Artificielle devenant de plus en plus omniprésente, l’interprétabilité des modèles ne peut pas se permettre d’être sous-estimée.
Direct Query est une méthode permettant une connexion directe à une source de données avec Power BI. Découvrez tout ce que vous devez savoir : présentation, fonctionnement, avantages et inconvénients…
L’outil de business intelligence Power BI de Microsoft permet aux entreprises d’analyser et de visualiser des données de manière interactive. Il s’agit d’une plateforme complète, offrant de nombreuses fonctionnalités pour transformer les données brutes en informations exploitables pour la prise de décision stratégique.
Parmi ces différentes fonctionnalités, Direct Query permet de se connecter directement à une source de données externe. Par la suite, il est possible de travailler en temps réel avec les données sans avoir besoin de les copier comme c’est le cas avec la méthode classique d’importation.
À travers ce dossier, vous allez découvrir tout le fonctionnement de Direct Query et pourquoi cette méthode s’avère très utile dans certaines situations…
Qu’est-ce que Direct Query ?
À l’aide de Direct Query, les utilisateurs de Power BI peuvent se connecter directement à une source de données externes. Il peut s’agir d’une base de données, d’un fichier Excel, ou encore d’un service en ligne.
Dès que la connexion est établie, la requête est effectuée sur les données à la source et en temps réel. Les résultats sont ensuite affichés dans les visualisations de Power BI.
Afin de communiquer avec la source de données, Direct Query utilise un langage de requête commeSQL. Grâce à l’exécution en temps réel, les données sont toujours à jour et les résultats sont instantanés.
La possibilité d’accéder aux données en temps réel est l’un des principaux avantages offerts par Direct Query sur Power BI. Ceci permet une analyse des données plus précise, et plus efficace.
Par ailleurs, Direct Query évite le stockage redondant des données puisqu’il n’est pas nécessaire de les copier. Ainsi, les coûts de stockage peuvent être largement réduits.
Autre point fort : Direct Query peut exploiter des sources de données volumineuses sans avoir à les importer dans Power Query. Les utilisateurs n’ont donc guère à se soucier des limitations imposées par le stockage local.
Enfin, cette fonctionnalité permet d’optimiser les performances des rapports. Les données n’étant pas stockées localement, la taille du fichier est réduite et les temps de chargement s’en trouvent améliorés. Les problèmes de ralentissement sont également atténués.
Néanmoins, Direct Query comporte aussi des inconvénients et n’est donc pas toujours le choix idéal. Cette méthode de connexion directe impose une dépendance à une source de données en ligne, pouvant poser problème en cas de problème de connexion. Les temps de réponse peuvent augmenter.
Par ailleurs, les capacités de traitement de données sont limitées. La configuration de l’outil peut aussi s’avérer complexe…
Comment configurer Direct Query ?
La configuration de Direct Query s’effectue en plusieurs étapes. En premier lieu, il est nécessaire de se connecter à la source de données externes puis de créer un rapport dans Power BI.
On configure ensuite Direct Query afin d’utiliser les données en temps réel. Enfin, les visualisations et les filtres doivent être définis dans le rapport afin d’afficher les données.
Notons que la configuration de Direct Query peut varier en fonction de la source de données externe. C’est ce qui peut rendre la tâche potentiellement compliquée.
Par exemple, pour vous connecter à une base de données SQL Server, vous devrez sélectionner « Direct Query » comme méthode de connexion dans Power BI Desktop puis spécifier les informations de connexion à la base de données.
Précisons aussi que les fonctionnalités de transformation de données ne sont pas disponibles avec Direct Query. Par conséquent, toutes les transformations doivent être effectuées dans la source externe avant d’utiliser les données dans Power BI.
Enfin, certains types de données ne sont pas pris en charge par Direct Query. C’est notamment le cas des données semi-structurées.
Direct Query vs Import : quelle est la meilleure méthode de connexion aux sources de données sur Power BI ?
Les deux principales méthodes de connexion à une source de données dans Power BI sont Direct Query et l’importation de données.
Cette dernière consiste à extraire les données de la source, afin de les stocker localement sur Power BI. C’est une alternative à la connexion directe offerte par Power BI.
En réalité, l’importation est la méthode la plus couramment utilisée. Après avoir extrait les données de la source, on les transforme en fonction des besoins avant de les stocker sur la plateforme.
Cette méthode est utile pour les sources de données volumineuses ou instables. Les données sont stockées localement, et les rapports peuvent donc être consultés indépendamment de la disponibilité de la source.
En revanche, ce stockage local peut consommer beaucoup d’espace sur le disque dur. Le volume d’importation est d’ailleurs limité à 1Go. De plus, les données peuvent rapidement devenir obsolètes si la source change fréquemment.
Conclusion : Direct Query, une alternative à l’importation de données sur Power BI
En conclusion, Direct Query est une fonctionnalité utile et puissante et Power BI permettant de travailler avec des données en temps réel et sans stockage redondant.
Toutefois, dans certains cas, il peut être préférable d’opter pour l’importation des données. Il est donc important de bien comprendre les avantages et inconvénients de chacune de ces méthodes.
Afin d’apprendre à maîtriser Power BI et ses nombreuses fonctionnalités comme Direct Query, vous pouvez choisir DataScientest.
Notre formation dédiée à Power BI se décline en trois formats : débutant, avancé ou maîtrise complète. La durée totale du programme est de 38 heures réparties sur 5 jours.
La partie destinée aux débutants permet d’apprendre à manier Direct Query et la connexion aux sources de données, le langage DAX et les bases de la dataviz.
Par la suite, au cours de la partie dédiée aux utilisateurs avancés, vous découvrirez le langage de formule M, ou encore des notions comme les DataFlows et l’actualisation incrémentielle.
À l’issue du cursus, vous serez capable de collecter, d’organiser, d’analyser les données avec Power BI et de créer des tableaux de bord interactifs. En tant que Microsoft Learning Partner officiel, DataScientest vous prépare aussi au passage de la certification Microsoft Power BI Data Analyst Associate.
Notre formation est également enregistrée au RNCP France Compétences, et notre organisme reconnu par l’État est éligible au Compte Personnel de Formation pour le financement. Découvrez DataScientest !
Que ce soit pour gagner en visibilité ou pour convertir des prospects en clients, la majorité des entreprises doit développer sa présence sur le web. Mais pour atteindre les objectifs fixés (en termes de notoriété ou de conversion), encore faut-il mettre en place les bonnes actions. Et pour savoir ce qui est le plus pertinent, il convient d’utiliser et d’exploiter toutes les données à disposition. C’est justement le rôle du digital analyst. Alors quel est ce nouveau métier ? Quelles sont ses missions ? Quelles sont les compétences indispensables ? Et surtout, quelle formation pour devenir digital analyst ? Nous répondons à toutes vos questions.
Qu’est-ce qu’un digital analyst ?
Également appelé web analyst ou chef de projet tracking, le digital analyst exploite toutes les données issues du web et des réseaux sociaux pour améliorer les performances de l’entreprise en ligne. Concrètement, l’analyse des données doit permettre d’optimiser l’expérience utilisateur sur un site web, comprendre les sources de trafic et plus globalement le retour sur investissement de toutes les actions entreprises via le site (SEA, SEO, landing pages…). Ce faisant, les organisations améliorent leur avantage concurrentiel.
À ce titre, le métier de chef de projet tracking est particulièrement prisé par les entreprises de tout secteur d’activité. Mais pour exercer cette profession, mieux vaut suivre une formation de digital analyst.
Quelles sont les missions d’un digital analyst ?
Pour améliorer les performances d’une entreprise sur le web grâce aux données, le digital analyst doit mettre en place les actions suivantes :
Implémenter des outils de collecte de données : le web analyst doit récupérer un maximum d’informations sur le comportement des utilisateurs d’un site internet. À la fois pour mieux connaître sa cible (âge, secteur géographique, sexe…), mais aussi pour mieux comprendre ses habitudes (panier moyen, temps de visite, période de navigation, abandon de panier…). En effet, les actions de l’internaute sont des ressources précieuses pour l’entreprise. Et ce, tout au long du parcours client.
Analyser les données : les informations ainsi collectées permettent au digital analyst de déduire des tendances et d’identifier le client cible.
Représenter les données : si le chef de projet tracking peut comprendre facilement les milliers de lignes issus d’un fichier Excel, ce n’est pas forcément le cas des décisionnaires. Pour faciliter la compréhension par tous, cet expert data doit représenter les données à travers des outils de visualisation (notamment des graphiques, des tableaux de bord, des courbes…).
Faire des recommandations : en fonction de son analyse, il peut suggérer des actions pour améliorer l’expérience utilisateur, la stratégie digitale et la conversion globale du site web.
Animer des formations : cette mission n’est pas automatique. Mais force est de constater que l’analyse d’un site web et du comportement des utilisateurs concerne plusieurs départements de l’organisation. Par seulement les experts data. Ainsi, le digital analyst peut former les équipes marketing, commerciales, produit, …. L’idée est alors de les sensibiliser à l’importance des données pour prendre de meilleures décisions.
Pour remplir ces missions avec efficacité, nous vous conseillons de suivre une formation de digital analyst.
Les outils d’analyse web (Google Analytics, Omniture, Webtrends…) ;
La programmation web ;
Les outils CRM.
Pour acquérir ces différentes hard skills, il est préférable de suivre une formation digital analyst.
Au-delà de ces compétences techniques, le web analyst doit aussi disposer de plusieurs qualités personnelles. Par exemple, la curiosité pour continuer à se former sur les dernières tendances en marketing digital et les nouvelles technologies, ou encore un sens du relationnel pour former les équipes et apporter des recommandations.
Bon à savoir : la maîtrise de l’anglais est un plus pour devenir digital analyst.
Quelle formation pour être digital analyst ?
Que ce soit pour acquérir une connaissance des langages informatiques, des spécificités du marketing digital ou pour mettre en place des outils de collecte de données, il est primordial de se former. Mais à l’heure actuelle, il n’existe pas encore de formation spécifique pour devenir digital analyst. Cela dit, il est possible d’exercer ce métier après un bac+3 ou bac + 5 en marketing digital, mathématique statistique, communication et multimédias (en école de commerce ou à l’université).
Et bien sûr, vous pouvez également suivre une formation de data analyst.
Rejoignez DataScientest pour devenir digital analyst
Si le digital analyst doit maîtriser le marketing, c’est avant tout un expert des données. Il doit déduire des insights afin d’aider les équipes à prendre de meilleures décisions. Mais pour maîtriser l’analyse de données, mieux vaut suivre une formation spécifique. C’est justement ce que nous vous proposons chez DataScientest. Grâce à nos formations data analyst (ou même data scientist, vous apprendrez à maîtriser les outils et la méthode de travail pour devenir digital analyst.
Dans cet article, vous découvrirez ce qu’est le métier de Data Strategist. Vous allez pouvoir vous familiariser avec les différentes missions, les compétences indispensables et les outils de ce métier tant recherché ainsi que les atouts que ce rôle représente pour une entreprise et dans votre carrière.
Pour commencer, vous devez savoir qu’un Data Strategist est la personne qui va prendre en charge la gestion et l’analyse des données. Il va ensuite agir auprès des structures afin d’identifier les besoins de son activité principale et par la suite il élaborera un projet de développement, capable d’impacter des domaines aussi variés que le marketing, l’IT ou le business.
Quelles sont les missions d’un Data Strategist ?
Exécution de la stratégie avec le Chief Data Officer
Proposition de réponse innovantes et créatives dans le domaine de la data
Planification et chefferie de projets
Accompagnement des clients dans la compréhension de l’impact du Big Data
Conception, architecture et développement de solution d’intelligence artificielle
Assistance aux équipes de développement commercial dans les activités d’avant-vente et les appels d’offres
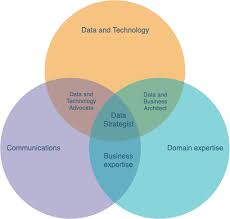
Diagramme de Venn pour le Data Strategist
Les trois cercles présents dans ce diagramme représentent les trois domaines de connaissances les plus importants pour un Data Strategist :
Business
Communication
Data & Technologie
Le Data Strategist travaille principalement sur le côté business de la data. Il devra proposer des idées afin d’améliorer l’expansion de l’entreprise ou son organisation. À l’instar d’un chef de projet, il encadre les équipes fonctionnelles, recueille le besoin, gère les plannings, définit la stratégie technique et commerciale mais dans le domaine spécifique de la Big Data.
Quelles sont les compétences que doit avoir un Data Strategist ?
Diplôme d’une école de commerce ou d’ingénieur
Expériences significatives en Data Strategy, Data Gouvernance, Data Management
Maîtrise des technologies de gouvernance, Master Data Management, Analytics, Intelligence Artificielle, Business Intelligence
Le Data Strategist utilise principalement Microsoft Power BI, qui est une solution d’analyse de données et un outil incontournable dans ce domaine, permettant d’effectuer les tâches suivantes :
La transformation des données
La modélisation et visualisation des données
La configuration de tableaux de bord, de rapports et applications
Pour permettre la mise en place d’un projet Cloud dans son intégralité, vous aurez besoin de maîtriser AWS qui régit les fonctions suivantes :
Conception des architectures résilientes et sécurisées
Infrastructure mondiale et fiabilité
Réseaux
Stockage base de données
Présentation du Well Architect Framework et des avantages du cloud
Les atouts de la profession
Les métiers de la data (Data Strategist, Data Scientist, Data Analyst ou Data Engineer) sont en pleine expansion. Peu de profils compétents sont disponibles sur le marché et les entreprises souffrent d’un cruel manque de ressources pour gérer et traiter leurs données.
C’est un domaine dans lequel vous trouverez pleine et entière satisfaction professionnelle, tant sur le plan de la stimulation intellectuelle que sur la montée en compétences constante, où les perspectives d’évolution sont prometteuses.
En complément des points spécifiés en amont, le salaire d’un Data Strategist représente un attrait supplémentaire. Il est évalué selon plusieurs critères :
Le niveau d’étude
Les compétences acquises
Les différentes expériences dans le domaine
Le type de structure qui recrute
De manière générale, la rémunération est plus élevée dans le privé que dans le secteur public, dont l’indice n’est pas forcément réévalué annuellement. La fourchette salariale pour la profession se situe entre 34000€ et 58000€ brut.
Vous savez maintenant tout sur le métier de Data Strategist.
Si vous souhaitez vous reconvertir dans ce domaine, n’hésitez pas à découvrir notre formationPower BI et AWS.
Il existe de nombreux outils appliqués au secteur des entreprises qui, dans bien des cas, facilitent la prise de décision pour les parties prenantes, des chefs de département aux équipes commerciales et jusqu’au Directeur général. Si aujourd’hui, nous manipulons de plus en plus de données et d’informations pour prendre des décisions, nous devons avoir l’aide supplémentaire de la technologie et nous appuyer sur des solutions logicielles d’entreprise pour rationaliser ces tâches.
Les solutions logicielles Microsoft Power BI, qui en Anglais se réfère à Business Intelligence, et que l’on peut traduire par l’intelligence d’affaires. Il s’agit de solutions commerciales qui aideront les responsables des entreprises à accélérer le processus de prise de décision.
La différenciation des entreprises passe par une prise de décision correcte. Aujourd’hui, nous vivons dans une époque entièrement numérique où les décisions doivent reposer sur une base solide d’informations et de données bien contrastées.
BI ou Business Intelligence
Parler de Power BI, c’est parler des services Power BI, c’est-à-dire, de l’ensemble de solutions et des méthodes axées sur l’analyse et la compréhension du Big Data. Ce dernier fait ici référence au grand volume de données qui sont générées à la fois dans les environnements professionnels et personnels, que ce soit par les personnes ou toute autre entité constituée de plusieurs individus.
Tous ces outils sont compilés sous les méthodologies d’un plan d’affaires d’entreprise qui doit se concentrer sur la collecte, l’analyse et la vérification du Big Data afin de développer une trajectoire visuelle et synthétisée.
Si l’on veut vraiment disposer d’une solution logicielle de Business Intelligence, elle doit permettre de faire :
–Des extractions de données volumineuses
–De l’analyse de données en temps réel
–De la création de modèles de données
–Des visualisations de données
–De la création de rapports
À partir de ces lignes directrices, toute entité commerciale doit localiser et travailler sur les incidents qui se sont produits et choisir l’option la plus bénéfique et la plus correcte pour l’entreprise.
Microsoft Power BI pour les entreprises
Power BI est une solution de Business Intelligence présentée par Microsoft. Elle est axée sur les entreprises et les indépendants et permet de disposer à tout moment et en tout lieu de toutes les informations et de la situation de l’entreprise.
En utilisant Power BI, il est possible de créer des rapports et des visualisations personnalisées présentant l’ensemble de l’entreprise. Cela se fait par le biais de tableaux de bord générés par diverses bases de données, l’évolution des projets, le développement commercial et plusieurs autres actions de l’entreprise.
Power BI est l’un des outils de Microsoft qui ont la possibilité d’être localisés dans le Cloud, ce qui permet de connaître de manière rapide les informations les plus importantes des différents panneaux qui sont continuellement mis à jour.
Les données collectées pour cet outil sont produites à partir de sources de données très diverses, y compris à une base de données Microsoft SQL Server.
À travers le programme, on peut développer et connecter des bases de données, configurer l’évolution graphique pour plusieurs objectifs : évaluer l’état de l’entreprise, analyser l’évolution des ventes, connaître le volume des commandes, vérifier les paiements fournisseurs et bien d’autres actions d’analyse, le tout en temps réel.
Une autre nouvelle fonctionnalité de la solution Power BI Desktop est son canevas à partir duquel des onglets peuvent être générés selon les besoins. Cela permet à l’utilisateur de créer sa propre idée, de mieux comprendre, d’interpréter et d’avoir une plus grande capacité d’argumentation lorsque les parties prenantes de l’entreprise devront prendre des décisions sur la base des données.
Et bien sûr, tout cela a l’avantage d’être disponible et opérationnel dans l’environnement de l’informatique en nuage. Le Cloud se chargera d’effectuer et de générer les opérations et les calculs nécessaires pour obtenir les résultats.
Enfin, il faut souligner une autre des caractéristiques des plus attrayantes. Il s’agit de la possibilité de sauvegarder les informations sur ordinateur et ensuite de publier les données et les rapports depuis le site Power BI pour les partager avec d’autres utilisateurs en ligne.
Quels sont les avantages de l’application de Power BI ?
Tous les départements d’une entreprise sont essentiels au bon fonctionnement de celle-ci. Si l’un d’entre eux échoue dans ses objectifs, une chaîne d’échecs se produira. Par conséquent, l’entreprise dans son ensemble en souffrira également. C’est là qu’intervient l’outil Power BI.
Les solutions Microsoft pour entreprises (Power BI, Power Query, Office 365…) permettent la transformation numérique pour un travail beaucoup plus productif. L’outil Power BI permet d’intégrer tous les départements dès sa mise en œuvre.
En effet, il existe 4 avantages pertinents concernant cette solution de Business Intelligence :
–Accessibilité : les bases de données et les services Power BI sont à la fois accessibles dans le Cloud et sur Desktop.
–Informations mises à jour en temps réel : lorsque des problèmes ou des opportunités sont détectés instantanément, une plus grande optimisation du fonctionnement de l’entreprise est obtenue. Avec Power BI, cette détection et cette identification se font en temps réel.
–Interface intuitive : les informations sont claires et hiérarchisées et proviennent depuis tous les départements de l’entreprise. Elles sont également intuitives pour garantir une accessibilité complète à tout utilisateur.
–Agilité : de par sa conception, sa stratégie d’organisation et sa hiérarchie, Power BI permet une restitution détaillée des informations autant de fois que nécessaire. La mise à jour se fait en temps réel.
En conclusion, Microsoft Power Bi est une application intelligente et prédictive qui est un grand encouragement pour les entreprises et leurs dirigeants lorsqu’il s’agit d’interpréter et d’analyser toutes les informations. Il permet d’interpréter tous types de données et de les afficher dans des graphiques totalement compréhensibles par tous. D’ailleurs, Power BI a encore une fois été élue meilleure plateforme d’analyse de données et de Business Intelligence dans le Magic Quadrant de Gartner.