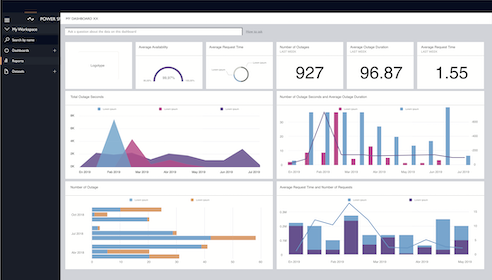
Microsoft Power BI est une famille d’outils de Business Intelligence. À partir des données d’une entreprise, il permet de générer des rapports et donc des informations d’aide à la décision.
Le terme « famille d’outils » est ici employé, car les éléments qui composent Power BI sont nombreux. Les principaux sont :
–Power Bi Desktop: une application de bureau qui peut être téléchargée gratuitement sur PC. C’est l’outil principal pour le traitement des données et la création de rapports.
–Power bi Service : l’environnement Cloud où les rapports créés avec Power Bi Desktop sont publiés, analysés et partagés. On s’y connecte via un compte Microsoft.
–Power bi Mobile : les rapports peuvent également être analysés via une application pour appareils mobiles (Smartphones et tablettes).
Les utilisateurs de Power BI comprennent à quel point cet outil est incontournable. C’est la raison pour laquelle des cours spécifiques à destination de spécialistes des données et des TIC sont proposés par différents établissements et centres de formation.
Power BI pour les développeurs
Bien que Power BI soit un logiciel gratuit, en tant que service (SaaS), il permet d’analyser des données et de partager des connaissances. Les tableaux de bord Power BI offrent une vue à 360 degrés des métriques les plus importantes en un seul endroit, avec des mises à jour en temps réel et une accessibilité sur tous les appareils.
Une formation Power BI à destination des développeurs consiste à apprendre à utiliser l’outil pour développer des solutions logicielles personnalisées pour les plateformes Power BI et Azure. Au terme de la formation, les étudiants auront acquis les compétences suivantes :
–Configurer des tableaux de bord en temps réel
–Créer des visualisations personnalisées
–Intégrer des analyses riches dans des applications existantes
–Intégrer des rapports interactifs et visuels dans des applications existantes
–Accéder aux données depuis une application
Création de tableaux de bord à l’aide de Microsoft Power BI
Cette formation couvre à la fois Power BI sur le web et Power BI Desktop. Elle s’adresse généralement aux chefs d’entreprise, aux développeurs, aux analystes, aux chefs de projet et aux chefs d’équipe. L’objectif est que les étudiants acquièrent une compréhension de base des sujets ci-dessous, ainsi qu’une capacité à utiliser et à mettre en œuvre les concepts appris.
–Power BI
–Power BI Desktop
–Utilisation de feuilles de calcul CSV, TXT et Excel
–Connexion aux bases de données
–Fusionner, regrouper, résumer et calculer des données
–Création de rapports
Conception du tableau de bord Power BI
Power BI est l’un des outils de visualisation de données les plus populaires et un outil de Business Intelligence. Il propose une collection de connecteurs de bases de données, d’applications et de services logiciels qui sont utilisés pour obtenir des informations de différentes sources de données, les transformer et produire des rapports. Il permet également de les publier pour pouvoir y accéder depuis des appareils mobiles. Mais, cela nécessite la conception de tableaux de bord.
Une formation axée sur la création de tableaux de bord s’adresse aux chefs d’entreprise, aux analystes commerciaux, aux Data Analysts, aux développeurs et aux chefs d’équipe qui souhaitent concevoir un tableau de bord Power BI parfait. À l’issue de cette formation, les participants pourront :
–Concevoir des tableaux de bord beaux et efficaces en suivant les règles critiques
–Choisir les bons graphiques en fonction du type de données à afficher
Data Analytics Process, solutions Cloud et solutions Power BI
Cette formation consiste à avoir une prise en main des solutions Cloud disponibles, des processus d’analyse de données nécessaires pour travailler avec des données dans le Cloud et des outils Power BI pour analyser les données.
L’objectif de la formation est d’apporter aux participants la capacité de :
–Installer et configurer Power BI
–Évaluer les différentes solutions de données offertes par les fournisseurs de cloud tels qu’Azure
–Acquérir une compréhension des différentes structures, approches de modélisation et conceptions de Data Warehouses utilisées pour stocker, gérer et accéder au Big Data.
–Appliquer des outils et des techniques pour nettoyer les données en vue de l’analyse.
–Construire des solutions de reporting et d’analyse basées sur des données sur site et dans le Cloud.
–Intégrer des solutions d’analyse de données à un Data Warehouse
–Atténuer les risques de sécurité des données et assurer la confidentialité des données
Excel vers Power BI
Exporter un fichier Excel vers Power BI est une connaissance essentielle aux Data Analysts qui souhaitent apprendre des techniques pour préparer des données dans Excel, puis les visualiser dans Power BI. Ainsi, ils pourront :
–Comprendre les principes de l’analyse des données, les objectifs de l’analyse des données et les approches de l’analyse des données
–Utiliser les formules DAX dans Power BI pour des calculs complexes
–Mettre en place des visualisations et des graphiques pour des cas d’analyse particuliers
Il existe de nombreux outils appliqués au secteur des entreprises qui, dans bien des cas, facilitent la prise de décision pour les parties prenantes, des chefs de département aux équipes commerciales et jusqu’au Directeur général. Si aujourd’hui, nous manipulons de plus en plus de données et d’informations pour prendre des décisions, nous devons avoir l’aide supplémentaire de la technologie et nous appuyer sur des solutions logicielles d’entreprise pour rationaliser ces tâches.
Les solutions logicielles Microsoft Power BI, qui en Anglais se réfère à Business Intelligence, et que l’on peut traduire par l’intelligence d’affaires. Il s’agit de solutions commerciales qui aideront les responsables des entreprises à accélérer le processus de prise de décision.
La différenciation des entreprises passe par une prise de décision correcte. Aujourd’hui, nous vivons dans une époque entièrement numérique où les décisions doivent reposer sur une base solide d’informations et de données bien contrastées.
BI ou Business Intelligence
Parler de Power BI, c’est parler des services Power BI, c’est-à-dire, de l’ensemble de solutions et des méthodes axées sur l’analyse et la compréhension du Big Data. Ce dernier fait ici référence au grand volume de données qui sont générées à la fois dans les environnements professionnels et personnels, que ce soit par les personnes ou toute autre entité constituée de plusieurs individus.
Tous ces outils sont compilés sous les méthodologies d’un plan d’affaires d’entreprise qui doit se concentrer sur la collecte, l’analyse et la vérification du Big Data afin de développer une trajectoire visuelle et synthétisée.
Si l’on veut vraiment disposer d’une solution logicielle de Business Intelligence, elle doit permettre de faire :
–Des extractions de données volumineuses
–De l’analyse de données en temps réel
–De la création de modèles de données
–Des visualisations de données
–De la création de rapports
À partir de ces lignes directrices, toute entité commerciale doit localiser et travailler sur les incidents qui se sont produits et choisir l’option la plus bénéfique et la plus correcte pour l’entreprise.
Microsoft Power BI pour les entreprises
Power BI est une solution de Business Intelligence présentée par Microsoft. Elle est axée sur les entreprises et les indépendants et permet de disposer à tout moment et en tout lieu de toutes les informations et de la situation de l’entreprise.
En utilisant Power BI, il est possible de créer des rapports et des visualisations personnalisées présentant l’ensemble de l’entreprise. Cela se fait par le biais de tableaux de bord générés par diverses bases de données, l’évolution des projets, le développement commercial et plusieurs autres actions de l’entreprise.
Power BI est l’un des outils de Microsoft qui ont la possibilité d’être localisés dans le Cloud, ce qui permet de connaître de manière rapide les informations les plus importantes des différents panneaux qui sont continuellement mis à jour.
Les données collectées pour cet outil sont produites à partir de sources de données très diverses, y compris à une base de données Microsoft SQL Server.
À travers le programme, on peut développer et connecter des bases de données, configurer l’évolution graphique pour plusieurs objectifs : évaluer l’état de l’entreprise, analyser l’évolution des ventes, connaître le volume des commandes, vérifier les paiements fournisseurs et bien d’autres actions d’analyse, le tout en temps réel.
Une autre nouvelle fonctionnalité de la solution Power BI Desktop est son canevas à partir duquel des onglets peuvent être générés selon les besoins. Cela permet à l’utilisateur de créer sa propre idée, de mieux comprendre, d’interpréter et d’avoir une plus grande capacité d’argumentation lorsque les parties prenantes de l’entreprise devront prendre des décisions sur la base des données.
Et bien sûr, tout cela a l’avantage d’être disponible et opérationnel dans l’environnement de l’informatique en nuage. Le Cloud se chargera d’effectuer et de générer les opérations et les calculs nécessaires pour obtenir les résultats.
Enfin, il faut souligner une autre des caractéristiques des plus attrayantes. Il s’agit de la possibilité de sauvegarder les informations sur ordinateur et ensuite de publier les données et les rapports depuis le site Power BI pour les partager avec d’autres utilisateurs en ligne.
Quels sont les avantages de l’application de Power BI ?
Tous les départements d’une entreprise sont essentiels au bon fonctionnement de celle-ci. Si l’un d’entre eux échoue dans ses objectifs, une chaîne d’échecs se produira. Par conséquent, l’entreprise dans son ensemble en souffrira également. C’est là qu’intervient l’outil Power BI.
Les solutions Microsoft pour entreprises (Power BI, Power Query, Office 365…) permettent la transformation numérique pour un travail beaucoup plus productif. L’outil Power BI permet d’intégrer tous les départements dès sa mise en œuvre.
En effet, il existe 4 avantages pertinents concernant cette solution de Business Intelligence :
–Accessibilité : les bases de données et les services Power BI sont à la fois accessibles dans le Cloud et sur Desktop.
–Informations mises à jour en temps réel : lorsque des problèmes ou des opportunités sont détectés instantanément, une plus grande optimisation du fonctionnement de l’entreprise est obtenue. Avec Power BI, cette détection et cette identification se font en temps réel.
–Interface intuitive : les informations sont claires et hiérarchisées et proviennent depuis tous les départements de l’entreprise. Elles sont également intuitives pour garantir une accessibilité complète à tout utilisateur.
–Agilité : de par sa conception, sa stratégie d’organisation et sa hiérarchie, Power BI permet une restitution détaillée des informations autant de fois que nécessaire. La mise à jour se fait en temps réel.
En conclusion, Microsoft Power Bi est une application intelligente et prédictive qui est un grand encouragement pour les entreprises et leurs dirigeants lorsqu’il s’agit d’interpréter et d’analyser toutes les informations. Il permet d’interpréter tous types de données et de les afficher dans des graphiques totalement compréhensibles par tous. D’ailleurs, Power BI a encore une fois été élue meilleure plateforme d’analyse de données et de Business Intelligence dans le Magic Quadrant de Gartner.
Microsoft Power BI est une famille d’outils de Business Intelligence. À partir des données d’une entreprise, il permet de générer des rapports et donc des informations d’aide à la décision.
Le terme « famille d’outils » est ici employé, car les éléments qui composent Power BI sont nombreux. Les principaux sont :
–Power BI Desktop: une application de bureau qui peut être téléchargée gratuitement sur PC. C’est l’outil principal pour le traitement des données et la création de rapports.
–Power BI Service : l’environnement Cloud où les rapports créés avec Power BI Desktop sont publiés, analysés et partagés. On s’y connecte via un compte Microsoft.
–Power BI Mobile : les rapports peuvent également être analysés via une application pour appareils mobiles (Smartphones et tablettes).
Les utilisateurs de Power BI comprennent à quel point cet outil est incontournable. C’est la raison pour laquelle des cours spécifiques à destination de spécialistes des données et des TIC sont proposés par différents établissements et centres de formation.
Power BI pour les développeurs
Bien que Power BI soit un logiciel gratuit, en tant que service (SaaS), il permet d’analyser des données et de partager des connaissances. Les tableaux de bord Power BI offrent une vue à 360 degrés des métriques les plus importantes en un seul endroit, avec des mises à jour en temps réel et une accessibilité sur tous les appareils.
Une formation Power BI à destination des développeurs consiste à apprendre à utiliser l’outil pour développer des solutions logicielles personnalisées pour les plateformes Power BI et Azure. Au terme de la formation, les étudiants auront acquis les compétences suivantes :
–Configurer des tableaux de bord en temps réel
–Créer des visualisations personnalisées
–Intégrer des analyses riches dans des applications existantes
–Intégrer des rapports interactifs et visuels dans des applications existantes
–Accéder aux données depuis une application
Création de tableaux de bord à l’aide de Microsoft Power BI
Cette formation couvre à la fois Power BI sur le web et Power BI Desktop. Elle s’adresse généralement aux chefs d’entreprise, aux développeurs, aux analystes, aux chefs de projet et aux chefs d’équipe. L’objectif est que les étudiants acquièrent une compréhension de base des sujets ci-dessous, ainsi qu’une capacité à utiliser et à mettre en œuvre les concepts appris.
–Power BI
–Power BI Desktop
–Utilisation de feuilles de calcul CSV, TXT et Excel
–Connexion aux bases de données
–Fusionner, regrouper, résumer et calculer des données
–Création de rapports
Conception du tableau de bord Power BI
Power BI est l’un des outils de visualisation de données les plus populaires et un outil de Business Intelligence. Il propose une collection de connecteurs de bases de données, d’applications et de services logiciels qui sont utilisés pour obtenir des informations de différentes sources de données, les transformer et produire des rapports. Il permet également de les publier pour pouvoir y accéder depuis des appareils mobiles. Mais, cela nécessite la conception de tableaux de bord.
Une formation axée sur la création de tableaux de bord s’adresse aux chefs d’entreprise, aux analystes commerciaux, aux Data Analysts, aux développeurs et aux chefs d’équipe qui souhaitent concevoir un tableau de bord Power BI parfait. À l’issue de cette formation, les participants pourront :
–Concevoir des tableaux de bord beaux et efficaces en suivant les règles critiques
–Choisir les bons graphiques en fonction du type de données à afficher
Data Analytics Process, solutions Cloud et solutions Power BI
Cette formation consiste à avoir une prise en main des solutions Cloud disponibles, des processus d’analyse de données nécessaires pour travailler avec des données dans le Cloud et des outils Power BI pour analyser les données.
L’objectif de la formation est d’apporter aux participants la capacité de :
–Installer et configurer Power BI
–Évaluer les différentes solutions de données offertes par les fournisseurs de cloud tels qu’Azure
–Acquérir une compréhension des différentes structures, approches de modélisation et conceptions de Data Warehouses utilisées pour stocker, gérer et accéder au Big Data.
–Appliquer des outils et des techniques pour nettoyer les données en vue de l’analyse.
–Construire des solutions de reporting et d’analyse basées sur des données sur site et dans le Cloud.
–Intégrer des solutions d’analyse de données à un Data Warehouse
–Atténuer les risques de sécurité des données et assurer la confidentialité des données
Excel vers Power BI
Exporter un fichier Excel vers Power BI est une connaissance essentielle aux Data Analysts qui souhaitent apprendre des techniques pour préparer des données dans Excel, puis les visualiser dans Power BI. Ainsi, ils pourront :
–Comprendre les principes de l’analyse des données, les objectifs de l’analyse des données et les approches de l’analyse des données
–Utiliser les formules DAX dans Power BI pour des calculs complexes
–Mettre en place des visualisations et des graphiques pour des cas d’analyse particuliers
Azure est un service de Cloud Computing par abonnement mensuel créé par Microsoft en 2010. Les services Cloud de Microsoft incluent l’hébergement Web, les machines virtuelles, les services d’applications, le stockage de fichiers, la gestion des données, l’analyse et bien plus encore. Ils sont hébergés dans plus de 35 régions de centres de données à travers le monde. Azure propose des solutions de gestion et de traitement du Big Data basées sur le Cloud, notamment l’apprentissage automatique, l’analyse en continu et les services d’IA qui peuvent tous être gérés à partir du portail Azure central.
Obtenir l’un des Azure Certifications est un laissez-passer vers les postes parmi les plus rémunérés. Les organisations de tous horizons tendent progressivement à opter pour le Cloud Computing, une solution économe, sécuritaire, fiable et performante. En ce sens, se former à Microsoft Azure est une opportunité de carrière et une ouverture sur l’avenir du Cloud en entreprise.
Quelles sont les utilisations de Microsoft Azure ?
Azure est un service de Cloud Computing très populaire avec de nombreux produits et applications, ce qui entraîne une forte demande d’employés capables de concevoir, de déployer et de gérer des solutions Azure.
Pour illustrer son importance, Indeed a répertorié plus de 500 postes Azure disponibles avec des estimations de salaire de 75 000 euros et plus. Les postes incluent Azure Developer, Azure Consultant, Azure Architect, Azure Cloud Administrator, Azure Engineer et plus encore, y compris de nombreux postes chez Microsoft.
Construire sa propre expertise Azure peut considérablement améliorer son CV et optimiser ses chances d’entrer dans le monde passionnant du Cloud Computing.
Quels sont les avantages du Cloud Computing Azure ?
L’apprentissage automatique est un avantage pour l’utilisation des Azure services Cloud dans une entreprise. Azure Machine Learning devient plus intelligent à mesure que les utilisateurs font appel à ses services. La reconnaissance de noms, l’extraction intelligente de fichiers avec un ensemble de mots-clés… font tous partie de l’apprentissage automatique. Les services Cloud avec la Machine Learning récupèrent rapidement les données afin que les entreprises puissent profiter de ce type de service à la demande.
Les machines virtuelles et les réseaux virtuels permettent d’exécuter des tâches de mémoire lourdes. Au lieu d’investir sur des ordinateurs plus importants et plus puissants pour exécuter des tâches, les entreprises font appel à des experts en Azure capables de créer une machine virtuelle qui utilise le Cloud pour exécuter leurs tâches. Ce type d’avantage peut leur permettre d’économiser chaque année de l’argent qui aurait été dépensé en matériel physique.
Un autre avantage des services Cloud est la possibilité d’utiliser des applications mobiles et Office 365 avec Azure. Avec le travail mobile d’aujourd’hui, il est facile d’accéder à des données critiques via des applications mobiles n’importe où et n’importe quand. Ainsi, grâce à l’intégration Azure et des solutions Cloud dans une entreprise, cette dernière s’appuiera moins sur un ordinateur spécifique pour charger des documents.
Qui doit suivre cette formation Azure Certification ?
Le mot « Cloud » a influencé la croissance de la carrière de nombreuses personnes et aujourd’hui experts Azure qui ont été auparavant des développeurs, des administrateurs système, des Ingénieurs de données, des Scientifiques de données et même des responsables informatiques.
Azure devient une compétence indispensable pour les professionnels de l’informatique, car des compétences en matière de Cloud Azure sont précieuses pour une entreprise cherchant à analyser, évaluer, gérer, adapter et optimiser l’offre et le coût de l’infrastructure informatique.
Étant donné que Microsoft Azure est open source, hybride et sécurisé, il propose une plate-forme Cloud en constante expansion qui dispose d’un réseau mondial massif pour les futures activités d’une organisation.
Une formation certifiante Mastering Microsoft Azure, permettant aux candidats de passer le Microsoft Certification Exam, est destinée aux professionnels de l’informatique qui veulent poursuivre une carrière dans le Cloud Computing et devenir Microsoft Azure Developer Specialist. Elle convient parfaitement aux :
–Professionnels de l’informatique
–Développeurs d’applications
–Data Engineers
–Data Scientists
–Solutions architect
–Ingénieurs DevOps
Quels sont les postes proposés par les entreprises aux professionnels Azure ?
Le développement d’applications basées sur le Cloud se développe à un rythme rapide. Les compétences et l’expérience d’Azure peuvent aider ceux qui suivent une formation Azure à s’orienter vers une carrière lucrative.
Certains des postes proposés par les entreprises pour les professionnels Azure sont :
–Développeur d’applications Cloud : se concentre principalement sur la mise en œuvre et la maintenance de l’infrastructure Cloud d’une organisation
–Cloud Architect: responsable de la gestion de l’architecture du Cloud Computing dans une organisation
–Ingénieur infrastructure Cloud Automation : se concentre sur l’automatisation, l’orchestration et l’intégration du Cloud
–Ingénieur Cloud système réseaux : responsable de la mise en œuvre, de la maintenance et de la prise en charge du matériel réseau, des logiciels et des liens de communication de l’infrastructure Cloud de l’organisation
Quelle est la future portée de la formation Azure ?
Microsoft Azure est une plate-forme de Cloud Computing publique qui propose de la rapidité en réduisant le temps de chargement grâce à Azure Content Delivery Network. Il s’agit d’un atout qui attire de plus en plus d’entreprises à faire appel à ses solutions telles que l’infrastructure en tant que service, le logiciel en tant que service et une plate-forme en tant que service. Ils peuvent être utilisés efficacement pour des services tels que l’analyse, la mise en réseau, le stockage, l’informatique virtuelle et bien d’autres services.
La portée future d’Azure semble assez prometteuse si elle est vue du point de vue de l’investissement. En mars 2021, Microsoft a investi 200 millions de dollars à proximité de la ville de Chicago. Ce sera un complexe de 11 data centers qui s’étendront sur 21 hectares. Ils seront opérationnels en 2022 pour répondre à la hausse de la demande.
Pourquoi suivre une formation Azure ?
Le Cloud Microsoft Azure connaît une croissance exponentielle. Selon le rapport Microsoft, 57 % des entreprises du Fortune 500 utilisent le Cloud Azure. En 2020, la hausse des revenus générés par Microsoft Azure a été projetée à 57,6 %. Et malgré la pandémie de Covid19, elle a tout de même été à 29 %.
Microsoft Azure est énorme. Il y a eu une croissance de 50 % de ses revenus pour l’année 2021. En tout, cette plateforme de Cloud Computing a généré près de 15,1 milliards de dollars de chiffre d’affaires.
Quels sont les cours généralement dispensés dans une formation Azure (Learning Path) ?
D’un établissement à un autre, une formation Azure est généralement la même. Ci-dessous une liste non exhaustive des cours :
–Fondamentaux de Microsoft Azure (Course)
–Analyse de données avec Microsoft Azure
–Technologies de sécurité Microsoft Azure
–Développement de solutions pour Microsoft Azure
–Conception et mise en œuvre de solutions Microsoft DevOps
–Ingénierie des données sur Microsoft Azure
–Administration de bases de données relationnelles sur Microsoft Azure
–Migration des charges de travail SQL vers Azure
–Migration des charges de travail NoSQL vers Azure Cosmos DB
–Implémentation des solutions Microsoft Azure Cosmos DB
–Migration des charges de travail d’application vers Azure
Le convolutional neural network est une forme spéciale du réseau neuronal artificiel. Il comporte plusieurs couches de convolution et est très bien adapté à l’apprentissage automatique et aux applications avec Intelligence artificielle (IA) dans le domaine de la reconnaissance d’images et de la parole, de la vente et du marketing ciblé et bien plus encore.
Introduction au convolutional neural network
L’appellation convolutional neural network signifie « réseau neuronal convolutif » en Français. L’abréviation est CNN. Il s’agit d’une structure particulière d’un réseau de neurones artificiels spécialement conçu pour l’apprentissage automatique et le traitement d’images ou de données audio.
Dans une certaine mesure, son fonctionnement est calqué sur les processus biologiques derrières les réflexions du cerveau humain. La structure est similaire à celle du cortex visuel d’un cerveau. Le convolutional neural network se compose de plusieurs couches. La formation d’un réseau de neurones convolutifs se déroule généralement de manière supervisée. L’un des fondateurs du réseau de neurones convolutifs est Yann Le Cun.
Mise en place d’un convolutional neural network
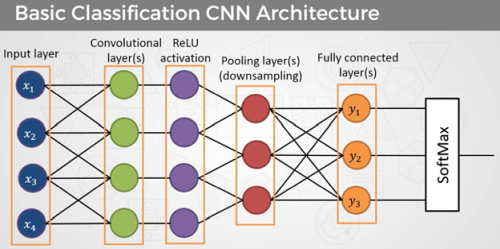
Des neurones selon une structure entièrement ou partiellement maillés à plusieurs niveaux composent les réseaux de neurones conventionnels. Ces structures atteignent leurs limites lors du traitement d’images, car il faudrait disposer d’un nombre d’entrées correspondant au nombre de pixels. Le nombre de couches et les connexions entre elles seraient énormes et ne seraient gérables que par des ordinateurs très puissants. Différentes couches composent un réseau neuronal convolutif. Son principe de base est un réseau neuronal à propagation avant ou feedforward neural network partiellement maillé.
Les couches individuelles de CNN sont :
Convolutional layers ou couches de convolution (CONV)
Pooling layers ou couches de Pooling (POOL)
ReLU layers ou couches d’activation ReLU (Rectified Linear Units)
Fully Connected layers ou couches Fully Connected (FC)
La couche de Pooling suit la couche de convolution et cette combinaison peut être présente plusieurs fois l’une derrière l’autre. La couche de Pooling et la couche de convolution étant des sous-réseaux maillés localement, le nombre de connexions dans ces couches reste limité et dans un cadre gérable, même avec de grandes quantités d’entrées. Une couche Fully Connected forme la fin de la structure.
Les tâches individuelles de chacune des couches
La couche de convolution est le plan de pliage réel. Elle est capable de reconnaître et d’extraire des caractéristiques individuelles dans les données d’entrée. Dans le traitement d’image, il peut s’agir de caractéristiques telles que des lignes, des bords ou certaines formes. Les données d’entrée sont traitées sous la forme d’une matrice. Pour ce faire, on utilise des matrices d’une taille définie (largeur x hauteur x canaux).
La couche de Pooling se condense et réduit la résolution des entités reconnues. À cette fin, elle utilise des méthodes telles que la mise en commun maximale ou la mise en commun de la valeur moyenne. La mise en commun élimine les informations inutiles et réduit la quantité de données. Cela ne réduit pas les performances du Machine Learning. Au contraire, la vitesse de calcul augmente en raison du volume de données réduit.
La couche d’activation ReLU permet un entraînement plus rapide et plus efficace en définissant les valeurs négatives sur zéro et en conservant les valeurs positives. Seules les fonctionnalités activées passent à la couche suivante.
La couche Fully Connected forme la fin d’un convolutional neural network CNN. Elle rejoint les séquences répétées des couches de convolution et de Pooling. Toutes les caractéristiques et tous les éléments des couches en amont sont liés à chaque caractéristique de sortie. Les neurones entièrement connectés peuvent être disposés dans plusieurs plans. Le nombre de neurones dépend des classes ou des objets que le réseau de neurones doit distinguer.
La méthode de travail à l’exemple de la reconnaissance d’image
Un CNN peut avoir des dizaines ou des centaines de couches qui apprennent à détecter différentes caractéristiques d’une image. Les filtres sont appliqués à chaque image d’apprentissage à différentes résolutions. La sortie de chaque image alambiquée est utilisée comme entrée pour la couche suivante. Les filtres peuvent aller de caractéristiques très simples telles que la luminosité et les contours à des caractéristiques plus complexes comme des spécificités qui définissent l’objet de manière unique.
Fonctionnalités d’apprentissage
Comme d’autres réseaux de neurones, une couche d’entrée, d’une couche de sortie et de nombreuses couches intermédiaires cachées composent un CNN. Ces couches effectuent des opérations qui modifient les données afin d’apprendre les caractéristiques spécifiques de ces données. Ces opérations se répètent en dizaines ou centaines de couches. Ainsi, chaque couche apprenne à identifier des caractéristiques différentes.
Poids partagé et valeurs de biais
Comme un réseau de neurones traditionnel, un CNN se compose de neurones avec des poids et des biais. Le modèle apprend ces valeurs au cours du processus de formation et les met continuellement à jour à chaque nouvel exemple de formation. Cependant, dans le cas des CNN, les valeurs des poids et des biais sont les mêmes pour tous les neurones cachés dans une couche spécifique.
Cela signifie que tous les neurones cachés détectent la même caractéristique telle qu’une bordure ou un point dans différentes régions de l’image. Cela permet au réseau de tolérer la traduction d’objets dans une image. Par exemple, un réseau formé à la reconnaissance des voitures pourra le faire partout où la voiture se trouve sur l’image.
Couches de classification
Après avoir appris les fonctionnalités multicouches, l’architecture d’un CNN passe à la classification. L’avant-dernière couche est entièrement connectée et produit un vecteur K-dimensionnel. Ici, K est le nombre de classes que le réseau pourra prédire. Ce vecteur contient les probabilités pour chaque classe de toute image classée. La couche finale de l’architecture CNN utilise une couche de classification pour fournir la sortie de classification.
Avantages d’un CNN dans le domaine de la reconnaissance d’images
Comparé aux réseaux neuronaux conventionnels, le CNN offre de nombreux avantages :
Il convient aux applications d’apprentissage automatique et d’Intelligence artificielle avec de grandes quantités de données d’entrée telles que la reconnaissance d’images.
Le réseau fonctionne de manière robuste et est insensible à la distorsion ou à d’autres changements optiques.
Il peut traiter des images enregistrées dans différentes conditions d’éclairage et dans différentes perspectives. Les caractéristiques typiques d’une image sont ainsi facilement identifiées.
Il nécessite beaucoup moins d’espace de stockage que les réseaux de neurones entièrement maillés. Le CNN est divisé en plusieurs couches locales partiellement maillées. Les couches de convolution réduisent considérablement les besoins de stockage.
Le temps de formation d’un CNN est également considérablement réduit. Grâce à l’utilisation de processeurs graphiques modernes, les CNN peuvent être formés de manière très efficace.
Il est la technologie de pointe pour le Deep Learning et la classification dans la reconnaissance d’images (image recognition).
Application d’un CNN dans le domaine du marketing
Le CNN est présent dans divers domaines depuis ces dernières années. La biologie l’utilise principalement pour en savoir plus sur le cerveau. En médecine, il fonctionne parfaitement pour la prédiction de tumeurs ou d’anomalies ainsi que pour l’élaboration de diagnostics complexes et de traitements à suivre en fonction des symptômes. Un autre domaine dans lequel il est couramment utilisé est celui de l’environnement. Il permet d’analyser les tendances et les modèles ou les prévisions météorologiques. Dans le domaine de la finance, il est couramment utilisé dans tout ce qui concerne la prévision de l’évolution des prix, l’évaluation ou l’identification du risque de contrefaçon.
Un CNN a de ce fait une application directe dans de nombreux domaines. Et pour faire face à l’accroissement de la quantité de données disponibles, il est également utilisé dans le marketing. En effet, dans le domaine des affaires et plus particulièrement en marketing, il a plusieurs usages :
Prédiction des ventes
Identification des modèles de comportement
Reconnaissance des caractères écrits
Prédiction du comportement des consommateurs
Personnalisation des stratégies marketing
Création et compréhension des segments d’acheteurs plus sophistiqués
Automatisation des activités marketing
Création de contenu
De toutes ses utilisations, la plus grande se trouve dans l’analyse prédictive. Le CNN aide les spécialistes du marketing à faire des prédictions sur le résultat d’une campagne, en reconnaissant les tendances des campagnes précédentes.
Actuellement, avec l’apparition du Big Data, cette technologie est vraiment utile pour le marketing. Les entreprises ont accès à beaucoup données. Grâce au travail de leur équipe experte dans la data science (data scientist, data analyst, data engineer), le développement de modèles prédictifs est beaucoup plus simple et précis. Les spécialistes du marketing pourront ainsi mieux ciblés les prospects alignés sur leurs objectifs.
Jusqu’à présent, les données sont la meilleure source de connaissances pour les entreprises. En effet, elles en génèrent plus que jamais, d’où l’apparition du terme Big Data. Cependant, accumuler de telles quantités d’informations numériques à très peu d’utilité à moins que ces organisations en comprennent le sens. C’est là qu’interviennent les logiciels de Business Intelligence en self-service tels que Power BI.
Qu’est-ce que Power BI ?
Power BI est le nom commun attribué à une variété d’applications et de services basés sur le Cloud. Ces derniers sont conçus pour aider les entreprises à collecter, gérer et analyser diverses sources de données via une interface facile à utiliser. Il permet de rassembler les données et de les traiter. Mais surtout, il est utile pour transformer les données en informations intelligibles souvent à l’aide de graphiques et de tableaux visuellement précis et faciles à traiter. Cela permet aux utilisateurs de créer des rapports interactifs et de les partager à toutes les parties prenantes d’une entreprise.
Cette application Microsoft se connecte à une variété de sources de données. Il peut s’agir de feuilles de calcul Excel ou de bases de données sur un data warehouse. Il peut également se connecter à des applications à la fois dans le Cloud et sur les serveurs de l’entreprise.
Cette appellation est un terme général et peut faire référence à une application de bureau Windows appelée Power BI Desktop. Il peut s’agir d’un outil ETL (Extract, Transform and Load) dénommé Power Query ou d’un service en ligne SaaS (Software as a Service) appelé Power BI Service. Il peut aussi s’agir d’applications mobiles Power BI pour les Smartphones et tablettes Windows ainsi que pour les appareils iOS et Android.
Power BI est basé sur Microsoft Excel. En tant que tel, la courbe d’apprentissage d’Excel vers Power BI n’est pas si raide. Quiconque peut utiliser Excel peut utiliser Power BI. Mais, ce dernier est beaucoup plus puissant que la feuille de calcul.
Que fait cette application d’analyse de données ?
Dans tout environnement d’entreprise, il est essentiel d’unifier toutes les informations disponibles autour d’une même plateforme que ce soit dans le Cloud ou en local. Pour ce faire, Power BI est l’outil idéal. Il permet d’appliquer les connaissances de la Business Intelligence (BI) en exploitant des données en temps réel provenant de différentes sources et en créant des rapports. Sur un simple tableau de bord se trouvent les résultats de tous les éléments à analyser et partager entre plusieurs professionnels d’une même entreprise.
En effet, cette application d’analyse de données est utilisée pour la création de rapports basés sur les données de l’entreprise. En utilisant Power BI, l’utilisateur peut se connecter à un large éventail d’ensembles de données et classer les informations fournies par le biais de la data visualisation afin qu’elles puissent être mieux comprises et assimilées. Le tableau de bord généré à partir de ces données peut être partagé avec d’autres utilisateurs.
Power BI aide les entreprises à voir non seulement ce qui s’est déroulé dans le passé et ce qui se passe dans le présent, mais également ce qui pourrait se produire dans le futur. Cet outil d’analyse de données est doté de fonctionnalités d’apprentissage automatique. Il permet ainsi à son utilisateur de détecter un modèle de données et d’utiliser ce modèle pour effectuer des prédictions éclairées et exécuter des scénarios de simulation. Ces estimations permettent à l’entreprise pour laquelle il travaille de générer des prévisions. Elle aura ainsi la capacité de se préparer à répondre à la demande future et à adopter des mesures clés.
6 raisons d’utiliser Power BI
Pour les entreprises qui souhaitent plus de puissance de reporting et de force analytique que ce qu’offre Excel, Power BI est à un tout autre niveau du Business Intelligence. Avec cet outil, les entreprises peuvent collecter, analyser et visualiser l’ensemble de leurs données, ce qui leur donne un meilleur aperçu de leur productivité et de leur compétitivité. Ainsi, elles peuvent prendre des décisions plus éclairées basées sur des données réelles.
Pour mieux comprendre la puissance de Power Bi, voici quelques-uns de ses principaux avantages :
Les entreprises peuvent gérer de grandes quantités de données via cette application qu’en utilisant d’autres plateformes d’analyse de données.
Les informations peuvent être visualisées à l’aide de modèles afin que les entreprises puissent mieux comprendre leurs données.
Il est basé sur le service Cloud de sorte que les utilisateurs bénéficient de capacités d’intelligence de pointe et d’algorithmes puissants régulièrement mis à jour.
Plusieurs personnalisations permettent aux utilisateurs de créer des tableaux de bord afin d’accéder rapidement aux données dont ils ont besoin.
Il propose une interface intuitive qui le rend beaucoup plus facile à utiliser que les feuilles de calcul complexes.
Il garantit la sécurité des données en offrant des contrôles d’accessibilité internes et externes.
Pour résumer, Power BI est la solution professionnelle pour visualiser et transformer les données. Mais, il sert surtout à partager des informations avec tous les services de l’entreprise, de manière efficace et rapide. Grâce à ses tableaux de bord intuitifs et à son contrôle d’accessibilité, tout le monde dispose d’informations en temps réel. Toutes les parties prenantes pourront les consulter à tout moment et en tout lieu.
L’analyse des données pour soutenir la prise de décision
Power BI est l’un des plus pratiques et performants outils Microsoft pour l’analyse de données. Il s’est imposé comme le leader du secteur. Il reflète d’ailleurs les connaissances et l’expérience de Microsoft dans ce domaine à travers des solutions telles qu’Excel ou SQL Server et ses compléments (SSAS, SSIS et SSRS).
Power BI facilite la transformation des données en informations grâce à des modèles analytiques. Cela va de l’information à la connaissance en passant par des rapports analytiques avec des graphiques, des tableaux, etc. L’objectif de Microsoft est d’offrir un outil de prise de décisions intelligentes en réduisant les risques. Il apporte une réponse efficace aux besoins d’un des professionnels qui interviennent dans ce domaine : le data analyst.
À part cela, Power Bi est également un outil multiplateforme pour la surveillance de l’entreprise en temps réel par les parties prenantes partout et à tout moment.
L’autreatout de Power BI dans l’analyse des données est son intégration totale avec la suite Office 365. Il donne accès à SharePoint, à un calendrier, à Microsoft Flow pour les flux de travail et à une longue liste de fonctionnalités et de possibilités sans quitter l’environnement Office 365.
Par ailleurs, Microsoft s’est fortement engagé envers les techniques d’apprentissage automatique. Power BI offre de multiples fonctionnalités dans ce domaine :
L’analyse automatique des informations
Le calcul des corrélations
L’identification de valeurs aberrantes
Le regroupement
L’intégration de Python pour l’importation de données et la création de graphiques
Nous sommes actuellement à un stade où l’on cherche à ce que les machines soient dotées d’une plus grande intelligence, atteignent une pensée autonome et une grande capacité d’apprentissage. Le deep learning ou apprentissage en profondeur est un concept relativement nouveau allant dans cette perspective. Il est étroitement lié à l’intelligence artificielle (IA) et fait partie des approches algorithmiques d’apprentissage automatique.
Qu’est-ce que le deep learning ?
Le deep learning ou apprentissage profond est défini comme un ensemble d’algorithmes qui se compose d’un réseau de neurones artificiels capables d’apprendre, s’inspirant du réseau de neurones du cerveau humain. En ce sens, il est considéré comme un sous-domaine de l’apprentissage automatique. L’apprentissage profond est lié aux modèles de communication d’un cerveau biologique, ce qui lui permet de structurer et de traiter les informations.
L’une des principales caractéristiques de l’apprentissage profond est qu’il permet d’apprendre à différents niveaux d’abstraction. Autrement dit, l’utilisateur peut hiérarchiser les informations en concepts. De même, une cascade de couches de neurones est utilisée pour l’extraction et la transformation des informations.
Le deep learning peut apprendre de deux manières : l’apprentissage supervisé et l’apprentissage non supervisé. Cela permet au processus d’être beaucoup plus rapide et plus précis. Dans certains cas, l’apprentissage profond est connu sous le nom d’apprentissage neuronal profond ou de réseaux neuronaux profonds. En effet, la définition la plus précise est que l’apprentissage profond imite le fonctionnement du cerveau humain.
Grâce à l’ère du Cloud Computing et du Big Data, le deep learning a connu une croissance significative. Avec lui, un haut niveau de précision a été atteint. Et cela a causé tellement d’étonnements, car il se rapproche chaque jour de la puissance perceptive d’un être humain.
Le deep learning fonctionne grâce à des réseaux de neurones profonds. Il utilise un grand nombre de processeurs fonctionnant en parallèle.
Les réseaux de neurones sont regroupés en trois couches différentes : couche d’entrée, couche cachée et couche de sortie. La première couche, comme son nom l’indique, reçoit les données d’entrée. Ces informations sont transmises aux couches cachées qui effectuent des calculs mathématiques permettant d’établir de nouvelles entrées. Enfin, la couche de sortie est chargée de fournir un résultat.
Mais, les réseaux de neurones ne fonctionnent pas si on ne tient pas compte de deux facteurs. Le premier est qu’il faut beaucoup de puissance de calcul. Le second fait référence au gigantesque volume de données auquel ils doivent accéder pour s’entraîner.
Pour sa part, les réseaux de neurones artificiels peuvent être entraînés à l’aide d’une technique appelée rétropropagation. Elle consiste à modifier les poids des neurones pour qu’ils donnent un résultat exact. En ce sens, ils sont modifiés en fonction de l’erreur obtenue et de la participation de chaque neurone.
Pour son bon fonctionnement, l’utilisation d’un processeur graphique est également importante. Autrement dit, un GPU dédié est utilisé pour le traitement graphique ou les opérations en virgule flottante. Pour traiter un tel processus, l’ordinateur doit être super puissant afin de pouvoir fonctionner avec un minimum de marge d’erreur.
L’apprentissage en profondeur a permis de produire de meilleurs résultats dans les tâches de perception informatique, car il imite les caractéristiques architecturales du système nerveux. En fait, ces avancées peuvent lui permettre d’intégrer des fonctions telles que la mémoire sémantique, l’attention et le raisonnement. L’objectif est que le niveau d’intelligence artificielle soit équivalent au niveau d’intelligence humain, voire le dépasser grâce à l’innovation technologique.
Quelles sont les applications du deep learning dans l’analyse du Big Data ?
Le deep learning dans l’analyse du Big Data est devenu une priorité de la science des données. On peut en effet identifier trois applications.
Indexation sémantique
La recherche d’informations est une tâche clé de l’analyse du Big Data. Le stockage et la récupération efficaces des informations sont un problème croissant. Les données en grande quantité telles que des textes, des images, des vidéos et des fichiers audio sont collectées dans divers domaines. Par conséquent, les stratégies et solutions qui étaient auparavant utilisées pour le stockage et la récupération d’informations sont remises en question par ce volume massif de données.
L’indexation sémantique s’avère être une technique efficace, car elle facilite la découverte et la compréhension des connaissances. Ainsi, les moteurs de recherche ont la capacité de fonctionner plus rapidement et plus efficacement.
Effectuer des tâches discriminantes
Tout en effectuant des tâches discriminantes dans l’analyse du Big Data, les algorithmes d’apprentissage permettent aux utilisateurs d’extraire des fonctionnalités non linéaires compliquées à partir des données brutes. Il facilite également l’utilisation de modèles linéaires pour effectuer des tâches discriminantes en utilisant les caractéristiques extraites en entrée.
Cette approche présente deux avantages. Premièrement, l’extraction de fonctionnalités avec le deep learning ajoute de la non-linéarité à l’analyse des données, associant ainsi étroitement les tâches discriminantes à l’IA. Deuxièmement, l’application de modèles analytiques linéaires sur les fonctionnalités extraites est plus efficace en termes de calcul. Ces deux avantages sont importants pour le Big Data, car ils permettent d’accomplir des tâches complexes comme la reconnaissance faciale dans les images, la compréhension de millions d’images, etc.
Balisage d’images et de vidéos sémantiques
Les mécanismes d’apprentissage profond peuvent faciliter la segmentation et l’annotation des scènes d’images complexes. Le deep learning peut également être utilisé pour la reconnaissance de scènes d’action ainsi que pour le balisage de données vidéo. Il utilise une analyse de la variable indépendante pour apprendre les caractéristiques spatio-temporelles invariantes à partir de données vidéo. Cette approche aide à extraire des fonctionnalités utiles pour effectuer des tâches discriminantes sur des données d’image et vidéo.
Le deep learning a réussi à produire des résultats remarquables dans l’extraction de fonctionnalités utiles. Cependant, il reste encore un travail considérable à faire pour une exploration plus approfondie qui comprend la détermination d’objectifs appropriés dans l’apprentissage de bonnes représentations de données et l’exécution d’autres tâches complexes dans l’analyse du Big Data.
La Computer Vision ou vision par ordinateur est une technologie d’intelligence artificielle permettant aux machines d’imiter la vision humaine. Découvrez tout ce que vous devez savoir : définition, fonctionnement, histoire, applications, formations…
Depuis maintenant plusieurs années, nous sommes entrés dans l’ère de l’image. Nos smartphones sont équipés de caméras haute définition, et nous capturons sans cesse des photos et des vidéos que nous partageons au monde entier sur les réseaux sociaux.
Les services d’hébergement vidéo comme YouTube connaissent une popularité explosive, et des centaines d’heures de vidéo sont mises en ligne et visionnées chaque minute. Ainsi, l’internet est désormais composé aussi bien de texte que d’images.
Toutefois, s’il est relativement simple d’indexer les textes et de les explorer avec des moteurs de recherche tels que Google, la tâche est bien plus difficile en ce qui concerne les images. Pour les indexer et permettre de les parcourir, les algorithmes ont besoin de connaître leur contenu.
Pendant très longtemps, la seule façon de présenter le contenu d’une image aux ordinateurs était de renseigner sa méta-description lors de la mise en ligne. Désormais, grâce à la technologie de » vision par ordinateur » (Computer Vision), les machines sont en mesure de » voir « les images et de comprendre leur contenu.
Qu’est ce que la vision par ordinateur ?
La Computer Vision peut être décrite comme un domaine de recherche ayant pour but de permettre aux ordinateurs de voir. De façon concrète, l’idée est de transmettre à une machine des informations sur le monde réel à partir des données d’une image observée.
Pour le cerveau humain, la vision est naturelle. Même un enfant est capable de décrire le contenu d’une photo, de résumer une vidéo ou de reconnaître un visage après les avoir vus une seule fois. Le but de la vision par ordinateur est de transmettre cette capacité humaine aux ordinateurs.
Il s’agit d’un vaste champ pluridisciplinaire, pouvant être considéré comme une branche de l’intelligence artificielle et du Machine Learning. Toutefois, il est aussi possible d’utiliser des méthodes spécialisées et des algorithmes d’apprentissage général n’étant pas nécessairement liés à l’intelligence artificielle.
De nombreuses techniques en provenance de différents domaines de science et d’ingénierie peuvent être exploitées. Certaines tâches de vision peuvent être accomplies à l’aide d’une méthode statistique relativement simple, d’autres nécessiteront de vastes ensembles d’algorithmes de Machine Learning complexes.
En 1966, les pionniers de l’intelligence artificielleSeymour Papert et Marvin Minsky lance le Summer Vision Project : une initiative de deux mois, rassemblant 10 hommes dans le but de créer un ordinateur capable d’identifier les objets dans des images.
Pour atteindre cet objectif, il était nécessaire de créer un logiciel capable de reconnaître un objet à partir des pixels qui le composent. À l’époque, l’IA symbolique – ou IA basée sur les règles – était la branche prédominante de l’intelligence artificielle.
Les programmeurs informatiques devaient spécifiermanuellement les règles de détection d’objets dans les images. Or, cette approche pose problème puisque les objets dans les images peuvent apparaître sous différents angles et différents éclairages. Ils peuvent aussi être altérés par l’arrière-plan, ou obstrués par d’autres objets.
Les valeurs de pixels variaient donc fortement en fonction de nombreux facteurs, et il était tout simplement impossible de créer des règlesmanuellement pour chaque situation possible. Ce projet se heurta donc aux limites techniques de l’époque.
Quelques années plus tard, en 1979, le scientifique japonais Kunihiko Fukushima créa un système de vision par ordinateur appelé » neocognitron « en se basant sur les études neuroscientifiques menées sur le cortex visuel humain. Même si ce système échoua à effectuer des tâches visuelles complexes, il posa les bases de l’avancée la plus importante dans le domaine de la Computer Vision…
La révolution du Deep Learning
La Computer Vision n’est pas une nouveauté, mais ce domaine scientifique a récemment pris son envol grâce aux progrès effectués dans les technologies d’intelligence artificielle, de Deep Learninget de réseaux de neurones.
Dans les années 1980, le Français Yan LeCun crée le premier réseau de neurones convolutif : une IA inspirée par le neocognitron de Kunihiko Fukushima. Ce réseau est composé de multiples couches de neurones artificiels, des composants mathématiques imitant le fonctionnement de neurones biologiques.
Lorsqu’un réseau de neurones traite une image, chacune de ses couches extrait des caractéristiques spécifiques à partir des pixels. La première couche détectera les éléments les plus basiques, comme les bordures verticales et horizontales.
À mesure que l’on s’enfonce en profondeur dans ce réseau, les couches détectent des caractéristiques plus complexes comme les angles et les formes. Les couches finales détectent les éléments spécifiques comme les visages, les portes, les voitures. Le réseau produit enfin un résultat sous forme de tableau de valeurs numériques, représentant les probabilités qu’un objet spécifique soit découvert dans l’image.
L’invention de Yann LeCun est brillante, et a ouvert de nouvelles possibilités. Toutefois, son réseau de neurones était restreintpar d’importantes contraintes techniques. Il était nécessaire d’utiliser d’immenses volumes de données et des ressources de calcul titanesques pour le configurer et l’utiliser. Or, ces ressources n’étaient tout simplement pas disponibles à cette époque.
Dans un premier temps, les réseaux de neurones convolutifs furent donc limités à une utilisation dans les domaines tels que les banques et les services postaux pour traiter des chiffres et des lettres manuscrites sur les enveloppes et les chèques.
Il a fallu attendre 2012 pour que des chercheurs en IA de Toronto développentle réseau de neurones convolutif AlexNet et triomphent de la compétition ImageNet dédiée à la reconnaissance d’image. Ce réseau a démontré que l’explosion du volume de données et l’augmentation de puissance de calcul des ordinateurs permettaient enfin d’appliquer les » neural networks » à la vision par ordinateur.
Ce réseau de neurones amorça la révolution du Deep Learning : une branche du Machine Learning impliquant l’utilisation de réseaux de neurones à multiples couches. Ces avancées ont permis de réaliser des bonds de géants dans le domaine de la Computer Vision. Désormais, les machines sont même en mesure de surpasser les humains pour certaines tâches de détection et d’étiquetage d’images.
Comment fonctionne la vision par ordinateur
Les algorithmes de vision par ordinateur sont basés sur la » reconnaissance de motifs « . Les ordinateurs sont entraînés sur de vastes quantités de données visuelles. Ils traitent les images, étiquettent les objets, et trouvent des motifs (patterns) dans ces objets.
Par exemple, si l’on nourrit une machine avec un million de photos de fleurs, elle les analysera et détectera des motifs communs à toutes les fleurs. Elle créera ensuite un modèle, et sera capable par la suite de reconnaître une fleurchaque fois qu’elle verra une image en comportant une.
Les algorithmes de vision par ordinateur reposent sur les réseaux de neurones, censés imiter le fonctionnement du cerveau humain. Or, nous ne savons pas encore exactement comment le cerveau et les yeux traitent les images. Il est donc difficile de savoir à quel point les algorithmes de Computer Vision miment ce processus biologique.
Les machines interprètent les images de façon très simple. Elles les perçoivent comme des séries de pixels, avec chacun son propre ensemble de valeurs numériques correspondant aux couleurs. Une image est donc perçue comme une grille constituée de pixels, chacun pouvant être représenté par un nombre généralement compris entre 0 et 255.
Bien évidemment, les chosesse compliquent pour les images en couleur. Les ordinateurs lisent les couleurs comme des séries de trois valeurs : rouge, vert et bleu. Là encore, l’échelle s’étend de 0 à 255. Ainsi, chaque pixel d’une image en couleur à trois valeurs que l’ordinateur doit enregistrer en plus de sa position.
Chaque valeur de couleur est stockée en 8 bits. Ce chiffre est multiplié par trois pour une image en couleurs, ce qui équivaut à 24 bits par pixel. Pour une image de 1024×768 pixels, il faut donc compter 24 bits par pixels soit presque 19 millions de bits ou 2,36 mégabytes.
Vous l’aurez compris : il faut beaucoup de mémoire pour stocker une image. L’algorithme de Computer Vision quant à lui doit parcourir un grand nombre de pixels pour chaque image. Or, il faut généralement plusieurs dizaines de milliers d’images pour entraîner un modèle de Deep Learning.
C’est la raison pour laquelle la vision par ordinateur est une discipline complexe, nécessitant une puissance de calcul et une capacité de stockage colossales pour l’entraînement des modèles. Voilà pourquoi il a fallu attendre de nombreuses années pour que l’informatique se développe et permette à la Computer Vision de prendre son envol.
Les différentes applications de Computer Vision
La vision par ordinateur englobe toutes les tâches de calcul impliquant le contenu visuel telles que les images, les vidéos ou même les icônes. Cependant, il existe de nombreuses branchesdans cette vaste discipline.
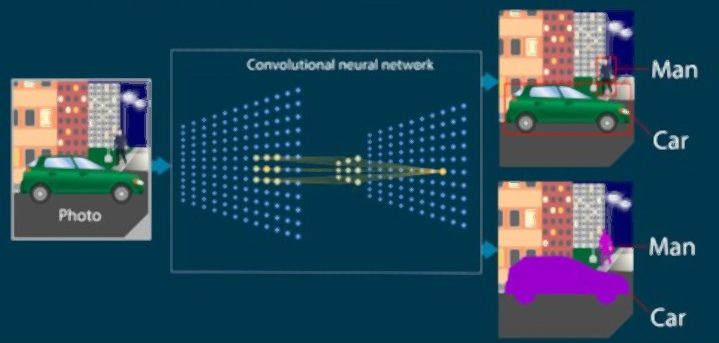
La classification d’objet consiste à entraîner un modèle sur un ensemble de données d’objets spécifiques, afin de lui apprendre à classer de nouveaux objets dans différentes catégories. L’identification d’objet quant à elle vise à entraîner un modèle à reconnaître un objet.
Parmi les applications les plus courantes de vision par ordinateur, on peut citer la reconnaissance d’écriture manuscrite. Un autre exemple est l’analyse de mouvement vidéo, permettant d’estimer la vélocité des objets dans une vidéo ou directement sur la caméra.
Dans la segmentation d’image, les algorithmes répartissent les images dans plusieurs ensembles de vues. La reconstruction de scène permet de créer un modèle 3D d’une scène à partir d’images et de vidéos.
Enfin, la restauration d’imageexploite le Machine Learning pour supprimer le » bruit » (grain, flou…) sur des photos. De manière générale, toute application impliquant la compréhension des pixels par un logiciel peut être associée à la Computer Vision.
Quels sont les cas d’usages de la Computer Vision ?
La Computer Vision fait partie des applications du Machine Learning que nous utilisons déjà au quotidien, parfois sans même le savoir. Par exemple, les algorithmes de Googleparcourent des cartes pour en extraire de précieuses données et identifier les noms de rues, les commerces ou les bureaux d’entreprises.
De son côté, Facebook exploite la vision par ordinateurafin d’identifier les personnes sur les photos. Sur les réseaux sociaux, elle permet aussi de détecter automatiquement le contenu problématique pour le censurer immédiatement.
Les entreprises de la technologie sont loin d’être les seules à se tourner vers cette technologie. Ainsi, le constructeur automobile Ford utilise la Computer Vision pour développer ses futurs véhicules autonomes. Ces derniers reposent sur l’analyse en temps réel de nombreux flux vidéo capturés par la voiture et ses caméras.
Il en va de même pour tous les systèmes de voitures sans pilote comme ceux de Tesla ou Nvidia. Les caméras de ces véhicules capturent des vidéos sous différents angles et s’en servent pour nourrir le logiciel de vision par ordinateur.
Ce dernier traite les images en temps réel pour identifier les bordures des routes, lire les panneaux de signalisation, détecter les autres voitures, les objets et les piétons. Ainsi, le véhicule est en mesure de conduire sur autoroute et même en agglomération, d’éviter les obstacles et de conduire les passagers jusqu’à leur destination.
La santé
Dans le domaine de la santé, la Computer Vision connaît aussi un véritable essor. La plupart des diagnostics sont basés sur le traitement d’image : lecture de radiographies, scans IRM…
Google s’est associé avec des équipes de recherche médicalepour automatiser l’analyse de ces imageries grâce au Deep Learning. D’importants progrès ont été réalisés dans ce domaine. Désormais, les IA de Computer Vision se révèlent plus performantes que les humains pour détecter certaines maladies comme la rétinopathie diabétique ou divers cancers.
Le sport
Dans le domaine du sport, la vision par ordinateur apporte une précieuse assistance. Par exemple, la Major League Baseballutilise une IA pour suivre la balle avec précision. De même, la startup londonienne Hawk-Eye déploie son système de suivi de balle dans plus de 20 sports comme le basketball, le tennis ou le football.
La reconnaissance faciale
Une autre technologie reposant sur la Computer Vision est la reconnaissance faciale. Grâce à l’IA, les caméras sont en mesure de distinguer et de reconnaître les visages. Les algorithmes détectent les caractéristiques faciales dans les images, et les comparent avec des bases de données regroupant de nombreux visages.
Cette technologie est utilisée sur des appareils grand public comme les smartphones pour authentifier l’utilisateur. Elle est aussi exploitée par les réseaux sociaux pour détecter et identifier les personnes sur les photos. De leur côté, les autorités s’en servent pour identifier les criminels dans les flux vidéo.
La réalité virtuelle et augmentée
Les nouvelles technologies de réalité virtuelle et augmentée reposent également sur la Computer Vision. C’est elle qui permet aux lunettes de réalité augmentée de détecter les objets dans le monde réelet de scanner l’environnement afin de pouvoir y disposer des objets virtuels.
Par exemple, les algorithmes peuvent permettre aux applications AR de détecter des surfaces planes comme des tables, des murs ou des sols. C’est ce qui permet de mesurer la profondeur et les dimensionsde l’environnement réel pour pouvoir y intégrer des éléments virtuels.
Les limites et problèmes de la Computer Vision
La vision par ordinateur présente encore des limites. En réalité, les algorithmes se contentent d’associer des pixels. Ils ne » comprennent » pas véritablement le contenu des images à la manière du cerveau humain.
Pour cause, comprendre les relations entre les personnes et les objets sur des images nécessite un sens commun et une connaissance du contexte. C’est précisément pourquoi les algorithmes chargés de modérer le contenu sur les réseaux sociaux ne peuvent faire la différence entre la pornographie et une nudité plus candide comme les photos d’allaitement ou les peintures de la Renaissance.
Alors que les humains exploitent leur connaissance du monde réel pour déchiffrer des situations inconnues, les ordinateurs en sont incapables. Ils ont encore besoin de recevoir des instructions précises, et si des éléments inconnusse présentent à eux, les algorithmes dérapent. Un véhicule autonome sera par exemple pris de cours face à un véhicule d’urgence garé de façon incongrue.
Même en entraînant une IA avec toutes les données disponibles, il est en réalité impossible de la préparer à toutes les situations possibles. La seule façon de surmonter cette limite serait de parvenir à créer une intelligence artificielle générale, à savoir une IA véritablement similaire au cerveau humain.
Comment se former à la Computer Vision ?
Si vous êtes intéressé par la Computer Vision et ses multiples applications, vous devez vous former à l’intelligence artificielle, au Machine Learning et au Deep Learning. Vous pouvez opter pour les formations DataScientest.
Le Machine Learning et le Deep Learning sont au coeur de nos formations Data Scientist et Data Analyst. Vous apprendrez à connaître et à manier les différents algorithmes et méthodes de Machine Learning, et les outils de Deep Learning comme les réseaux de neurones, les GANs, TensorFlow et Keras.
Ces formations vous permettront aussi d’acquérir toutes les compétences nécessaires pour exercer les métiers de Data Scientist et de Data Analyst. À travers les différents modules, vous pourrez devenir expert en programmation, en Big Data et en visualisation de données.
Nos différentes formations adoptent une approche innovante de Blended Learning, alliant le présentiel au distanciel pour profiter du meilleur des deux mondes. Elles peuvent être effectuées en Formation Continue, ou en BootCamp.
Pour le financement, ces parcours sont éligibles au CPF et peuvent être financés par Pôle Emploi via l’AIF. À l’issue du cursus, les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne. Parmi nos alumnis, 93% trouvent un emploi immédiatementaprès l’obtention du diplôme. N’attendez plus, et découvrez nos formations.
En mars 2020 l’Institut Montaigne diffusait une étude sur le contrôle des biais. La semaine dernière, c’est un groupement d’environ une soixantaine de chercheurs d’institutions, d’entreprises américaines et européennes spécialisés autour de l’intelligence artificielle ou IA (École Normale Supérieure de Paris, Alan Turing Institute, Cambridge, Stanford, Oxford, Google, Berkeley, Intel, etc.) qui a publié un rapport appelant au contrôle de l’éthique des IA.
Depuis quelques temps déjà, ce besoin d’encadrement est régulièrement évoqué, voir notre article « Ethique ou Big Data ». De nombreux rapports ont déjà été édités explicitant les différents problèmes éthiques de l’IA. Dans ces deux derniers rapports sont encore pointés ces mêmes problèmes, comme le contrôle des biais, la mise en place de bonnes pratiques communes mais aussi le manque de soutien financiers des politiques publiques pour financer la recherche à ce sujet.
Afin d’assurer un développement de l’IA efficient tout en respectant les droits fondamentaux de chacun est devenu une urgence, la crise sanitaire et les différentes problématiques que l’utilisation des données a pu engendrer au niveau éthique va, espérons-le, certainement accélérer cet encadrement des pratiques de l’IA.
Dans son étude l’Institut Montaigne incite plus à la prévention et à la sensibilisation qu’à la régulation et la sanction.
Les 4 recommandations qui ont été mises en avant par l’Institut sont les suivantes :
Tester la présence de biais dans les algorithmes comme l’on teste les effets secondaires des médicaments.
Promouvoir une équité active plutôt que d’espérer l’équité en ne mesurant pas la diversité.
Être plus exigeant pour les algorithmes ayant un fort impact sur les personnes (droit fondamentaux, sécurité, accès aux services essentiels)
Assurer la diversité des équipes de conception et de déploiement des algorithmes
L’institut préconise également l’émergence de labels qui garantissent la qualité des données utilisées et de l’organisation qui développe l’algorithme, l’existence de procédures de contrôle ou encore l’audibilité de l’algorithme, une capacité d’audit et de contrôle de certaines exigences pourrait être confiée à une tierce partie ou à l’État.
Dans le rapport publié la semaine dernière par le groupement de divers spécialistes internationaux de IA, on retrouve quasi la même préconisation parmi les 10 préconisées :
« Les organismes de normalisation doivent travailler avec les universités et l’industrie pour développer des exigences d’audit pour les applications critiques des algorithmes. »
Ce rapport préconise également d’autres pistes comme la mise en place de « bias bounty », d’une mutualisation des travaux et des outils entre organisations, en effet à l’heure actuelle chaque entreprise, université, s’applique des normes éthiques qui lui sont propres ce qui peut entrainer de nombreuses dérives.
Au niveau de l’état français, ce besoin d’encadrement est bien pris en compte puisqu’un budget de 30 M€ a été alloué à la certification de l’IA pour éviter les biais liés aux algorithmes (évaluation éthique des algorithmes, consolidation des algorithmes grâce à un dispositif de certificabilité) comme évoqué dans notre article « État et IA: une union en bonne voie? »
Déjà depuis 2018, conscients de la nécessité d’une coopération et d’une coordination à l’échelle internationale pour exploiter le plein potentiel de l’IA ,le Canada et la France dans le cadre du G7, travaillent ensemble aux côtés de la communauté internationale à la création d’un groupe international d’experts sur l’intelligence artificielle (G2IAou IPAI, pour international panel on artificial intelligence ) , sur le même modèle que le GIEC, pour favoriser la collaboration et la coordination internationale.
Ce groupement d’experts devra s’engager à respecter les valeurs communes suivantes lors du développement, de l’adoption et de l’utilisation de l’IA :
Promouvoir et protéger une approche de l’IA à la fois éthique et centrée sur l’humain, fondée sur les droits de l’homme ;
Promouvoir une approche multipartite de l’IA ;
Stimuler l’innovation, la croissance et le bien-être à travers l’IA ;
Mettre les travaux sur l’IA en adéquation avec les principes de développement durable et la réalisation du Programme développement durable à horizon 2030
Renforcer la diversité et l’inclusion à travers l’IA ;
Favoriser la transparence et l’ouverture des systèmes d’IA ;
Favoriser la confiance et la redevabilité en matière d’IA ;
Promouvoir et protéger les valeurs, les procédures et les institutions démocratiques ;
Combler les fractures numériques ;
Promouvoir la coopération scientifique internationale dans le domaine de l’IA.
Le 22 mai 2019 c’étaient les 36 pays membres de l’OCDE, ainsi que l’Argentine, le Brésil, la Colombie, le Costa Rica, le Pérou et la Roumanie qui ont adhéré aux Principes de l’OCDE sur l’intelligence artificielle. Principes élaborés avec le concours d’un groupe de plus de 50 experts de tous horizons – administrations, milieux universitaires, entreprises, société civile, instances internationales, communauté technique et organisations syndicales.
La conclusion évidente, à la vue de ces nombreux rapports émanant d’experts, de principes sur les bons usages de l’IA prescrits par diverses institutions, ou de la création du G2IA est que l’ensemble des acteurs économiques a un besoin urgent de repères communs afin de pouvoir se saisir pleinement et en toute légalité du potentiel de l’IA. La société numérique de demain a besoin de ce cadre pour pouvoir grandir et se développer sur des bases saines.
Ce blog est destiné à fournir des ressources à toute personne souhaitant donner un élan à sa carrière en se formant à la science des données ou data science.
Les métiers de la data science étant nombreux et variés, ce blog est particulièrement orienté vers celles et ceux qui souhaitent devenir data scientist.
Qu’est qu’un data scientist ? Comment devient-on data scientist ? Comment choisir la formation adaptée ? Quels sont les ouvrages et ressources à connaitre absolument ?
Voici les questions auxquelles vous trouverez des réponses sur ce blog.
Ce blog est alimenté par les équipes de YBCDATA, qui offre ses conseils et fournit des solutions « data driven » à tous types d’entreprises, afin de les accompagner dans la révolution du big data.