Dans le domaine en constante évolution de l’intelligence artificielle, les réseaux de neurones, ou neural networks en anglais, émergent comme des piliers fondamentaux de la technologie. Ces constructions inspirées du cerveau humain ont révolutionné la manière dont les machines apprennent et interprètent des données.
Cet article plongera au cœur des neural networks, explorant leur fonctionnement, leurs applications et leur impact croissant sur des domaines aussi variés que la reconnaissance d’images, le traitement du langage naturel et la résolution de problèmes complexes.
Introduction aux Neural Networks
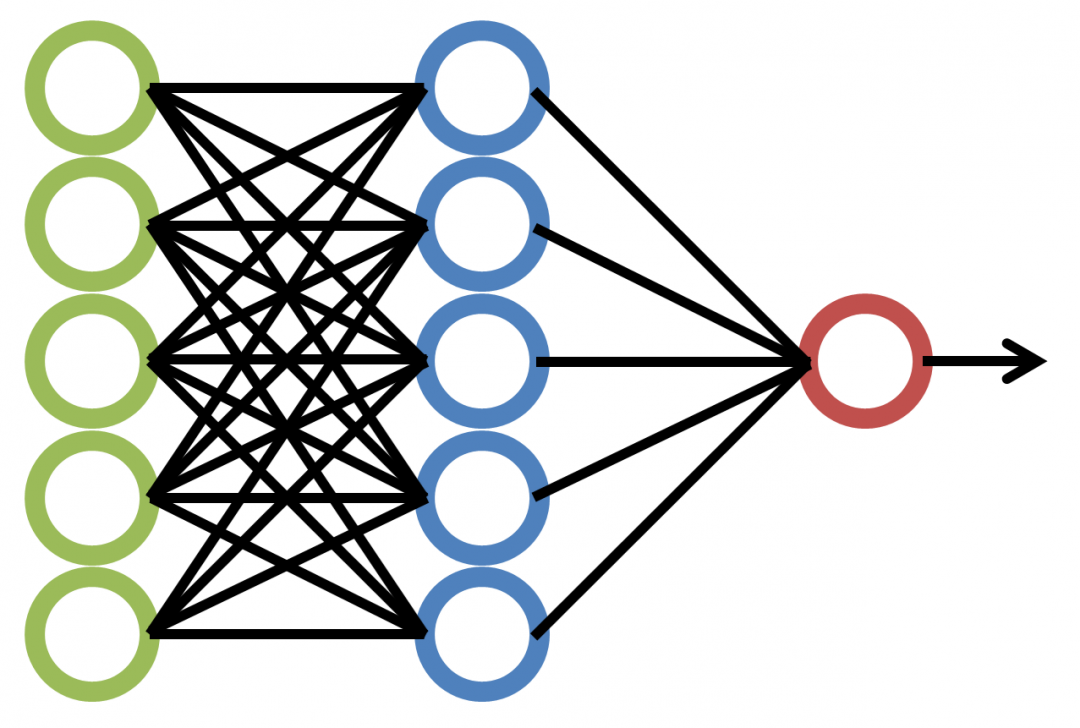
Les Neural Networks, également connus sous le nom de réseaux de neurones artificiels, constituent une pierre angulaire de l’intelligence artificielle et du domaine du machine learning. Les réseaux neuronaux représentent des modèles mathématiques sophistiqués conçus pour analyser des données et exécuter des missions complexes. À la base, un réseau de neurones est constitué de plusieurs couches interconnectées, chacune contenant des « neurones » artificiels qui traitent et transmettent les informations.
L’objectif fondamental des neural networks est d’apprendre à partir des données. Ils sont capables de détecter des motifs, des tendances et des relations au sein de la data, ce qui les rend particulièrement adaptés à des tâches telles que la reconnaissance d’images, la traduction automatique, la prédiction de séquences et bien plus encore. En ajustant les poids et les biais des connexions entre les neurones en fonction des données d’entraînement, les neural networks sont en mesure de généraliser leurs apprentissages et d’appliquer ces connaissances à de nouvelles données, ce qui en fait des outils puissants pour résoudre une variété de problèmes complexes.
Fonctionnement des Neurones Artificiels
Les éléments fondamentaux des réseaux de neurones, appelés neurones artificiels, s’inspirent du fonctionnement des neurones biologiques du cerveau humain. Chaque neurone artificiel reçoit des signaux d’entrée pondérés, qui sont sommés. Si cette somme dépasse un seuil, le neurone s’active, générant ainsi une sortie. Cette sortie devient l’entrée pour les neurones de la couche suivante. Les connexions entre les neurones sont liées à des poids, qui dictent l’importance de chaque connexion dans le calcul de la sortie. Les neurones artificiels apprennent en ajustant ces poids avec les données d’entraînement.
Les réseaux de neurones se déploient en couches : entrée, cachées et sortie. Les données d’entrée passent par la couche d’entrée, puis traversent les couches cachées où les calculs se déroulent. La couche de sortie fournit le résultat final. Des fonctions d’activation insérées dans les neurones introduisent des seuils non linéaires, capturant ainsi des relations complexes entre les données. Par des algorithmes d’apprentissage, les poids des connexions s’ajustent pour réduire la différence entre prédictions et sorties réelles, optimisant ainsi la généralisation du réseau pour obtenir des résultats précis sur de nouvelles données.
Les Différents Types de Neural Networks
Les réseaux de neurones, base fondamentale de l’apprentissage profond, se diversifient en types variés, adaptés à des tâches spécifiques. Parmi eux se trouvent les réseaux de neurones feedforward, aussi appelés perceptrons multicouches (MLP), qui comportent des couches successives de neurones. Ils sont utilisés pour la classification, la régression et la reconnaissance de motifs.
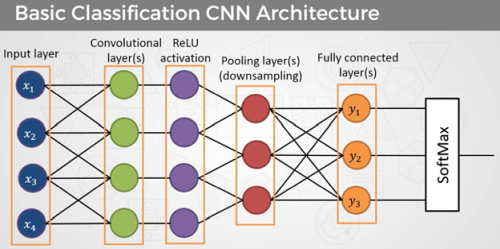
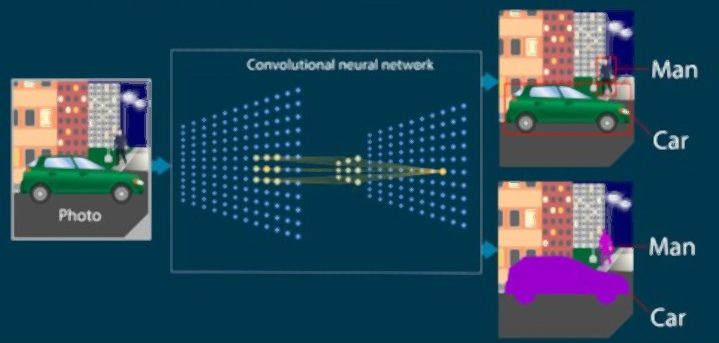
Les réseaux de neurones convolutifs (CNN), quant à eux, se focalisent sur les données structurées comme les images. Ils emploient des couches de convolution pour extraire des caractéristiques, suivies de sous-échantillonnage pour réduire les données. Les CNN excellent dans la reconnaissance d’images, la détection d’objets et la segmentation. D’autre part, les réseaux de neurones récurrents (RNN) se concentrent sur les séquences, comme le langage naturel. Leur architecture gère les dépendances temporelles et les entrées variables, utiles pour la traduction, la génération de texte et l’analyse de sentiment. Chaque type de réseau de neurones présente des avantages selon les données et les objectifs d’apprentissage.
Deep Learning et Couches Profondes dans les Neural Networks
Le Deep Learning, une sous-branche de l’apprentissage automatique, s’est révélé être une avancée majeure dans la réalisation de tâches complexes en utilisant des réseaux de neurones profonds. L’idée fondamentale derrière le Deep Learning est de construire des réseaux de neurones comportant plusieurs couches de traitement, également appelées couches profondes. Ces couches multiples permettent aux réseaux de capturer des représentations hiérarchiques et abstraites des données, améliorant ainsi leur capacité à résoudre des problèmes de plus en plus complexes.
Les couches profondes d’un réseau de neurones sont composées de neurones connectés en série, chacun effectuant une transformation mathématique des données qu’il reçoit en entrée. Les premières couches du réseau sont généralement responsables de l’extraction de caractéristiques simples, telles que les bords ou les formes basiques, tandis que les couches ultérieures combinent ces caractéristiques pour former des représentations plus complexes et sémantiques. L’ensemble du processus d’apprentissage vise à ajuster les poids et les biais des neurones afin de minimiser l’erreur entre les sorties prédites du réseau et les véritables étiquettes.
L’avantage clé des réseaux de neurones profonds réside dans leur capacité à apprendre des modèles de données à différents niveaux d’abstraction, ce qui les rend adaptés à une variété de tâches, de la reconnaissance d’images à la traduction automatique. Cependant, la profondeur accrue des réseaux ajoute également à la complexité de l’entraînement et à la nécessité de techniques avancées pour éviter le surapprentissage. Malgré ces défis, le Deep Learning a propulsé les performances de l’apprentissage automatique à de nouveaux sommets, ouvrant la voie à des applications innovantes et à des avancées significatives dans divers domaines.
Generative Adversarial Networks (GAN)
Les Réseaux Générateurs Adversaires (GAN) représentent une avancée révolutionnaire dans le domaine de l’intelligence artificielle, en particulier dans la génération de contenu réaliste comme des images, des vidéos et même du texte. Les GAN ont été introduits en 2014 par Ian Goodfellow et ses collègues, et depuis lors, ils ont suscité un grand engouement pour leur capacité à créer des données nouvelles et authentiques à partir de zéro.
L’architecture des GAN est basée sur deux réseaux neuronaux profonds antagonistes : le générateur et le discriminateur. Le générateur crée des données synthétiques, tandis que le discriminateur essaie de faire la distinction entre les données réelles et générées. Au fil de l’entraînement, le générateur s’améliore en essayant de tromper le discriminateur, et celui-ci s’améliore en distinguant de mieux en mieux entre les deux types de données.
Le processus de compétition entre le générateur et le discriminateur permet aux GAN de produire des données de haute qualité qui sont difficilement distinguables des données réelles. Cette technologie a eu un impact majeur sur la création d’art numérique, la synthèse de vidéos, la génération de scénarios pour les simulations et même la création de visages humains synthétiques réalistes. Cependant, les GAN ne sont pas sans leurs défis, notamment en ce qui concerne la stabilité de l’entraînement et le contrôle de la qualité des données générées. Malgré cela, les GAN continuent de susciter un intérêt croissant et ouvrent de nouvelles perspectives passionnantes pour la création et la manipulation de contenu numérique.
Tendances Futures dans le Domaine des Neural Networks
Le domaine des réseaux neuronaux connaît actuellement une croissance exponentielle, avec des avancées et des tendances futures qui ouvrent de nouvelles perspectives passionnantes. L’une de ces tendances est l’expansion continue du Deep Learning vers des domaines tels que la vision par ordinateur, le traitement du langage naturel et même la science des données. Les architectures de réseaux neuronaux de pointe, telles que les réseaux neuronaux convolutifs (CNN) et les réseaux récurrents, sont constamment affinées pour obtenir des performances encore meilleures dans des tâches complexes comme la traduction automatique, la compréhension du langage naturel et la reconnaissance d’objets.
Une autre tendance prometteuse est l’intégration de l’intelligence artificielle dans les objets quotidiens via l’Internet des Objets (IoT). Les réseaux neuronaux embarqués sur des dispositifs connectés permettront des interactions plus intelligentes et personnalisées avec nos environnements. De plus, la montée en puissance du traitement automatisé des langues naturelles et la génération de contenu multimédia par les réseaux neuronaux soulèvent des questions passionnantes sur la créativité, l’éthique et les limites de l’IA.
Alors que l’industrie continue de s’appuyer sur les réseaux neuronaux pour résoudre des problèmes de plus en plus complexes, la collaboration interdisciplinaire, les innovations algorithmiques et les percées matérielles joueront un rôle crucial dans la définition des prochaines tendances. Les réseaux neuronaux ne cessent d’évoluer et de remodeler le paysage technologique, ouvrant la voie à un avenir où l’intelligence artificielle sera de plus en plus intégrée dans notre quotidien.