
Il existe plusieurs outils statistiques destinés à évaluer les performances des différents modèles d’apprentissage automatique. Le cross validation, aussi appelé « validation croisée », en fait partie. Fondée sur une technique d’échantillonnage, la validation croisée est utilisée en Machine Learning pour évaluer des modèles d’apprentissage-machine.
Qu’est-ce que la validation croisée ? Quelles sont les différentes techniques de validation ? Pourquoi utiliser un jeu de données équilibrées ? Comment devenir un professionnel en validation croisée ? Les réponses à ces questions dans cet article.
Qu’est-ce que la validation croisée ?
La validation croisée : une technique d’échantillonnage
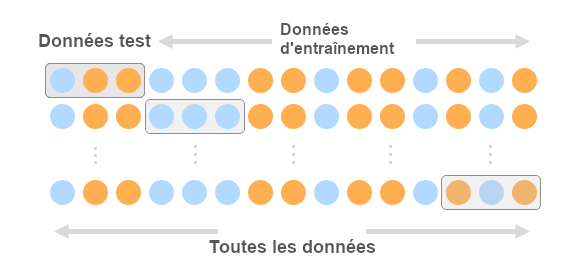
Très souvent utilisée en apprentissage automatique, la validation croisée est une technique d’évaluation permettant d’estimer la fiabilité d’un modèle d’apprentissage automatique. Plus explicitement, il s’agit d’une technique de rééchantillonnage. Elle repose sur un principe simple : utiliser un ensemble de données pour ensuite les diviser en deux catégories. Ce sont :
- les données d’entraînement utilisées pour entraîner le modèle,
- les données test utilisées pour la prédiction.
Pourquoi une validation croisée est-elle indispensable ?
Une Machine Learning fait appel à plusieurs modèles d’apprentissage automatique. C’est en partant de ces modèles que la validation croisée estime la fiabilité d’un modèle. Chaque modèle d’apprentissage est fondé sur des sous-ensembles de données d’entrée.
Via une technique d’échantillonnage, la validation croisée atteste si une hypothèse est valide ou non. Elle facilite donc le choix d’un algorithme adapté pour réaliser une tâche définie. On a également recours à la validation pour détecter un surajustement. En se basant sur un échantillon de prétendument issu de la même population d’échantillons d’apprentissage, la validation croisée :
- ne modélise pas les données de la même manière,
- démontre l’échec de la généralisation d’une tendance.
Une validation croisée permet d’estimer la fiabilité et la précision du modèle. À partir du moment où le modèle fonctionne sur les données de test, cela signifie qu’il n’a pas réajusté les données d’entraînement. Autrement dit, il peut tout à fait être utilisé pour la prédiction.
Quelles sont les différentes techniques de validation croisée ?
On dénote plusieurs techniques de validation croisée. Les principales sont :
- le train-test split,
- la méthode k-folds.
Le train-test split
Le principe de base du train-test split est de décomposer l’ensemble des données de manière aléatoire. Une partie servira à entraîner le modèle de Machine Learning. L’autre partie, quant à elle, permet de réaliser le test de validation. En règle générale, 70 à 80 % des données seront destinés à l’entraînement. Le reste, c’est-à-dire les 20 à 30 %, seront exploités pour le cross validation.
Cette technique s’avère fiable et très efficace. Toutefois, les données disponibles sont limitées. Puisque certaines données n’ont pas été utilisées pour l’entraînement, les informations peuvent donc être manquantes. Ce qui risque de biaiser hautement les résultats. Par contre, la technique du train-test split convient parfaitement à partir du moment où il y a une distribution égale entre les deux échantillons.
La méthode k-folds
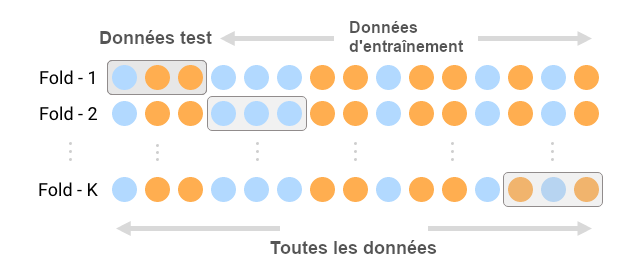
Très facile à appréhender et très populaire, la méthode k-folds est l’une des méthodes les plus utilisées par les professionnels. Elle consiste à diviser l’échantillon original en échantillons ou en blocs. De cette façon, l’ensemble des données apparaitra aussi bien dans l’ensemble des données d’entraînements que dans l’ensemble des données test.
Un paramétrage unique dénommé « K » est inséré dans la procédure. Idéalement, K devrait avoir une valeur ni trop basse ni trop haute : entre 5 et 10 selon l’envergure du dataset. Par la suite, il convient d’ajuster le modèle en utilisant des folds K-1 (moins 1). On répétera ce processus jusqu’à ce que tous les K-folds servent au sein de l’ensemble d’entraînement.
La moyenne des scores enregistrés représente la métrique de performance du modèle. À noter que la méthode k-folds peut s’effectuer manuellement ou à l’aide des fonctions cross_val_score et cross_val_predict. Ces dernières se trouvent dans la bibliothèque Python Scikit Learn.
Maîtriser les techniques de validation croisée
Pourquoi utiliser un jeu de données équilibrées ?
En présence d’un jeu de données déséquilibrées, il devient plus difficile de réaliser une cross validation. D’une manière plus concise, une base de données est déséquilibrée quand le nombre d’observations par classe n’est pas le même d’une classe à une autre. Résultat : les algorithmes se trouvent biaisés.
Pour renflouer leur fonction de perte, les algorithmes optimisent les métriques. Ils auront tendance à générer un classifieur trivial regroupant chaque exemple dans la classe majoritaire. Par conséquent, le modèle obtenu ne sera que le reflet de la surreprésentation de la classe majoritaire. Pour y remédier, bon nombre de professionnels ont recours à la validation croisée stratifiée ou « stratified cross validation ».
Cette méthode a pour but principal de s’assurer que la répartition des classes soit la même au niveau de tous les ensembles de validation et d’apprentissage à utiliser. Face à un jeu de données déséquilibrées, générer des échantillons synthétiques constitue une excellente alternative.




