Avec l’essor des technologies numériques, la collecte et la gestion de données sont devenues des enjeux économiques stratégiques pour de nombreuses entreprises. Ces pratiques ont engendrées la naissance d’un tout nouveau secteur et de nouveaux emplois : la Data science.
IBM prévoyait une hausse de 28 % de la demande de profil Data Scientist en 2020. En effet, de nombreuses entreprises ont compris l’importance stratégique de l’exploitation de la donnée. La Data science étant au cœur de la chaîne d’exploitation de la donnée, cela explique la hausse de la demande des profils compétents dans ce domaine.
Tour d’horizon de la Data science
La Data science, ou science de la donnée, est le processus qui consiste à utiliser des algorithmes, des méthodes et des systèmes pour extraire des informations stratégiques à l’aide des données disponibles. Elle utilise l’analyse des données et le machine learning(soit l’utilisation d’algorithmes permettant à des programmes informatiques de s’améliorer automatiquement par le biais de l’expérience) pour aider les utilisateurs à faire des prévisions, à renforcer l’optimisation, ou encore à améliorer les opérations et la prise de décision.
Les équipes actuelles de professionnels de la science de la donnée sont censées répondre à de nombreuses questions. Leur entreprise exige, le plus souvent, une meilleure prévision et une optimisation basée sur des informations en temps réel appuyées par des outils spécifiques.
La science de la donnée est donc un domaine interdisciplinaire qui connaît une évolution rapide. De nombreuses entreprises ont largement adopté les méthodes de machine learning et d’intelligence artificielle (soit l’ensemble des techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine) pour alimenter de nombreuses applications. Les systèmes et l’ingénierie des données font inévitablement partie de toutes ces applications et décisions à grande échelle axées sur les données. Cela est dû au fait que les méthodes citées plus tôt sont alimentées par des collections massives d’ensembles de données potentiellement hétérogènes et désordonnées et qui, à ce titre, doivent être gérés et manipulés dans le cadre du cycle de vie global des données d’une organisation.
Ce cycle de vie global en data science commence par la collecte de données à partir de sources pertinentes, le nettoyage et la mise en forme de celles-ci dans des formats que les outils peuvent comprendre. Au cours de la phase suivante, des méthodes statistiques et d’autres algorithmes sont utilisés pour trouver des modèles et des tendances. Les modèles sont ensuite programmés et créés pour prédire et prévoir. Enfin, les résultats sont interprétés.
Pourquoi choisir l’organisme DataScientest pour se former en Data science ?
Vous êtes maintenant convaincu de l’importance de la maîtrise de la Data science pour renforcer votre profil employable et pour aider votre entreprise.
Les formations en Data Science de l’organisme DataScientest sont conçues pour former et familiariser les professionnels avec les technologies clés dans ce domaine, dans le but de leur permettre de profiter pleinement des opportunités offertes par la science de la donnée et de devenir des acteurs actifs dans ce domaine de compétences au sein de leurs organisations.
Ces formations, co-certifiées par la Sorbonne, ont pour ambition de permettre, à toute personne souhaitant valoriser la manne de données mise actuellement à sa disposition, d’acquérir un véritable savoir-faire opérationnel et une très bonne maîtrise des techniques d’analyse de données et des outils informatiques nécessaires.
L’objectif que se fixe DataScientest est de vous sensibiliser en tant que futurs décideurs des projets data, aux fortes problématiques des données à la fois sous l’angle technique (collecte, intégration, modélisation, visualisation) et sous l’angle managérial avec une compréhension globale des enjeux.
Pourquoi choisir la formule « formation continue » chez Datascientest ?
Pendant 6 mois, vous serez formés à devenir un(e) expert(e) en data science, en maîtrisant les fondements théoriques, les bonnes pratiques de programmation et les enjeux des projets de data science.
Vous serez capable d’accompagner toutes les étapes d’un projet de data science, depuis l’analyse exploratoire et la visualisation de données à l’industrialisation d’outils d’intelligence artificielle (IA) et de machine learning, en faisant des choix éclairés d’approches, de pratiques, d’outils et de technologies, avec une vision globale : data science, data analyse, data management et machine learning. Vous pourrez cibler les secteurs extrêmement demandés de la data science.
Ce type de formation vous permettra d’acquérir les connaissances et les compétences nécessaires pour devenir data analyst, data scientist, data engineer, ou encore data manager. En effet, elles couvrent les principaux axes de la science de la donnée.
Autonomie et gestion de son temps
Que votre souhait de vous former en data science provienne d’une initiative personnelle ou qu’il soit motivé par votre entreprise, si la data science est un domaine totalement nouveau pour vous, il conviendrait de vous orienter vers le format « formation continue » de DataScientest. Effectivement, cela vous permettra de consacrer le temps qu’il vous faut pour appréhender au mieux toutes les notions enseignées. Sur une période de 6 mois, à partir de votre inscription (il y a une rentrée par mois), vous pourrez gérer votre temps comme bon vous semble, sans contrainte, que vous ayez une autre activité ou non.
Aussi, pour de nombreux salariés, il est difficile de bloquer plusieurs jours par semaine pour se former. C’est pourquoi, de plus en plus d’entreprises sollicitent des formations en ligne, à distance, pour plus d’efficacité ; vous aurez la possibilité de gérer votre temps de manière à adapter au mieux vos besoins d’apprentissage avec votre temps disponible.
Profiter de l’expertise de dizaines de data scientists
La start-up a déjà formé plus de 1500 professionnels actifs et étudiants aux métiers de Data Analysts et Data Scientists et conçu plus de 2 000 heures de cours de tout niveau, de l’acquisition de données à la mise en production.
» Notre offre répond aux besoins des entreprises, justifie Yoel Tordjman, CEO de Datascientest. Elle s’effectue surtout à distance, ce qui permet de la déployer sur différents sites à moindre coût, et de s’adapter aux disponibilités de chacun, avec néanmoins un coaching, d’abord collectif, puis par projet, dans le but d’atteindre un taux de complétion de 100 %. «
S’exercer concrètement avec un projet fil-rouge
Tout au long de votre formation et au fur et à mesure que vos compétences se développent, vous allez mener un projet de Data Science nécessitant un investissement d’environ 80 heures parallèlement à votre formation. Ce sera votre projet ! En effet, ce sera à vous de déterminer le sujet et de le présenter à nos équipes. Cela vous permettra de passer efficacement de la théorie à la pratique et de s’assurer que vous appliquez les thèmes abordés en cours. C’est aussi un projet fortement apprécié des entreprises, car il confirme vos compétences et connaissances acquises à l’issue de votre formation en Data Science. Vous ne serez jamais seul parce que nos professeurs seront toujours à vos côtés et disponibles en cas de besoin ; nous vous attribuons un tuteur pour votre projet parmi nos experts en data science.
Datascientest – Une solution de formation clé-en-main pour faciliter votre apprentissage et votre quotidien au travail
Passionné(e) par le Big Data et l’intelligence artificielle ? :
Devenez expert(e) en Data Science et intégrez le secteur le plus recherché par les entreprises. Une fois diplômé, vous pourrez commencer votre carrière en répondant parfaitement aux besoins des entreprises qui font face à une profusion et multiplication de données.
Vous souhaitez échanger avec Datascientest France autour de votre projet ?
Leader français de la formation en Data Science. Datascientest offre un apprentissage d’excellence orienté emploi pour professionnels et particuliers, avec un taux de satisfaction de 94 %.
Pour plus d’informations, n’hésitez pas à contacter DataScientest :
Le langage de programmation de Python Software Foundation est une programmation orientée objet. Lorsque les data scientists parient sur Python pour le traitement des données volumineuses, ils sont conscients qu’il existe d’autres options populaires telles que R, Java ou SAS. Toutefois, Python demeure la meilleure alternative pour ses avantages dans l’analyse du Big Data.
Pourquoi choisir Python ?
Entre R, Java ou Python pour le Big Data, choisir le dernier (en version majeure ou version mineure) est plus facile après avoir lu les 5 arguments suivants :
1. Simplicité
Python est un langage de programmation interprété connu pour faire fonctionner les programmes avec le moins de chaînes de caractères et de lignes de code. Il identifie et associe automatiquement les types de données. En outre, il est généralement facile à utiliser, ce qui prend moins de temps lors du codage. Il n’y a pas non plus de limitation pour le traitement des données.
2. Compatibilité
Hadoop est la plateforme Big Data open source la plus populaire. La prise en charge inhérente à Python, peu importe la version du langage, est une autre raison de la préférer.
3. Facilité d’apprentissage
Comparé à d’autres langages, le langage de programmation de Guido Van Rossum est facile à apprendre même pour les programmeurs moins expérimentés. C’est le langage de programmation idéal pour trois raisons. Premièrement, elle dispose de vastes ressources d’apprentissage. Deuxièmement, elle garantit un code lisible. Et troisièmement, elle s’entoure d’une grande communauté. Tout cela se traduit par une courbe d’apprentissage progressive avec l’application directe de concepts dans des programmes du monde réel. La grande communauté Python assure que si un utilisateur rencontre des problèmes de développement, il y en aura d’autres qui pourront lui prêter main-forte pour les résoudre.
4. Visualisation de données
Bien que R soit meilleur pour la visualisation des données, avec les packages récents, Python pour le Big Data a amélioré son offre sur ce domaine. Il existe désormais des API qui peuvent fournir de bons résultats.
5. Bibliothèques riches
Python dispose d’un ensemble de bibliothèques riche. Grâce à cela, il est possible de faire des mises à jour pour un large éventail de besoins en matière de science des données et d’analyse. Certains de ces modules populaires apportent à ce langage une longueur d’avance : NumPy, Pandas, Scikit-learn, PyBrain, Cython, PyMySQL et iPython.
Que sont les bibliothèques en Python ?
La polyvalence de toutes les versions de Python pour développer plusieurs applications est ce qui a poussé son usage au-delà de celui des développeurs. En effet, il a attiré l’intérêt de groupes de recherche de différentes universités du monde entier. Il leur ont permis de développer des librairies pour toutes sortes de domaines : application web, biologie, physique, mathématiques et ingénierie. Ces bibliothèques sont constituées de modules qui ont un grand nombre de fonctions, d’outils et d’algorithmes. Ils permettent d’économiser beaucoup de temps de programmation et ont une structure facile à comprendre.
Le programme Python est considéré comme le langage de programmation pour le développement de logiciels, de pages Web, d’applications de bureau ou mobiles. Mais, il est également le meilleur pour le développement d’outils scientifiques. Par conséquent, les data scientists sont destinés à aller de pair avec Python pour développer tous leurs projets sur le Big Data.
Python et la data science
La data science est chargée d’analyser, de transformer les données et d’extraire des informations utiles pour la prise de décision. Et il n’y a pas besoin d’avoir des connaissances avancées en programmation pour utiliser Python afin d’effectuer ces tâches. La programmation et la visualisation des résultats sont plus simples. Il y a peu de lignes de code en Python et ses interfaces graphiques de programmation sont conviviales.
Dans le développement d’un projet de science des données, il existe différentes tâches pour terminer ledit projet, dont les plus pertinentes sont l’extraction de données, le traitement de l’information, le développement d’algorithmes (machine learning) et l’évaluation des résultats.
La Computer Vision ou vision par ordinateur est une technologie d’intelligence artificielle permettant aux machines d’imiter la vision humaine. Découvrez tout ce que vous devez savoir : définition, fonctionnement, histoire, applications, formations…
Depuis maintenant plusieurs années, nous sommes entrés dans l’ère de l’image. Nos smartphones sont équipés de caméras haute définition, et nous capturons sans cesse des photos et des vidéos que nous partageons au monde entier sur les réseaux sociaux.
Les services d’hébergement vidéo comme YouTube connaissent une popularité explosive, et des centaines d’heures de vidéo sont mises en ligne et visionnées chaque minute. Ainsi, l’internet est désormais composé aussi bien de texte que d’images.
Toutefois, s’il est relativement simple d’indexer les textes et de les explorer avec des moteurs de recherche tels que Google, la tâche est bien plus difficile en ce qui concerne les images. Pour les indexer et permettre de les parcourir, les algorithmes ont besoin de connaître leur contenu.
Pendant très longtemps, la seule façon de présenter le contenu d’une image aux ordinateurs était de renseigner sa méta-description lors de la mise en ligne. Désormais, grâce à la technologie de » vision par ordinateur » (Computer Vision), les machines sont en mesure de » voir « les images et de comprendre leur contenu.
Qu’est ce que la vision par ordinateur ?
La Computer Vision peut être décrite comme un domaine de recherche ayant pour but de permettre aux ordinateurs de voir. De façon concrète, l’idée est de transmettre à une machine des informations sur le monde réel à partir des données d’une image observée.
Pour le cerveau humain, la vision est naturelle. Même un enfant est capable de décrire le contenu d’une photo, de résumer une vidéo ou de reconnaître un visage après les avoir vus une seule fois. Le but de la vision par ordinateur est de transmettre cette capacité humaine aux ordinateurs.
Il s’agit d’un vaste champ pluridisciplinaire, pouvant être considéré comme une branche de l’intelligence artificielle et du Machine Learning. Toutefois, il est aussi possible d’utiliser des méthodes spécialisées et des algorithmes d’apprentissage général n’étant pas nécessairement liés à l’intelligence artificielle.
De nombreuses techniques en provenance de différents domaines de science et d’ingénierie peuvent être exploitées. Certaines tâches de vision peuvent être accomplies à l’aide d’une méthode statistique relativement simple, d’autres nécessiteront de vastes ensembles d’algorithmes de Machine Learning complexes.
En 1966, les pionniers de l’intelligence artificielleSeymour Papert et Marvin Minsky lance le Summer Vision Project : une initiative de deux mois, rassemblant 10 hommes dans le but de créer un ordinateur capable d’identifier les objets dans des images.
Pour atteindre cet objectif, il était nécessaire de créer un logiciel capable de reconnaître un objet à partir des pixels qui le composent. À l’époque, l’IA symbolique – ou IA basée sur les règles – était la branche prédominante de l’intelligence artificielle.
Les programmeurs informatiques devaient spécifiermanuellement les règles de détection d’objets dans les images. Or, cette approche pose problème puisque les objets dans les images peuvent apparaître sous différents angles et différents éclairages. Ils peuvent aussi être altérés par l’arrière-plan, ou obstrués par d’autres objets.
Les valeurs de pixels variaient donc fortement en fonction de nombreux facteurs, et il était tout simplement impossible de créer des règlesmanuellement pour chaque situation possible. Ce projet se heurta donc aux limites techniques de l’époque.
Quelques années plus tard, en 1979, le scientifique japonais Kunihiko Fukushima créa un système de vision par ordinateur appelé » neocognitron « en se basant sur les études neuroscientifiques menées sur le cortex visuel humain. Même si ce système échoua à effectuer des tâches visuelles complexes, il posa les bases de l’avancée la plus importante dans le domaine de la Computer Vision…
La révolution du Deep Learning
La Computer Vision n’est pas une nouveauté, mais ce domaine scientifique a récemment pris son envol grâce aux progrès effectués dans les technologies d’intelligence artificielle, de Deep Learninget de réseaux de neurones.
Dans les années 1980, le Français Yan LeCun crée le premier réseau de neurones convolutif : une IA inspirée par le neocognitron de Kunihiko Fukushima. Ce réseau est composé de multiples couches de neurones artificiels, des composants mathématiques imitant le fonctionnement de neurones biologiques.
Lorsqu’un réseau de neurones traite une image, chacune de ses couches extrait des caractéristiques spécifiques à partir des pixels. La première couche détectera les éléments les plus basiques, comme les bordures verticales et horizontales.
À mesure que l’on s’enfonce en profondeur dans ce réseau, les couches détectent des caractéristiques plus complexes comme les angles et les formes. Les couches finales détectent les éléments spécifiques comme les visages, les portes, les voitures. Le réseau produit enfin un résultat sous forme de tableau de valeurs numériques, représentant les probabilités qu’un objet spécifique soit découvert dans l’image.
L’invention de Yann LeCun est brillante, et a ouvert de nouvelles possibilités. Toutefois, son réseau de neurones était restreintpar d’importantes contraintes techniques. Il était nécessaire d’utiliser d’immenses volumes de données et des ressources de calcul titanesques pour le configurer et l’utiliser. Or, ces ressources n’étaient tout simplement pas disponibles à cette époque.
Dans un premier temps, les réseaux de neurones convolutifs furent donc limités à une utilisation dans les domaines tels que les banques et les services postaux pour traiter des chiffres et des lettres manuscrites sur les enveloppes et les chèques.
Il a fallu attendre 2012 pour que des chercheurs en IA de Toronto développentle réseau de neurones convolutif AlexNet et triomphent de la compétition ImageNet dédiée à la reconnaissance d’image. Ce réseau a démontré que l’explosion du volume de données et l’augmentation de puissance de calcul des ordinateurs permettaient enfin d’appliquer les » neural networks » à la vision par ordinateur.
Ce réseau de neurones amorça la révolution du Deep Learning : une branche du Machine Learning impliquant l’utilisation de réseaux de neurones à multiples couches. Ces avancées ont permis de réaliser des bonds de géants dans le domaine de la Computer Vision. Désormais, les machines sont même en mesure de surpasser les humains pour certaines tâches de détection et d’étiquetage d’images.
Comment fonctionne la vision par ordinateur
Les algorithmes de vision par ordinateur sont basés sur la » reconnaissance de motifs « . Les ordinateurs sont entraînés sur de vastes quantités de données visuelles. Ils traitent les images, étiquettent les objets, et trouvent des motifs (patterns) dans ces objets.
Par exemple, si l’on nourrit une machine avec un million de photos de fleurs, elle les analysera et détectera des motifs communs à toutes les fleurs. Elle créera ensuite un modèle, et sera capable par la suite de reconnaître une fleurchaque fois qu’elle verra une image en comportant une.
Les algorithmes de vision par ordinateur reposent sur les réseaux de neurones, censés imiter le fonctionnement du cerveau humain. Or, nous ne savons pas encore exactement comment le cerveau et les yeux traitent les images. Il est donc difficile de savoir à quel point les algorithmes de Computer Vision miment ce processus biologique.
Les machines interprètent les images de façon très simple. Elles les perçoivent comme des séries de pixels, avec chacun son propre ensemble de valeurs numériques correspondant aux couleurs. Une image est donc perçue comme une grille constituée de pixels, chacun pouvant être représenté par un nombre généralement compris entre 0 et 255.
Bien évidemment, les chosesse compliquent pour les images en couleur. Les ordinateurs lisent les couleurs comme des séries de trois valeurs : rouge, vert et bleu. Là encore, l’échelle s’étend de 0 à 255. Ainsi, chaque pixel d’une image en couleur à trois valeurs que l’ordinateur doit enregistrer en plus de sa position.
Chaque valeur de couleur est stockée en 8 bits. Ce chiffre est multiplié par trois pour une image en couleurs, ce qui équivaut à 24 bits par pixel. Pour une image de 1024×768 pixels, il faut donc compter 24 bits par pixels soit presque 19 millions de bits ou 2,36 mégabytes.
Vous l’aurez compris : il faut beaucoup de mémoire pour stocker une image. L’algorithme de Computer Vision quant à lui doit parcourir un grand nombre de pixels pour chaque image. Or, il faut généralement plusieurs dizaines de milliers d’images pour entraîner un modèle de Deep Learning.
C’est la raison pour laquelle la vision par ordinateur est une discipline complexe, nécessitant une puissance de calcul et une capacité de stockage colossales pour l’entraînement des modèles. Voilà pourquoi il a fallu attendre de nombreuses années pour que l’informatique se développe et permette à la Computer Vision de prendre son envol.
Les différentes applications de Computer Vision
La vision par ordinateur englobe toutes les tâches de calcul impliquant le contenu visuel telles que les images, les vidéos ou même les icônes. Cependant, il existe de nombreuses branchesdans cette vaste discipline.
La classification d’objet consiste à entraîner un modèle sur un ensemble de données d’objets spécifiques, afin de lui apprendre à classer de nouveaux objets dans différentes catégories. L’identification d’objet quant à elle vise à entraîner un modèle à reconnaître un objet.
Parmi les applications les plus courantes de vision par ordinateur, on peut citer la reconnaissance d’écriture manuscrite. Un autre exemple est l’analyse de mouvement vidéo, permettant d’estimer la vélocité des objets dans une vidéo ou directement sur la caméra.
Dans la segmentation d’image, les algorithmes répartissent les images dans plusieurs ensembles de vues. La reconstruction de scène permet de créer un modèle 3D d’une scène à partir d’images et de vidéos.
Enfin, la restauration d’imageexploite le Machine Learning pour supprimer le » bruit » (grain, flou…) sur des photos. De manière générale, toute application impliquant la compréhension des pixels par un logiciel peut être associée à la Computer Vision.
Quels sont les cas d’usages de la Computer Vision ?
La Computer Vision fait partie des applications du Machine Learning que nous utilisons déjà au quotidien, parfois sans même le savoir. Par exemple, les algorithmes de Googleparcourent des cartes pour en extraire de précieuses données et identifier les noms de rues, les commerces ou les bureaux d’entreprises.
De son côté, Facebook exploite la vision par ordinateurafin d’identifier les personnes sur les photos. Sur les réseaux sociaux, elle permet aussi de détecter automatiquement le contenu problématique pour le censurer immédiatement.
Les entreprises de la technologie sont loin d’être les seules à se tourner vers cette technologie. Ainsi, le constructeur automobile Ford utilise la Computer Vision pour développer ses futurs véhicules autonomes. Ces derniers reposent sur l’analyse en temps réel de nombreux flux vidéo capturés par la voiture et ses caméras.
Il en va de même pour tous les systèmes de voitures sans pilote comme ceux de Tesla ou Nvidia. Les caméras de ces véhicules capturent des vidéos sous différents angles et s’en servent pour nourrir le logiciel de vision par ordinateur.
Ce dernier traite les images en temps réel pour identifier les bordures des routes, lire les panneaux de signalisation, détecter les autres voitures, les objets et les piétons. Ainsi, le véhicule est en mesure de conduire sur autoroute et même en agglomération, d’éviter les obstacles et de conduire les passagers jusqu’à leur destination.
La santé
Dans le domaine de la santé, la Computer Vision connaît aussi un véritable essor. La plupart des diagnostics sont basés sur le traitement d’image : lecture de radiographies, scans IRM…
Google s’est associé avec des équipes de recherche médicalepour automatiser l’analyse de ces imageries grâce au Deep Learning. D’importants progrès ont été réalisés dans ce domaine. Désormais, les IA de Computer Vision se révèlent plus performantes que les humains pour détecter certaines maladies comme la rétinopathie diabétique ou divers cancers.
Le sport
Dans le domaine du sport, la vision par ordinateur apporte une précieuse assistance. Par exemple, la Major League Baseballutilise une IA pour suivre la balle avec précision. De même, la startup londonienne Hawk-Eye déploie son système de suivi de balle dans plus de 20 sports comme le basketball, le tennis ou le football.
La reconnaissance faciale
Une autre technologie reposant sur la Computer Vision est la reconnaissance faciale. Grâce à l’IA, les caméras sont en mesure de distinguer et de reconnaître les visages. Les algorithmes détectent les caractéristiques faciales dans les images, et les comparent avec des bases de données regroupant de nombreux visages.
Cette technologie est utilisée sur des appareils grand public comme les smartphones pour authentifier l’utilisateur. Elle est aussi exploitée par les réseaux sociaux pour détecter et identifier les personnes sur les photos. De leur côté, les autorités s’en servent pour identifier les criminels dans les flux vidéo.
La réalité virtuelle et augmentée
Les nouvelles technologies de réalité virtuelle et augmentée reposent également sur la Computer Vision. C’est elle qui permet aux lunettes de réalité augmentée de détecter les objets dans le monde réelet de scanner l’environnement afin de pouvoir y disposer des objets virtuels.
Par exemple, les algorithmes peuvent permettre aux applications AR de détecter des surfaces planes comme des tables, des murs ou des sols. C’est ce qui permet de mesurer la profondeur et les dimensionsde l’environnement réel pour pouvoir y intégrer des éléments virtuels.
Les limites et problèmes de la Computer Vision
La vision par ordinateur présente encore des limites. En réalité, les algorithmes se contentent d’associer des pixels. Ils ne » comprennent » pas véritablement le contenu des images à la manière du cerveau humain.
Pour cause, comprendre les relations entre les personnes et les objets sur des images nécessite un sens commun et une connaissance du contexte. C’est précisément pourquoi les algorithmes chargés de modérer le contenu sur les réseaux sociaux ne peuvent faire la différence entre la pornographie et une nudité plus candide comme les photos d’allaitement ou les peintures de la Renaissance.
Alors que les humains exploitent leur connaissance du monde réel pour déchiffrer des situations inconnues, les ordinateurs en sont incapables. Ils ont encore besoin de recevoir des instructions précises, et si des éléments inconnusse présentent à eux, les algorithmes dérapent. Un véhicule autonome sera par exemple pris de cours face à un véhicule d’urgence garé de façon incongrue.
Même en entraînant une IA avec toutes les données disponibles, il est en réalité impossible de la préparer à toutes les situations possibles. La seule façon de surmonter cette limite serait de parvenir à créer une intelligence artificielle générale, à savoir une IA véritablement similaire au cerveau humain.
Comment se former à la Computer Vision ?
Si vous êtes intéressé par la Computer Vision et ses multiples applications, vous devez vous former à l’intelligence artificielle, au Machine Learning et au Deep Learning. Vous pouvez opter pour les formations DataScientest.
Le Machine Learning et le Deep Learning sont au coeur de nos formations Data Scientist et Data Analyst. Vous apprendrez à connaître et à manier les différents algorithmes et méthodes de Machine Learning, et les outils de Deep Learning comme les réseaux de neurones, les GANs, TensorFlow et Keras.
Ces formations vous permettront aussi d’acquérir toutes les compétences nécessaires pour exercer les métiers de Data Scientist et de Data Analyst. À travers les différents modules, vous pourrez devenir expert en programmation, en Big Data et en visualisation de données.
Nos différentes formations adoptent une approche innovante de Blended Learning, alliant le présentiel au distanciel pour profiter du meilleur des deux mondes. Elles peuvent être effectuées en Formation Continue, ou en BootCamp.
Pour le financement, ces parcours sont éligibles au CPF et peuvent être financés par Pôle Emploi via l’AIF. À l’issue du cursus, les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne. Parmi nos alumnis, 93% trouvent un emploi immédiatementaprès l’obtention du diplôme. N’attendez plus, et découvrez nos formations.
L’apprentissage supervisé, dans le contexte de l’intelligence artificielle, est la méthode d’apprentissage la plus utilisée en Machine Learning et en Deep Learning. L’apprentissage supervisé consiste à surveiller l’apprentissage de la machine en lui présentant des exemples de ce qu’elle doit effectuer. Ses utilisations sont nombreuses : reconnaissance vocale, intelligence artificiel
le, classifications, etc. Ainsi, la régression linéaire fait partie d’une des techniques d’apprentissage supervisé la plus utilisée dans la prédiction d’une valeur continue. Aussi, la grande majorité des problèmes de Machine Learning et de Deep Learning utilisent l’apprentissage supervisé : il est donc primordial de comprendre correctement le fonctionnement de cette méthode.
Comment fonctionne un apprentissage supervisé ?
Le but de l’apprentissage automatique est de créer des algorithmes aptes à recevoir des ensembles de données et à réaliser une analyse statistique pour prédire un résultat.
Si on appelle ça un apprentissage supervisé, c’est parce que le processus d’un algorithme tiré du Training Set (ensembles de données) peut être considéré comme un enseignant qui surveille le processus d’apprentissage. Nous connaissons les bonnes réponses, l’algorithme effectue des prédictions sur les réponses et est ensuite corrigé par l’enseignant. L’apprentissage cesse quand l’algorithme atteint le niveau attendu pour être efficient.
Il consiste en des variables d’entrée X et une variable de sortie Y. L’algorithme a pour but d’apprendre la fonction de l’entrée jusqu’à la sortie.
Y = f (X)
Les étapes de l’apprentissage automatique sont :
La collecte des données et leur labellisation
Le nettoyage des données pour identifier de potentielles erreurs ou manquement
Le prétraitement des données (identification des variables explicatives notamment)
Instanciation des modèles (modèle de régression ou de classification par exemple).
Entraînement des modèles
Validation du modèle
Ainsi et comme le montre la formule Y = f (X), le modèle d’apprentissage supervisé est très efficace pour étudier des relations linéaires mais il reste incapable de performer quand il y a des relations plus complexes qu’une linéarité entre les variables.
Apprentissage supervisé ou non supervisé ?
L’apprentissage non supervisé correspond au fait de n’utiliser que des données d’entrée (X) et aucune variable de sortie Y correspondante. Le but de l’apprentissage non supervisé est de modéliser la structure des données afin d’en apprendre plus sur les données et à la différence de l’apprentissage supervisé, il n’y a pas de bonne réponse ni d’enseignant. Les algorithmes sont laissés à leurs propres processus pour étudier et choisir la structure des données qui soit intéressante.
L’apprentissage automatique présente des atouts que les apprentissages non supervisés n’ont pas, mais il rencontre aussi des difficultés. En effet, l’apprentissage supervisé est plus apte à prendre des décisions auxquelles les humains peuvent s’identifier car les données sont elles-mêmes fournies par l’humain. Néanmoins, les apprentissages supervisés rencontrent plus de difficultés à traiter les données qui s’ajoutent après l’apprentissage. En effet, si un système connaît les groupes chiens et chats et reçoit une photographie de souris, il devra la placer dans l’un ou l’autre de ces deux groupes alors qu’elle n’y appartient pas. Au contraire, si le système avait suivi un apprentissage non supervisé, il ne serait pas capable d’identifier que c’est une souris mais il serait capable de le définir comme n’appartenant à aucune des 2 catégories chiens et chats.
Considérons le problème classique de la fidélisation des clients, nous constatons que nous pouvons l’aborder de différentes manières. Une entreprise veut segmenter ses clients. Cependant, quelle est la stratégie la plus appropriée ? Est-il préférable de traiter cela comme un problème de classification, de regroupement ou même de régression ? L’indice clé va nous donner la deuxième question.
Si l’entreprise se demande : « Mes clients se regroupent-ils naturellement d’une manière ou d’une autre ? », il n’y a pas à définir de cible pour le regroupement. En revanche, si elle pose la question autrement : « Pouvons-nous identifier des groupes de clients ayant une forte probabilité de se désabonner dès la fin de leur contrat ? », l’objectif sera bien défini. Par conséquent, elle prendra des mesures en fonction de la réponse à la question qui suit : « Le client va-t-il se désabonner ? ».
Dans le premier cas, nous avons affaire à un exemple d’apprentissage non supervisé, tandis que le second est un exemple d’apprentissage supervisé.
L’apprentissage supervisé chez DataScientest
Considérant l’efficacité et l’importance de l’apprentissage supervisé, DataScientestle place parmi les connaissances à valider aux cours de ses formations. Notamment au sein de la formation de data analyst et dans le module de Machine Learning de 75h, il vous sera demandé d’apprendre à identifier les problèmes de Machine Learning non supervisés, et apprendre à utiliser des méthodes d’apprentissage supervisé par des problèmes de régression. De même, dans la formation de data management, dans le module Data Literacy, nous apprendrons à identifier quelle méthode de Machine Learning utiliser selon le type de métier. Enfin, dans la formation de data scientist, le module de Machine Learning de 75h se verra attribuer une partie conséquente sur le sujet des apprentissages supervisés et non supervisés, leurs mises en place et l’identification de leurs problèmes.
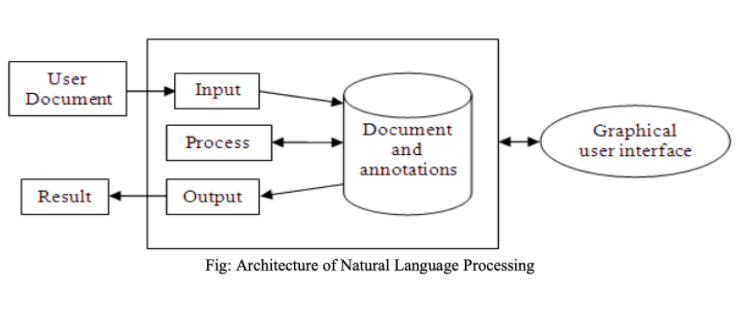
C’est seulement il y a 40 ans que l’objectif de doter les ordinateurs de la capacité de comprendre le langage naturel au sens de courant a commencé. Cet objectif de compréhension du langage naturel par les ordinateurs – plus communément appelé traitement du langage naturel ou “natural language processing” en anglais (NLP)est le sujet de cet article.
La maitrise du NLP permet d’accéder à des opportunités professionnelles dans le secteur de la data science. Seul un data scientist qui maitrise les techniques de machine learning et deep learning sera capable d’utiliser ces modèles pour les appliquer à des problématiques de traitement du langage naturel. D’où la nécessité de se former à la data science au travers d’une formation spécialisée.
Qu’est ce que le NLP ?
La NLP est une approche computationnelle de l’analyse des textes.
“Il s’agit d’une gamme de techniques informatiques à motivation théorique pour l’analyse et la représentation de textes naturels à un ou plusieurs niveaux d’analyse linguistique dans le but d’obtenir un traitement du langage similaire à l’humain pour une série de tâches ou d’applications”.
Le NLP regroupe les techniques qui utilisent des ordinateurs pour analyser, déterminer la similarité sémantique entre des mots et traduire entre les langues. Ce domaine concerne généralement les langues écrites, mais il pourrait également s’appliquer à la parole.
Dans cet article, nous aborderons les définitions et concepts nécessaires à la compréhension et méthodes nécessaires à la compréhension du NLP, les méthodes de l’analyse syntaxique ainsi que le modèle d’espace vectoriel pour le NLP au niveau du document.
Définitions et concepts
Présentons d’abord quelques définitions et concepts utilisés en NLP:
un corpus est un ensemble de documents
le lexique est un ensemble de mots utilisés dans la langue. En NLP, le lexique fait généralement référence à l’ensemble des mots uniques contenus dans le corpus
Les axes d’analyse pris en NLP sont :
la morphologie traite de la structure des mots individuels. Ainsi, les techniques dans ce domaine comprendraient des méthodes pour endiguer, attribuer la partie des balises vocales…
la syntaxe concerne la structure des phrases et les règles pour les construire. Elle est particulièrement importante car elle permet de déterminer le sens d’une phrase, également appelé sémantique.
la sémantique
Revenons quelques instants sur la syntaxe : une structure syntaxique peut être créée grâce à l’utilisation de la grammaire qui spécifie les règles de la langue. Un type de grammaire communément utilisé en NLP est la grammaire sans contexte (CFGs).
Un CFG comprend les parties suivantes :
des symboles des terminaux, qui peuvent être des mots ou de la ponctuation
des symboles non terminaux, qui peuvent être des parties de discours, de phrases…
des symboles de départ
ou encore un ensemble de règles avec un seul symbole non terminal à gauche et un ou plusieurs symboles à droite (terminaux ou non terminaux)
Les CFG ont certaines limites, mais ils peuvent s’acquitter de manière adéquate de certaines tâches de la NLP, telles que l’analyse syntaxique des phrases.
Un système de NLP devrait idéalement être capable de déterminer la structure du texte, afin de pouvoir répondre à des questions sur le sens ou la sémantique de la langue écrite. La première étape consiste à analyser les phrases en structures grammaticales. Cependant, l’analyse et la compréhension d’une langue naturelle à partir d’un domaine illimité se sont révélées extrêmement difficiles en raison de la complexité des langues naturelles, de l’ambiguïté des mots et des règles de grammaire difficiles.
Cet article fournit une introduction au NLP, qui comprend des informations sur ses principales approches.
Parmi les domaines de recherche fructueux en matière de NLP et de fouille de données textuelles, citons différentes méthodes pour la conversion de textes en données quantitatives, d’autres moyens de réduire les dimensions du texte, des techniques de visualisation des grands corpus, et des approches qui prennent en compte la dimension temporelle de certaines collections de documents.
Par conséquent, le NLP est utilisé dans une grande variété de disciplines pour résoudre de nombreux types de problèmes différents. L’analyse de texte est effectuée sur des textes allant de quelques mots saisis par l’utilisateur pour une requête Internet à de multiples documents qui doivent être résumés. La quantité et la disponibilité des données non structurées ont fortement augmenté au cours des dernières années. Cela a pris des formes telles que les blogs, les tweets et divers autres réseaux sociaux. Le NLP est idéal pour analyser ce type d’informations.
Le Machine Learning et l’analyse de texte sont fréquemment utilisés pour améliorer l’utilité d’une application.
Voici une brève liste des domaines d’application:
la recherche qui identifie des éléments spécifiques du texte. Elle peut être aussi simple que de trouver l’occurrence d’un nom dans un document ou peut impliquer l’utilisation de synonymes et d’orthographes/fausses orthographes alternatives pour trouver des entrées proches de la chaîne de recherche originale
la traduction automatique qui implique généralement la traduction d’une langue naturelle dans une autre.
des résumés : le NLP a été utilisé avec succès pour résumer des paragraphes, articles, documents ou recueils de documents
NER (Named-Entity Recognition) qui consiste à extraire du texte les noms des lieux, des personnes et des choses. Généralement, cette opération est utilisée en conjonction avec d’autres tâches du NLP, comme le traitement des requêtes
…
Les tâches du NLP utilisent fréquemment différentes techniques de Machine Learning. Une approche commune commence par la formation d’un modèle à l’exécution d’une tâche, la vérification que le modèle est correct, puis l’application du modèle à un problème.
Application du NLP
Le NLP peut nous aider dans de nombreuses tâches et ses champs d’application semblent s’élargir chaque jour. Mentionnons quelques exemples :
le NLP permet la reconnaissance et la prédiction des maladies sur la base des dossiers médicaux électroniques et de la parole du patient. Cette capacité est explorée dans des conditions de santé qui vont des maladies cardiovasculaires à la dépression et même à la schizophrénie. Par exemple, Amazon Comprehend Medical est un service qui utilise le NLP pour extraire les états pathologiques, les médicaments et les résultats des traitements à partir des notes des patients, des rapports d’essais cliniques et d’autres dossiers médicaux électroniques.
Les organisations peuvent déterminer ce que les clients disent d’un service ou d’un produit en identifiant et en extrayant des informations dans des sources telles que les réseaux sociaux. Cette analyse des sentiments peut fournir de nombreuses informations sur les choix des clients et les facteurs de décision.
Un inventeur travaillant chez IBM a mis au point un assistant cognitif qui fonctionne comme un moteur de recherche personnalisé en apprenant tout sur vous et en vous rappelant ensuite un nom, une chanson ou tout ce dont vous ne vous souvenez pas au moment où vous en avez besoin.
Le NLP est également utilisé dans les phases de recherche et de sélection de recrutement des talents, pour identifier les compétences des personnes susceptibles d’être embauchées et aussi pour repérer les prospects avant qu’ils ne deviennent actifs sur le marché du travail.
Le NLP est particulièrement en plein essor dans le secteur des soins de santé. Cette technologie améliore la prestation des soins, le diagnostic des maladies et fait baisser les coûts, tandis que les organismes de soins de santé adoptent de plus en plus les dossiers de santé électroniques. Le fait que la documentation clinique puisse être améliorée signifie que les patients peuvent être mieux compris et bénéficier de meilleurs soins de santé.
Vous envisagez d’obtenir un master en data sciences ? Le blog de DataScientest t’a élaboré une petite liste des 10 meilleurs diplômes, notés par les Chief data Officiers et managers de 30 entreprises du CAC 40. C’est parti :
Si tu veux devenir Data Scientist :
ENSAE Paris Tech, MS Data Science (4,75/5)
Tarif : entre 9 500€ et 14 000€
Durée : 420 heures de cours + stage de 4 à 6 mois
Description : C’est un master d’excellence qui apporte tout le bagage nécessaire pour devenir data scientist, data analyst ou encore chief data officer. Les cours sont conçus de telle manière à ce que les étudiants puissent mettre en pratique ce qui leur a été enseigné. Master alliant les connaissances à la fois techniques et théoriques, il te permettra de mener une carrière d’expert ou te hissera à la plus haute place des postes décisionnels de la data.
Polytechnique, Master Data Science (4,73/5)
Durée : 1 an
Description : Ce master est proposé en partenariat avec l’Université Paris-Saclay, l’ENS et Télécom Paristech. Il propose un parcours pédagogique d’excellence alliant théorie et pratique. Il offre également aux étudiants qui le souhaitent, la possibilité d’obtenir un doctorat et de continuer dans la recherche.
ENS Mathématiques vision Apprentissage (4,70/5)
Durée : 6 mois de cours + 4 mois de stage minimum
Description : Ce master est en association avec les écoles et universités les plus prestigieuses : Centrale Supélec, Polytechnique, Télécom Paristech et Jussieu. Il dote les étudiants de connaissances techniques solides qui leur permettront d’obtenir les meilleurs postes aussi bien en startups que dans les plus grandes entreprises du CAC 40, et ce, quelque soit le secteur d’activité.
Université Paris Dauphine-MASH- Mathématiques, Apprentissage et Sciences Humaines (4,61/5)
Durée : 6 mois de cours + 4 mois de stage
Description : Ce master est reconnu par le CEREMADE (Centre de Recherche en Mathématiques de la Décision). Il offre un bagage en statistiques appliquées à l’économie numérique et aux sciences humaines.
Si tu veux devenir Data Analyst :
Formation X-HEC data science for business (4,66/5)
Tarif : 41 300€
Durée : 2 ans
Description : C’est un master de prestige qui allie la renommée de la plus grande école de commerce de France à celle de la plus grande école d’ingénierie française. Le programme est conçu de telle sorte à ce que les étudiants puissent mettre en application toutes les connaissances techniques apprises lors de la première année à Polytechnique et ainsi répondre à des problématiques commerciales dans le cadre des cours à HEC.
ESSEC-Centrale Supélec master of science, data science & business analytics (4,57/5)
Tarif : 23 000€
Durée : entre 1 et 2 ans
Description : À l’instar du master précédent, il allie le prestige de deux des plus grandes écoles de commerce et d’ingénierie de France. La particularité de ce master est le grand choix proposé aux étudiants quant à l’élection de leurs cours avancés. Ce diplôme est classé 3ème mondial et 1er européen par le classement mondial des universités QS.
Telecom Paristech, master spécialisé big data (4,14/5)
Tarif : 18 500€
Durée : 9 mois de cours + 3 mois de stage
Description : La renommée internationale de ce master permet aux étudiants de décrocher les meilleurs postes dans les plus grandes entreprises. Ce master de qualité promeut l’innovation avec son incubateur Télécom Paris Novation Center Entrepreneurs et tous ses chercheurs.
Si tu veux devenir Data Engineer
Telecom Paristech, master spécialisé big data (4,56/5)
Tarif : 18 500€
Durée : 9 mois de cours + 3 mois de stage
Description : voir description plus haut (si tu veux devenir data analyst 3)
Université Paris Saclay- Finalité M2 Statistiques et Machine Learning (4,2/5)
Durée : 1 an de cours + 4 mois de stage
Description : Attention ! Cette formation est ultra sélective puisqu’elle n’offre que 20 places. C’est un master orienté plutôt Machine Learning qui aide les étudiants à préparer leur thèse en leur apprenant tous les outils nécessaires à l’analyse et à la prise de décision.
Description : C’est un master à haut niveau d’exigence qui apporte aux étudiants les connaissances théoriques les plus pointilleuses afin de devenir les prochains créateurs des meilleurs systèmes d’IA. Les cours sont dispensés par des grands chercheurs et des professionnels reconnus. Les étudiants auront également le choix entre un large panel d’options qui leur permettra de se spécialiser.
La crise du Covid et la pause imposée à certaines industries comme le transport aérien a soulevé une nouvelle fois l’impact néfaste de l’Homme sur son environnement et le rôle qu’il peut jouer pour préserver la planète. Face aux gros pollueurs dont l’activité est de plus en plus critiquée, il existe une pollution encore méconnue: la pollution numérique . Connue par 17% des Français selon une étude d’Inum, elle désigne la pollution liée à l’impact du numérique dans son ensemble, c’est-à-dire de sa création et sa fin de vie.
Que représente la pollution numérique par rapport à toutes les autres formes de pollution ? Quels sont les mécanismes en jeu ? Comment limiter l’impact du numérique sur la planète ?
Pollution numérique : Des chiffres surprenants
La pollution numérique est responsable de l’émission de 1400 millions de tonnes de CO2 par an, soit 4% des émissions mondiales de gaz à effet de serre. Elle est issue principalement des data center à hauteur de 25%, des infrastructures de réseau à 28% et à 47% en ce qui concerne les équipements. Il est généralement plus symbolique de comparer ces chiffres à quelque chose plutôt que de les citer. La forte augmentation d’utilisateurs et notre consommation de données laissent prévoir que d’ici 2025, cette empreinte aura doublée.
Les gestes du quotidien, pris individuellement, n’ont pas grand impact. Le problème est que ces petits gestes font partie d’une masse beaucoup plus vaste. Pour visualiser l’impact du numérique, il faut se rendre compte qu’internet c’est 45 millions de serveurs, 800 millions d’équipements réseaux, 15 milliards d’objets connectés en 2018, 10 milliards de mails envoyés (hors spam) et 180 millions de requêtes en 1 heure.
Voici ce que des gestes anodins du quotidien peuvent représenter comme pollution :
1 mail est l’équivalent d’une ampoule basse consommation pendant 1h, alors on multiplie cela par 10 milliards.
1 internaute c’est 1000 requêtes par an, soit 287 000 de CO2, soit 1,5 millions de km parcourus en voiture.
Encore plus gourmand, le streaming vidéo ! Il représente 60% des flux de données sur internet et on comprend pourquoi quand on sait que rien que Pulp Fiction pèse 200 000 fois plus lourd qu’un email sans pièce jointe.
Ces chiffres peuvent sembler exagérés, mais il s’agit bien de la réalité. Cependant, il faut noter que la plus grande part de pollution provient de la fabrication des matériels numériques et non de leur utilisation. Un téléviseur nécessite 2,5 tonnes de matières premières pour sa création, ce qui est équivalent à un aller-retour Paris Nice en avion en termes de CO2. Un ordinateur de 2kg nécessite 800 kg de matière premières. Et plus c’est petit, plus c’est polluant. Alors on vous laisse imaginer pour un smartphone.
La Data Science pour aider à réduire la pollution numérique
La data science a bien sûr son rôle à jouer dans tout ça. Plusieurs start-up ou entreprises font appel à cette technologie. La start-up Cleanfox a développé un outil qui vous débarrasse des spams et newsletter : «Nous avons développé des technologies nous permettant de lire les en-têtes des mails sans récupérer de données personnelles, explique Édouard Nattée, le fondateur de Cleanfox. Nous nous sommes aperçus que ces mêmes technologies pouvaient nous servir à détecter des newsletters et proposer à l’internaute de se désabonner automatiquement.». Cleanfox analyse votre boite mail et vous propose de supprimer ou non ce mail, en donnant des informations relatives tel que la quantité de CO2 entraîner par ce mail par exemple.
Comment la data science peut-elle lutter contre le réchauffement climatique ?
Au cœur des enjeux planétaires actuelles, le réchauffement climatique constitue un des plus grands défis de notre époque. Malgré de nombreuses politiques menées par les pays du monde entier visant à réduire les émissions de CO2, le volume d’émission de dioxyde de carbone continue de croître de manière exponentielle si bien que les chances de survies de l’Homme au sein de la planète Terre s’amenuisent de jours en jours. Toutefois, même si l’horloge tourne, l’Homme accompagné des nouvelles technologies qu’il a mis au point a encore la possibilité de sauver notre chère planète bleue. C’est dans ce contexte que l’Intelligence Artificielle et le Machine Learning pourraient devenir les défenseurs n°1 de la lutte contre le réchauffement climatique.
Voici le top 5 des différentes façons au travers desquelles le Machine Learning pourrait permettre de sauver la planète :
Le Machine Learning pour gérer la consommation d’énergie
De nos jours, la consommation d’énergie et des combustibles fossiles tels que le pétrole ne cessent de polluer contribuant ainsi grandement au réchauffement de la planète. Pour lutter contre cette consommation dévastatrice, les gouvernements des pays du monde entier tendent à privilégier désormais les énergies renouvelables telles que le vent ou le soleil qui, en plus d’être moins néfastes pour l’environnement, coûtent moins chers.
Néanmoins, ces sources d’énergie étant fortement dépendantes de la météo, il semble difficile pour l’Homme de déterminer la quantité exacte d’énergie qui sera produite.
Les algorithmes de Machine Learning, en analysant les données météorologiques et les conditions atmosphériques pourraient non seulement prédire le volume d’énergie généré mais également prédire la demande permettant ainsi de redistribuer la production vers les différentes centrales, tout en évitant le gaspillage.
Autre point intéressant, les nouvelles technologies permettent, sur la base de l’intelligence artificielle, de gérer la consommation d’énergie. Les assistants intelligents peuvent étudier les habitudes d’une maison et décider d’éteindre le chauffage pendant que personne n’y est et de réchauffer la maison une heure avant le retour des résidents.
La prévision de l’énergie nécessaire pour alimenter une machine, une usine, voire une ville permet de ne pas sur-produire, ainsi de ne pas gaspiller et ne pas émettre de l’énergie inutilement.
Le Machine Learning pour gérer le secteur du transport
Un autre secteur où le Machine Learning pourrait avoir impact positif retentissant est le transport. En effet, il pourrait par exemple optimiser les trajets permettant ainsi un allégement du trafic routier, un des acteurs actuels les plus polluants.
Le Machine Learning pour aider les satellites de surveillance de CO2
En vue de contrôler la quantité de CO2 émises par chaque pays européen, l’UE envisage dans les années à venir de mettre en place des satellites de surveillance de CO2. Le Machine Learning, combiné aux données récoltées par ces satellites pourrait permettre d’identifier non seulement les émetteurs principaux de CO2 mais également les secteurs d’activité les plus polluants. Il sera plus facile pour un pays par exemple de déterminer les domaines sur lesquels il faudra réfléchir en priorité pour moins polluer.
Le Machine Learning pour aider les pays les plus vulnérables au réchauffement climatique
Le Machine Learning, en étudiant les données et photographies prises par les satellites, pourrait identifier les différentes régions du monde sujettes au réchauffement climatique. Cela pourrait par la même occasion permettre aux différents pays concernés d’anticiper et ainsi de mieux gérer les éventuelles catastrophes naturelles qui risquent de les frapper.
De même, une analyse en temps réel des publications via les réseaux sociaux comme Twitter ou Facebook permettraient de déterminer dans quelles régions du monde, une aide est la plus nécessaire.
Le Machine Learning pour éviter le gaspillage alimentaire
L’analyse de données massives via le Machine Learning pourrait permettre d’optimiser des processus industriels et donc de réduire les émissions polluantes. Par exemple, les fermiers pourrait recevoir en temps réel des informations sur leurs plantations pour diffuser la quantité d’eau nécessaire. Autre exemple, des entreprises spécialisés pourraient organiser la redistribution de nourriture pour éviter le gaspillage en alimentant les zones connaissant des carences.
Devenir Data Scientist pour sauver la planète
Dans cet article, vous avez pu découvrir les opportunités que les data sciences offrent pour lutter contre le réchauffement climatique au travers une meilleure gestion de l’énergie et des ressources disponibles. Pour maîtriser ces nouvelles technologies, une formation s’impose. Pourquoi ne pas choisir un organisme qui a déjà fait ses preuves pour former des data scientists de plus de 30 grands groupes français et qui ouvre désormais ses classes aux particuliers ?
Comme nous l’avons observé tout au long de cet article, la pollution numérique a un impact négatif conséquent sur l’environnement et ne cesse d’augmenter exponentiellement. La data science, de par son étude de la big data, nécessite une grande quantité de données, très polluante à conserver. Néanmoins, l’intelligence artificielle et le Machine Learning, à travers leurs capacités à s’appliquer à des domaines tels que l’énergie, le transport, le gaspillage alimentaire offrent de vastes perspectives d’avenir synonymes de lueurs d’espoirs pour la préservation de notre planète. Il convient alors aux différents gouvernements et aux entreprises de trouver un juste milieu entre l’impact négatif et l’influence positive que pourraient apporter la data science à l’environnement.
Big Data Paris est le salon de référence dans l’univers du Big Data. Vous y retrouverez l’actualité des projets Data dans l’industrie, l’évolution de l’Open Data ou encore les nouveautés de Data analytics (BI, Datavisualisation, advanced analytics). Vous pourrez assister à des conférences sur la gouvernance des données ou sur la Sécurité des données. Si l’IA et le Big Data sont deux sujets qui vous passionnent, vous découvrirez les technologies de machine learning qui les combinent.
Avec AI Paris, Big Data Paris prévoit d’accueillir 20 000 visiteurs, 370 sponsors et exposants et plus de 300 conférences et ateliers. Les ateliers et les conférences seront accessibles en Live ou en replay.
Nous vous recommandons de privilégier le salon physique puisqu’il sera plus facile pour vous d’échanger avec les exposants sur vos problématiques métiers. N’oubliez cependant pas de respecter les gestes barrières et autres mesures de sécurité sanitaire.
Participez au Data Challenge – En partenariat avec DataScientest
Vous pourrez aussi avoir l’occasion de participer à un des événements les plus attendus du salon : Le Data Challenge. En accès libre sur le salon Big Data Paris Porte de Versailles, vous pourrez essayer d’exploiter les données de plus de 400 000 stations météorologiques et créer le meilleur modèle prédictif de la concentration en particules fines.Ce Data Challenge vous est proposé par DataScientest, leader français de la formation des métiers Data Sciences.
La data science se démocratise … à tel point que l’on voit fleurir de plus en plus de SaaS et autres plateformes pour devenir le parfait petit DataScientist ! C’est l’avènement du DSaaS (DataScience As A Service), que l’on constate surtout outre-atlantique, mais cela ne saurait tarder en France !
Je vous propose de lister ici ces nouvelles plateformes, user-friendly, qui rendent la data science facile. La liste a pour dessein d’évoluer dans le temps !
De nombreux termes barbares hantent les articles liés à la Data Science et au prédictif, que ce soient des algorithmes ou des modèles, comment avoir un aperçu de ce qui les caractérise et les différencie, sans pour autant être bac+10 en statistiques ?
Réponse sur 3 modèles que j’ai le plus fréquemment rencontrés : la régression linéaire, la régression logistique et l’arbre de décisions.
Attention, cet article s’adresse à des non-matheux, d’où un langage et des explications volontairement simplifiées 😉