Voici les principaux éléments de vocabulaire et acronymes à connaître autour de la Data Science et du Big data (cf. sourcing des définitions à la fin du post).
Avec quelques explications vulgarisées selon ma compréhension et des schémas qui me semblent parlants.
N’hésitez pas à ajouter des commentaires, ce post est évolutif!
AWS – Amazon Web Services: Ensemble de services proposés par Amazon sur le Cloud, notamment de l’espace de stockage, de la puissance de calcul et des softwares en location.

Analytics: Processus de collecte et d’analyse des données en vue de générer des informations permettant une prise de décision basée sur des faits. La business analytics (BA) est une offre de produits informatiques renvoyant le plus souvent aux outils de restitution destinés à l’aide à la prise de décision.
API – Application Programming Interface: Interface de programmation permettant à une application d’accéder à une autre application pour échanger des données, notamment des jeux de données très volumineux ou très volatiles. Les API sont souvent utilisées en temps réel.

Big Data: les 4V du big data sont Volume, Vélocité, Variété et Valeurs. On voit parfois apparaître la Véracité et la Visualisation.

BigTable: Système de gestion de base de données (SGBD) compressées développé et exploité par Google. Il est rapide, et héberge notamment les services gmail, Google Earth et Youtube. C’est une base de données orientée colonnes (cf. schéma).
 Google ne diffuse pas sa base de données mais propose une utilisation publique de BigTable via Google App Engine.
Google ne diffuse pas sa base de données mais propose une utilisation publique de BigTable via Google App Engine.
Cassandra: Système de gestion de base de données open source de type NoSQL, un des principaux projets de la Fondation Apache. Cassandra est conçue pour gérer des quantités massives de données réparties sur plusieurs serveurs (clusters), en assurant tout particulièrement une disponibilité maximale des données et en éliminant les points individuels de défaillance.
![]()
Cloud computing: Ensemble de processus qui consiste à utiliser la puissance de calcul et/ou de stockage de serveurs informatiques distants à travers un réseau, généralement Internet.

Cluster: En réseau et système, un cluster est une grappe de serveurs (ou « ferme de calcul ») constituée de deux serveurs au minimum (appelés aussi nœuds) et partageant une baie de disques commune. Evite la redondance de matériel. C’est l’inverse de l’architecture distribuée.

DBMS – Data Base Management System: En Français, SGBD – système de gestion de base de données. Il s’agit d’un logiciel système destiné à stocker et à partager des informations dans une base de données, en garantissant la qualité, la pérennité et la confidentialité des informations, tout en cachant la complexité des opérations.
Les principaux types de DBMS:
- modèle hiérarchique
- modèle multidimensionnel
- modèle relationnel

DFS – Distributed File System: En français, système de fichiers distribués ou système de fichiers en réseau. C’est un système de fichiers qui permet le partage de fichiers à plusieurs clients au travers du réseau informatique. Contrairement à un système de fichiers local, le client n’a pas accès au système de stockage, et interagit avec le système de fichiers via un protocole adéquat. Ce sont souvent des services basés dans le Cloud.

Datavisualisation: Aussi nommée « Dataviz« , il s’agit de technologies, méthodes et outils de visualisation des données. La présentation sous une forme illustrée rend les données plus lisibles et compréhensibles.
⇒ Quelques exemples sur mon board Pinterest.
DMP – Data Management Platform: ou « plateforme de gestion d’audience », outil permettant à une entreprise de regrouper l’ensemble des données issues de différents canaux (web, mobile, centre d’appel, etc.) et d’en tirer profit.

First Party Data / Third Party Data: La « first-party data » correspond aux informations acquises sur les internautes visitant un site Web. Ces informations sont récoltées par l’annonceur ou les éditeurs par différents biais (formulaire d’inscriptions, cookies ou outils analytiques rattachés) et peuvent avoir trait à des données comportementales (intérêts, achats, intention d’achat, navigation…) ou déclaratives (âge, CSP…). A l’inverse, la third-party data est collectée par des acteurs spécialisés.
⇒ En résumé, la first party data est la donnée collectée par l’annonceur, la third party data est la donnée de source externe.
Fondation Apache: Il s’agit d’une organisation à but non lucratif qui développe des logiciels open source sous licence Apache. Les projets les plus connus sont le serveur web Apache HTTP Server, Apache Hadoop, OpenOffice, SpamAssassin…
Framework: C’est un ensemble de bibliothèques, d’outils, de conventions, et de préconisations permettant le développement d’applications. Il peut être spécialisé ou non. C’est comme un modèle standard, qui permet la réutilisation du code par la suite.
Exemple: The Apache Cocoon Project

Google App Engine: Plateforme de conception et d’hébergement d’applications web basée sur les serveurs de Google. A l’inverse d’AWS, c’est gratuit pour des projets à petite échelle.

HANA – High-performance Analytical Application: SAP HANA est la plateforme haute performance ‘In-Memory’ proposée par SAP. C’est une combinaison Hardware/Software (‘appliance’) qui a vocation à contenir l’ensemble de l’applicatif SAP (parties ERP et BI), afin d’améliorer les performances et d’exploiter les données en temp réel.

Hadoop: Il s’agit d’un framework Open source codé en Java et conçu pour réaliser des traitements sur des données massives. C’est l’un des frameworks les plus utilisés, et permet notamment d’implémenter le MapReduce. Développé par Apache. Equivalents: Pig, Hive, Aster.
I/O architecture: Architecture faisant intervenir des entrées et des sorties de données.
Langage informatique: Notation conventionnelle destinée à formuler des algorithmes et produire des programmes informatiques qui les appliquent. D’une manière similaire à une langue naturelle, un langage de programmation est composé d’un alphabet, d’un vocabulaire, de règles de grammaire, et de significations.
Quelques exemples de language de programmation: SAS, R, SQL, Matlab, Fortran, Cobol, Python , Perl, JS, Bash, Java, C++… ⇒ L’indice TIOBE permet de suivre la ‘popularité’ des différents langages dans le temps.

Machine learning: Auto-apprentissage ou apprentissage automatique en français. Voir mon post complet sur le sujet.

MapReduce: C’est une procédure de développement informatique, inventée par Google, dans laquelle sont effectués des calculs parallèles de données très volumineuses, distribués sur différentes machines dans des lieux différents (Clusters ou Cloud computing). Trois étapes:
- Map: Diviser les données à traiter en partitions indépendantes (envoi les données et la fonction à un endroit donné),
- Exécuter les fonctions en parallèle
- Reduce: Combiner les résultats (opération inverse du Map)

⇒ En synthèse, le stockage et l’exécution coexistent au même endroit.
NLP – Natural Language Processing: ou traitement automatique du language naturel (TALN) en français. Ce sont des traitements qui permettent aux machines de mieux comprendre les éléments de languages de l’homme pour mieux interagir avec lui.

NoSQL – Not Only SQL (Structured Query Language): Se réfère à une base de données qui n’utilise pas (ou pas seulement) des tables et relations de tables (i.e. modèle relationnel appelé RDBMS), comme dans les bases de données classiques. Convient aux bases de données volumineuses.
 On dénombre 4 types de bases de données NoSQL: Orientées colonnes (cf. BigTable), Orientée graphe, Orientées clé-valeur et Orientées document.
On dénombre 4 types de bases de données NoSQL: Orientées colonnes (cf. BigTable), Orientée graphe, Orientées clé-valeur et Orientées document.

Exemple pour la base orientée graphe:

Python: Langage de programmation Open Source, très utilisé dans le traitement des données en masse. Il est facile à apprendre et à utiliser, flexible et puissant.
Logo Python
R: Outil connu et Open source d’analyse statistique et graphique.

Régression linéaire: Modèle de régression d’une variable expliquée sur une ou plusieurs variables explicatives dans lequel on fait l’hypothèse que la fonction qui relie les variables explicatives à la variable expliquée est linéaire dans ses paramètres. Le modèle de régression linéaire est souvent estimé par la méthode des moindres carrés.

Structured vs Unstructured Data: Les données structurées correspondent aux données que l’on peut normaliser (c’est-à-dire assigner une structure) alors que les données non-structurées ne peuvent pas l’être. Par exemple de l’information contenant beaucoup de texte (emails, posts Facebook, …).
Textmining: ou Fouille de textes en Français. C’est un ensemble de traitements informatiques consistant à extraire des connaissances selon un critère de nouveauté ou de similarité dans des textes produits par des humains pour des humains. Dans la pratique, cela revient à mettre en algorithme un modèle simplifié des théories linguistiques dans des systèmes informatiques d’apprentissage et de statistiques.
Variance: La variance est une mesure servant à caractériser la dispersion d’un échantillon ou d’une distribution. Elle indique de quelle manière la série statistique ou la variable aléatoire se disperse autour de sa moyenne ou son espérance. Une variance de zéro signale que toutes les valeurs sont identiques. Une petite variance est signe que les valeurs sont proches les unes des autres alors qu’une variance élevée est signe que celles-ci sont très écartées.
La racine carrée de la variance est l’écart-type. Dans la pratique, on préfère l’écart type  (lettre grecque sigma) à la variance
(lettre grecque sigma) à la variance 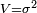 , car l’écart type peut être comparé à l’ordre de grandeur des valeurs, ce qui n’est pas le cas de la variance
, car l’écart type peut être comparé à l’ordre de grandeur des valeurs, ce qui n’est pas le cas de la variance
Sourcing / Remerciements:
Article sur LinkedIn – Bernard Marr
Data-publica.com
123opendata.com
Définitions-webmarketing.com
Wikipedia
Journal du net


