Quelle est l’évolution de l’IA au fil du temps ?
Depuis les premiers travaux de recherche dans les années 1950, l’Intelligence artificielle a pour but de créer des systèmes informatiques et des machines capables de réaliser des tâches exigeant normalement une intelligence humaine.
Elle vise à développer des algorithmes et des modèles permettant aux machines d’apprendre, de raisonner, de reconnaître des motifs, de prendre des décisions et de résoudre des problèmes de manière autonome.
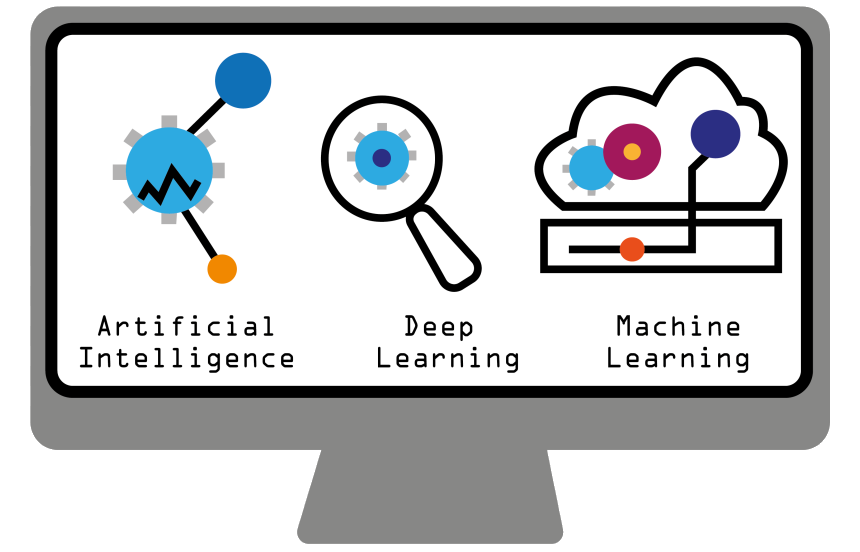
Après une longue période de stagnation surnommée « hiver de l’IA », l’intérêt pour cette technologie a connu une résurgence majeure au cours des dernières années grâce aux avancées dans le domaine de l’apprentissage automatique. En particulier, l’utilisation des réseaux neurones profonds et du deep learning ont permis l’émergence de nouveaux cas d’usage.
Le machine learning permet aux ordinateurs d’apprendre à partir de données et de s’améliorer avec l’expérience. C’est ce qui permet à Amazon de recommander des produits, à Gmail de suggérer des réponses aux messages, ou à Spotify de vous conseiller de nouvelles musiques.
De même, le traitement du langage naturel (NLP) est une technique d’IA permettant aux machines de comprendre et d’interagir avec le langage humain. Les chatbots de service client et les assistants vocaux comme Apple Siri reposent sur cette technologie.
Avec l’apparition récente des Larges Modèles de Langage comme OpenAI GPT ou Google PaLM, de nouveaux outils ont vu le jour en 2022 : les IA génératives, telles que ChatGPT ou Bard.
Désormais, l’Intelligence artificielle est capable de générer n’importe quel type de contenu écrit, visuel ou même audio à partir d’un simple prompt entré par l’utilisateur.
C’est une révolution, mais il ne s’agit que d’un début. Dans un futur proche, l’IA servira de cerveau à des robots de forme humanoïde capables d’effectuer toutes sortes de tâches manuelles comme le Tesla Optimus.
À plus long terme, les recherches pourraient mener à la naissance d’une « Intelligence artificielle générale » qui serait équivalente ou même supérieure à l’intelligence humaine…
Il ne fait aucun doute que l’IA va changer le monde et permettre d’automatiser de nombreuses tâches intellectuelles ou manuelles. En contrepartie, beaucoup de métiers risquent de disparaître et plusieurs experts redoutent une vague de chômage sans précédent.
Toutefois, cette technologie va aussi créer des millions de nouveaux emplois. À mesure qu’elle évoluera, de nouveaux cas d’usage apparaîtront et la demande en experts capables de créer, de gérer ou d’appliquer l’Intelligence artificielle va s’accroître.
Afin de profiter de ces nouvelles opportunités professionnelles, suivre une formation en IA est un choix très pertinent pour votre carrière. Voici pour quelles raisons.
Pourquoi suivre une formation d’Intelligence artificielle ?
Selon le Forum Économique Mondial, le nombre d’emplois remplacés par l’IA sera largement surpassé par le nombre d’emplois créés. D’ici 2025, plus de 97 millions de nouveaux postes pourraient voir le jour.
Mieux encore : il s’agirait de rôles « plus adaptés à la nouvelle division du travail entre les humains, les machines et les algorithmes ».
Par conséquent, apprendre à maîtriser l’Intelligence artificielle dès à présent peut être un précieux sésame pour les futurs métiers de l’IA ou pour incorporer la technologie à votre profession actuelle.
La technologie va continuer de s’améliorer au cours des prochaines années, et s’étendre à des secteurs et champs d’application toujours plus diversifiés.
Elle est déjà utilisée dans de nombreuses industries telles que la finance, la médecine, la sécurité ou l’automobile et sera bientôt utilisée dans tous les domaines.
Face à la forte demande, les professionnels de l’IA peuvent bénéficier d’une rémunération élevée. Selon Talent.com, leur salaire médian en France atteint 45 000€ par an et dépasse 70 000€ pour les plus expérimentés.
Les métiers de l’IA et leurs salaires
L’ingénieur en Intelligence artificielle ou ingénieur IA est un professionnel utilisant les techniques d’IA et de Machine Learning pour développer des systèmes et applications visant à aider les entreprises à gagner en efficacité.
Cet expert se focalise sur le développement d’outils, de systèmes et de processus permettant d’appliquer l’IA à des problèmes du monde réel. Les algorithmes sont entraînés par les données, ce qui les aide à apprendre et à améliorer leurs performances.
Ainsi, un ingénieur IA permet à une organisation de réduire ses coûts, d’accroître sa productivité et ses bénéfices, et à prendre les meilleures décisions stratégiques. Selon Glassdoor, son salaire moyen atteint 40 000 euros en France et 120 000 dollars aux États-Unis.
De son côté, l’ingénieur en Machine Learning ou ML Engineer recherche, conçoit et construit l’IA utilisée pour le machine learning. Il maintient et améliore les systèmes existants, et collabore avec les Data Scientists développant les modèles pour construire les systèmes IA.
Au quotidien, ce professionnel mène des expériences et des tests, effectue des analyses statistiques et développe des systèmes de machine learning. Son salaire dépasse 50 000 euros en France selon Glassdoor, et 125 000 dollars aux États-Unis.
Un autre métier lié à l’IA est celui de Data Engineer. Il se charge de collecter, gérer et convertir les données brutes en informations exploitables pour les data scientists et autres analystes métier. Le salaire moyen est de 115 592 dollars aux États-Unis et 45 000 euros en France d’après Glassdoor.
De même, le Data Scientist utilise les données pour répondre aux questions et résoudre les problèmes d’une entreprise. Il développe des modèles prédictifs utilisés pour prédire les résultats, et peut utiliser les techniques de machine learning. Son salaire médian est de 48 000 euros en France et 126 000 dollars aux États-Unis.
L’ingénieur logiciel ou Software Engineer a lui aussi un rôle à jouer dans l’Intelligence artificielle. Il utilise le code informatique pour créer ou améliorer tout type de programme. Son salaire moyen atteint 55 000 euros en France et 107 000 dollars aux États-Unis.
Selon un rapport de McKinsey, en 2022, 39% des entreprises ont recruté des ingénieurs logiciels et 35% ont employé des Data Engineers pour des postes liés à l’IA.
Enfin, l’Intelligence artificielle sera très bientôt incorporée aux robots et les ingénieurs en robotique feront donc aussi partie des métiers de l’IA.
Ils se chargent de concevoir de nouveaux produits ou d’assembler des prototypes pour les tester, et observent leurs performances. Ce métier combinant l’ingénierie mécanique et électrique avec l’informatique permet de percevoir un salaire dépassant 42 000 euros par an et 100 000 dollars aux États-Unis.
Il ne s’agit là que de quelques exemples de métiers de l’IA. À l’avenir, de nombreuses autres professions vont apparaître comme celle du Prompt Engineer chargé de concevoir les prompts pour obtenir les meilleurs résultats avec un outil comme ChatGPT.
Quel que soit le rôle que vous souhaitez exercer dans le domaine de l’IA, il est essentiel de suivre une formation pour acquérir l’expertise requise.
Comment suivre une formation d’Intelligence artificielle ?
Pour lancer votre carrière dans l’Intelligence artificielle, vous pouvez obtenir une certification professionnelle afin de démontrer votre expertise aux employeurs.
Parmi les certifications IA les plus reconnues à l’heure actuelle, on compte la certification « MIT: Artificial Intelligence: Implications for Business Strategy », les certificats d’ingénieur, consultant et scientifique IA de l’USAII, ou encore le titre d’Artificial Intelligence Engineer ARTIBA.
Afin d’obtenir un diplôme et d’assimiler toutes les compétences indispensables pour travailler dans l’IA. Vous pouvez choisir DataScientest. Nos formations Machine Learning Engineer, Data Engineer ou Data Scientist vous permettront d’obtenir l’expertise requise pour exercer le métier de vos rêves.
Vous découvrirez notamment les fondamentaux de l’Intelligence artificielle, le machine learning, le traitement naturel du langage (NLP), la vision par ordinateur (Computer Vision), ou encore les enjeux éthiques liés à l’IA.