D’où vient le métier du Data Scientist? Il fait partie des métiers à avoir vu le jour récemment, et le nombre de profils LinkedIn contenant le mot-clé DataScientist a été multiplié par 30 sur ce laps de temps (cf. infographie)!
Search results for
Data Scientist
Voici les principaux éléments de vocabulaire et acronymes à connaître autour de la Data Science et du Big data (cf. sourcing des définitions à la fin du post).
Avec quelques explications vulgarisées selon ma compréhension et des schémas qui me semblent parlants.
N’hésitez pas à ajouter des commentaires, ce post est évolutif!
Qui dit nouveau métier, dit nouveau vocabulaire!
L’objectif de ce post est de lister un panel représentatif des dénominations de métiers trouvées (sans pour autant aborder les qualités requises ainsi que les responsabilités, qui feront l’objet de posts ultérieurs!) pour tenter d’y voir un peu plus clair.
Au fond, l’équation Data Scientist = Data Analyst = Dataminer = Data Architect … est-elle vérifiée?

Le métier de data engineer est en plein essor, et les salaires sont à la hausse. En 2023, les data engineers en France gagnent en moyenne 60 000 € brut par an. Cependant, le salaire peut varier en fonction de différents facteurs, tels que le niveau d’expérience, les compétences, la localisation et le type d’entreprise.
Données salariales
Selon une étude de Glassdoor, le salaire médian des data engineers en France est de 55 000 € brut par an. Le salaire minimum est de 45 000 € brut par an, et le salaire maximum est de 75 000 € brut par an.
Les data engineers avec moins de 3 ans d’expérience gagnent en moyenne 45 000 € brut par an. Les data engineers avec 3 à 5 ans d’expérience gagnent en moyenne 50 000 € brut par an. Les data engineers avec plus de 5 ans d’expérience gagnent en moyenne 60 000 € brut par an.
Les data engineers travaillant dans les grandes entreprises technologiques ont tendance à gagner plus que ceux travaillant dans les petites entreprises. Les data engineers travaillant dans les industries de la finance ou de la santé ont également tendance à gagner plus que ceux travaillant dans d’autres industries.

Facteurs influençant le salaire
En plus du niveau d’expérience et de l’industrie, d’autres facteurs peuvent influencer le salaire des data engineers, tels que :
- Les compétences et les qualifications : Les data engineers avec des compétences et des qualifications spécifiques, telles que la connaissance de certaines technologies ou la maîtrise de certaines méthodologies, peuvent gagner plus.
- La localisation : Les data engineers travaillant dans les grandes villes ont tendance à gagner plus que ceux travaillant dans les petites villes.
- Le type d’entreprise : Les data engineers travaillant dans les grandes entreprises technologiques ont tendance à gagner plus que ceux travaillant dans les petites entreprises.

Conseils pour négocier un bon salaire
Voici quelques conseils pour négocier un bon salaire en tant que data engineer :
- Faites vos recherches : Avant de négocier, il est important de faire vos recherches sur les salaires moyens de la profession. Vous pouvez utiliser des sources telles que Glassdoor ou Indeed pour obtenir des informations sur les salaires dans votre région et votre industrie.
- Connaissez vos compétences : Il est également important de connaître vos propres compétences et qualifications. Vous pouvez utiliser vos expériences passées pour justifier votre demande de salaire.
- Soyez confiant : Lors de la négociation, il est important d’être confiant et de défendre votre valeur. Il ne faut pas avoir peur de demander ce que l’on veut.
- Soyez prêt à partir : Si vous n’êtes pas satisfait du salaire proposé, soyez prêt à partir. Cela montre à l’employeur que vous êtes sérieux dans vos demandes.

Conclusion
Le salaire des data engineers est en plein essor, et les perspectives d’emploi sont excellentes. En suivant les conseils ci-dessus, vous pouvez négocier un bon salaire et réussir dans votre carrière de data engineer.

Il s’agit d’une opportunité exceptionnelle d’apprendre à mettre en place des stratégies de marketing basées sur l’analyse approfondie des données. C’est également un moyen d’acquérir les compétences nécessaires pour façonner l’avenir du marketing grâce à l’utilisation judicieuse du data management, de l’intelligence artificielle (IA) et du Machine Learning.
Découvrons ensemble les points clés abordés durant une formation en data marketing ainsi que leur importance dans votre capacité à mettre en place des stratégies de marketing pertinentes.
L’objectif d’une formation en data marketing est conçue pour apporter à un professionnel du data marketing les compétences nécessaires pour naviguer dans le paysage complexe des données et en tirer des informations exploitables.
Elle commence souvent par une solide compréhension des concepts de base tels que le data management, l’analyse des données et l’intelligence artificielle. Avant de plonger dans les détails techniques, il est crucial de bien comprendre les prérequis et les bases nécessaires pour suivre le rythme de cette formation intensive.
Une formation en data marketing inclu des cours centrés sur le data management, car la collecte, le stockage et la gestion efficace des données font partie du quotidien d’un spécialiste du data marketing.
Dans un monde de plus en plus axé sur les données, les entreprises doivent être capables de gérer de grandes quantités de données (Big Data), de manière organisée et sécurisée. Le data management garantit que les données soient accessibles, précises et pertinentes, ce qui constitue la base d’une stratégie data-driven réussie.

L’élaboration d’une stratégie data-driven est l’un des objectifs clés de toute formation en data marketing. Les étudiants apprennent à exploiter les données pour pouvoir prendre des décisions éclairées et orienter leurs campagnes marketing. Cela implique d’identifier les KPIs pertinents, de surveiller les performances des campagnes en temps réel et d’ajuster les stratégies en fonction des données en temps réel. Une stratégie data permet une agilité et une réactivité inégalées dans un environnement marketing en constante évolution.
Une compréhension approfondie des clients est au cœur du data marketing. Les données collectées fournissent des informations sur les préférences, les comportements d’achat et les tendances des clients. Cela permet de personnaliser les messages marketing, d’optimiser l’expérience utilisateur et de créer des relations plus solides avec les clients.
Une formation en data marketing enseigne aux participants comment transformer ces données en un avantage concurrentiel, en offrant une proposition de valeur unique à chaque client.
S’inscrire à une formation Data Marketing
Outre l’acquisition de compétences techniques en marketing, une formation en data marketing ouvre également la voie à de nombreuses opportunités professionnelles. Les entreprises de toutes tailles et de tous secteurs reconnaissent la valeur des experts du data marketing. Ils sont capables d’exploiter les données pour prendre des décisions éclairées.
Les diplômés de ces formations peuvent travailler en tant qu’analystes de données marketing, gestionnaires de campagnes numériques, consultants en stratégie data ou même fonder leurs propres agences spécialisées en data marketing.


La digitalisation nous amène ces dernières années à sauvegarder de plus en plus de données hétérogènes. La démocratisation de l’utilisation du Cloud nous engage instinctivement à ne plus trier et à conserver tout type d’informations, y compris certaines obsolètes ou non pertinentes. Que ce soient des photos, des vidéos, des mails ou même des messages, l’utilisateur ne prend pas la mesure de la pollution numérique que cela représente, car il n’est plus encombré par des objets physiques ou des dossiers papier.
Le Data Hoarder est le chef d’orchestre du stockage des données. C’est une personne qui prend plaisir à amasser, ordonner et collectionner un nombre de données pharamineuses. Il est également archiviste et peut être ingénieur.
Description de la fonction du Data Hoarder
Un Data Hoarder à plusieurs missions, il est considéré comme un bibliothécaire numérique qui va préserver l’information et est également chargé de réparer les erreurs ou les mauvaises manipulations des utilisateurs.
Pourquoi a-t-on besoin d’un Data Hoarder ?
Tout d’abord pour les exigences légales et concurrentielles, ensuite pour la méfiance à l’égard des services cloud et enfin pour des raisons culturelles et familiales.
Quelles sont les compétences nécessaires pour ce métier ?
- Très bonne base en Excel
- Analytique UI
- Appétence pour les chiffres
- Habile avec les statistiques

Acquérir des compétences en Data Hoarding
Quels sont les outils qu’utilise le Data Hoarder ?
Pour gagner en performance, il aura besoin d’une connexion Internet solide, une capacité de mémoire imposante, à la fois en local, et sur les serveurs.
Wayback machine est une plateforme dédiée à l’archivage et au recensement. Elle représente une mine d’informations pour le Data Hoarder qui peut consulter des éléments préservés depuis plus de 30 ans et ainsi produire des statistiques adéquates.
Quelles sont les raisons pour lesquelles il fait cela ?
Plusieurs profils de Data Hoarder sont répertoriés :
- Le Hoarder Anxieux a peur de la suppression des données, ce qui peut mener à de graves conséquences psychologiques tel un trouble obsessionnel compulsif.
- Le Hoarder Collectionneur a de grandes capacités d’organisation. Il répertorie et classe toutes les données de manière scrupuleuse.
- Le Hoarder Docile exécute les tâches car on le lui a demandé.
- Le Hoarder Désengagé va archiver les données de personnes qui ne savent pas par où commencer pour nettoyer leur cyber-encombrement.
Conséquences du Data Hoarding
Malgré les nombreux avantages que présentent les actions d’un Data Hoarder, il persiste cependant certains aspects néfastes. Le fonctionnement des machines accumulant trop de données est considérablement ralenti; les disques durs emmagasinent trop d’informations ce qui altère la performance des outils.
Le surstockage est un facteur important de nuisance pour l’environnement. Les exigences énergétiques sont de plus en plus élevées et représenteraient actuellement 2% des émissions de gaz à effet de serre et seraient susceptibles d’augmenter à hauteur de 14% à horizon 2040.
La constructions massives de Data Centers impactent dramatiquement la faune et la flore, menaçant certaines espèces et déséquilibrant l’écosystème.
Solutions face aux répercussions des datas centers sur l’environnement
- Mettre en place des systèmes de refroidissement écologiques
- Utilisation d’énergies renouvelables
- Adopter la technologie de l’IA
Si vous souhaitez vous reconvertir dans ce domaine, n’hésitez pas à découvrir notre formation Data Scientist.
Découvrir la formation Data Scientist

Dans cet article, vous découvrirez ce qu’est le métier de Data Strategist. Vous allez pouvoir vous familiariser avec les différentes missions, les compétences indispensables et les outils de ce métier tant recherché ainsi que les atouts que ce rôle représente pour une entreprise et dans votre carrière.
Pour commencer, vous devez savoir qu’un Data Strategist est la personne qui va prendre en charge la gestion et l’analyse des données. Il va ensuite agir auprès des structures afin d’identifier les besoins de son activité principale et par la suite il élaborera un projet de développement, capable d’impacter des domaines aussi variés que le marketing, l’IT ou le business.
Quelles sont les missions d’un Data Strategist ?
- Exécution de la stratégie avec le Chief Data Officer
- Proposition de réponse innovantes et créatives dans le domaine de la data
- Planification et chefferie de projets
- Accompagnement des clients dans la compréhension de l’impact du Big Data
- Conception, architecture et développement de solution d’intelligence artificielle
- Développement des options dans le domaine de la Big Data
- Analyse de leads
- Assistance aux équipes de développement commercial dans les activités d’avant-vente et les appels d’offres
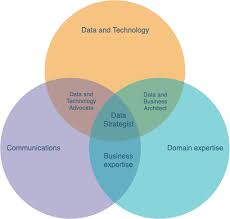
Diagramme de Venn pour le Data Strategist
Les trois cercles présents dans ce diagramme représentent les trois domaines de connaissances les plus importants pour un Data Strategist :
- Business
- Communication
- Data & Technologie
Le Data Strategist travaille principalement sur le côté business de la data. Il devra proposer des idées afin d’améliorer l’expansion de l’entreprise ou son organisation. À l’instar d’un chef de projet, il encadre les équipes fonctionnelles, recueille le besoin, gère les plannings, définit la stratégie technique et commerciale mais dans le domaine spécifique de la Big Data.
Quelles sont les compétences que doit avoir un Data Strategist ?
- Diplôme d’une école de commerce ou d’ingénieur
- Expériences significatives en Data Strategy, Data Gouvernance, Data Management
- Maîtrise des technologies de gouvernance, Master Data Management, Analytics, Intelligence Artificielle, Business Intelligence
- Aptitude en relation humaines et communication
- Niveau d’anglais courant
- Bonne compréhension du Machine Learning
- Appétence pour l’analyse statistique
- Esprit d’entreprise
- Compétences en matière d’organisation

Quels sont les outils utilisés ?
Le Data Strategist utilise principalement Microsoft Power BI, qui est une solution d’analyse de données et un outil incontournable dans ce domaine, permettant d’effectuer les tâches suivantes :
- La transformation des données
- La modélisation et visualisation des données
- La configuration de tableaux de bord, de rapports et applications
Pour permettre la mise en place d’un projet Cloud dans son intégralité, vous aurez besoin de maîtriser AWS qui régit les fonctions suivantes :
- Conception des architectures résilientes et sécurisées
- Infrastructure mondiale et fiabilité
- Réseaux
- Stockage base de données
- Présentation du Well Architect Framework et des avantages du cloud
Les atouts de la profession
Les métiers de la data (Data Strategist, Data Scientist, Data Analyst ou Data Engineer) sont en pleine expansion. Peu de profils compétents sont disponibles sur le marché et les entreprises souffrent d’un cruel manque de ressources pour gérer et traiter leurs données.
C’est un domaine dans lequel vous trouverez pleine et entière satisfaction professionnelle, tant sur le plan de la stimulation intellectuelle que sur la montée en compétences constante, où les perspectives d’évolution sont prometteuses.
En complément des points spécifiés en amont, le salaire d’un Data Strategist représente un attrait supplémentaire. Il est évalué selon plusieurs critères :
- Le niveau d’étude
- Les compétences acquises
- Les différentes expériences dans le domaine
- Le type de structure qui recrute
De manière générale, la rémunération est plus élevée dans le privé que dans le secteur public, dont l’indice n’est pas forcément réévalué annuellement. La fourchette salariale pour la profession se situe entre 34000€ et 58000€ brut.
Vous savez maintenant tout sur le métier de Data Strategist.
Si vous souhaitez vous reconvertir dans ce domaine, n’hésitez pas à découvrir notre formation Power BI et AWS.

Le web est une véritable mine de données informatiques. Ces données peuvent être exploitées, analysées pour une infinité de cas d’usage et d’applications. On peut les utiliser pour nourrir des systèmes de Machine Learning, d’intelligence artificielle, ou tout simplement pour mettre en lumière des tendances et des phénomènes.
S’il est possible de collecter ces données manuellement afin de constituer de vastes datasets, cette tâche représente un travail de titan. Afin de l’automatiser, on utilise le Web Scraping.
Qu’est-ce que le Web Scraping ?
Le Web Scraping est un processus qui consiste à assembler des informations en provenance d’internet, à l’aide de divers outils et frameworks. Cette définition est très large, et même le fait de copier / coller les paroles d’une chanson peut être considéré comme une forme de Web Scraping.
Toutefois, le terme de Web Scraping désigne généralement un processus impliquant l’automatisation. Les volumes massifs de données sont collectés automatiquement, afin de constituer de vastes datasets.
Certains sites web s’opposent à la collecte de leurs données par des scrapers automatiques. En règle générale, le scraping à des fins éducatives est plus toléré que pour un usage commercial. Il est important de consulter les conditions d’utilisation d’un site avant d’initier un projet.
À quoi sert le Web Scraping ?
Le Web Scraping permet d’agréger des informations plus rapidement qu’avec une collecte manuelle. Il n’est plus nécessaire de passer de longues heures à cliquer, à dérouler l’écran ou à rechercher les données.
Cette méthode se révèle particulièrement utile pour amasser de très larges volumes de données en provenance de sites web régulièrement mis à jour avec du nouveau contenu. Le scraping manuel est une tâche chronophage et rébarbative.
À l’échelle individuelle, le Web Scraping peut se révéler utile pour automatiser certaines tâches. Par exemple, un demandeur d’emploi peut utiliser Python pour automatiser ses recherches d’offres. Quelques lignes de code permettent d’enregistrer automatiquement les nouvelles annonces publiées sur des plateformes comme Indeed ou Monster, afin de ne plus avoir à visiter ces sites web quotidiennement.
Le Web Scraping peut aussi être utilisé pour surveiller des changements de prix, comparer des prix, ou surveiller la concurrence en collectant des sites web en provenance de leurs sites web. Les possibilités sont nombreuses et diverses.
Toutefois, cette méthode se révèle surtout pertinente pour les projets Big Data nécessitant d’immenses volumes de données. Par exemple, l’entreprise ClearView AI a utilisé le Web Scraping sur les réseaux sociaux afin de constituer une immense base de données de photos de profils pour son logiciel de reconnaissance faciale.
Le Web Scraping est presque aussi vieux qu’internet. Alors que le World Wide Web fut lancé en 1989, le World Wide Web Wanderer a été créé quatre ans plus tard. Il s’agit du premier robot web créé par Matthew Gray du MIT. Son objectif était de mesurer la taille du WWW.
Les défis du Web Scraping
Depuis sa création, internet a beaucoup évolué. On y trouve une large variété de types et formats de données, et le web scraping comporte donc plusieurs difficultés.
Le premier défi à relever est celui de la variété. Chaque site web est différent et unique, et nécessite donc un traitement spécifique pour l’extraction d’informations pertinentes.
En outre, les sites web évoluent constamment. Un script de Web Scraping peut donc fonctionner parfaitement la première fois, mais se heurter ensuite à des dysfonctionnements en cas de mise à jour.
Dès que la structure d’un site change, le scraper peut ne plus être capable de naviguer la ” sitemap ” correctement ou de trouver des informations pertinentes. Heureusement, la plupart des changements apportés aux sites web sont minimes et incrémentaux, et un scraper peut donc être mis à jour avec de simples ajustements.
Néanmoins, face à la nature dynamique d’internet, les scrapers nécessitent généralement une maintenance constante. Il est possible d’utiliser l’intégration continue pour lancer périodiquement des tests de scraping et s’assurer que les scripts fonctionnent correctement.
Les APIs en guise d’alternative au Web Scraping
Certains sites web proposent des APIs (interface de programmation d’application) permettant d’accéder à leurs données de manière prédéfinie. Ces interfaces permettent d’accéder aux données directement en utilisant des formats comme JSON et XML, plutôt que de s’en remettre au parsing de HTML.
L’utilisation d’une API est en général un processus plus stable que l’agrégation de données via le Web Scraping. Pour cause, les développeurs créent des APIs conçues pour être consommées par des programmes plutôt que par des yeux humains.
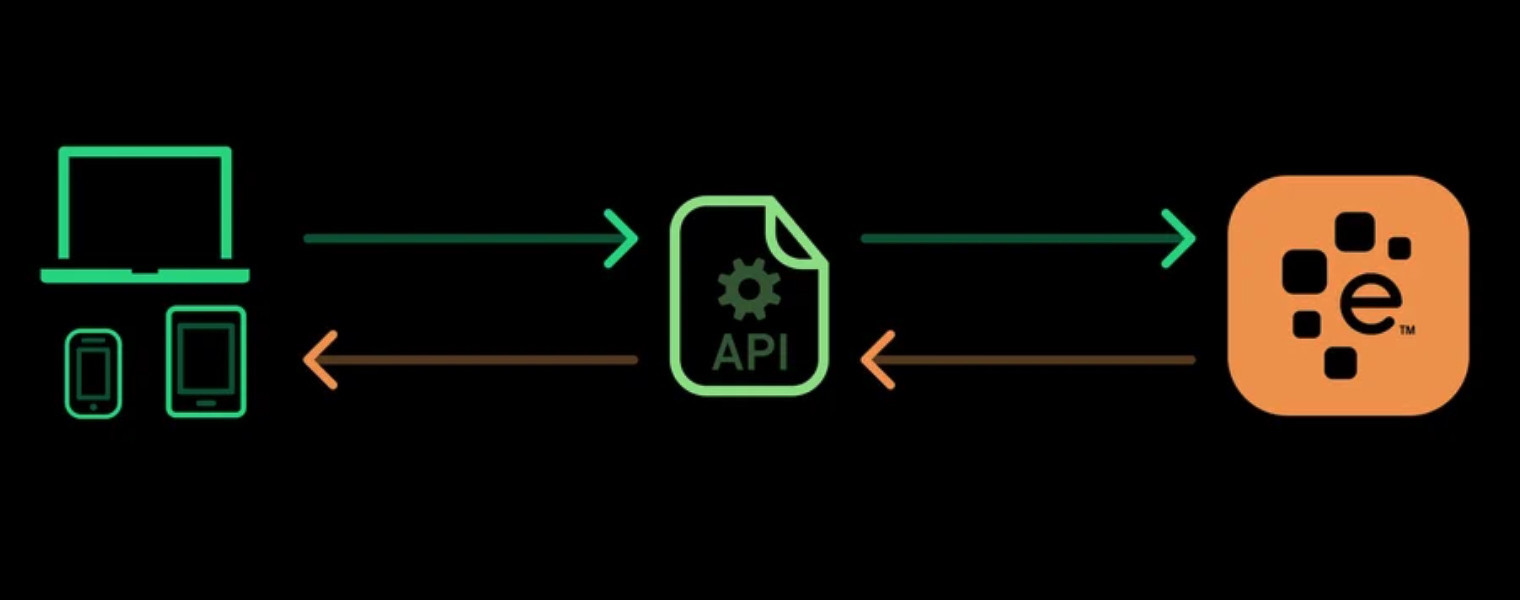
La présentation front-end d’une site web peut souvent changer, mais un tel changement dans le design d’un site web n’affecte pas la structure de son API. Cette structure est généralement plutôt permanente, ce qui en fait une source plus fiable de données.
Néanmoins, les APIs aussi peuvent changer. Les défis liés à la variété et à la durabilité s’appliquent donc aussi bien aux APIs qu’aux sites web. Il est également plus difficile d’inspecter la structure d’une API par soi-même si la documentation fournie n’est pas suffisamment complète.
Qu’est-ce que Beautiful Soup ?
Beautiful Soup est une bibliothèque Python utilisée pour le Web Scraping. Elle permet d’extraire des données en provenance de fichiers XML ou HTML. Cette bibliothèque crée un arbre de parsing à partir du code source de la page, pouvant être utilisé pour extraire les données de manière hiérarchique et lisible.
À l’origine, Beautiful Soup fut introduite en mai 2006 par Leonard Richardson qui continue à contribuer au projet. En outre, le projet est soutenu par Tidelift et son outil de maintenance open-source proposé par abonnement payant.
En plus de ses hautes performances, Beautiful Soup apporte plusieurs avantages. Cet outil permet de parcourir les pages de la même manière qu’un navigateur, et enjolive le code source.
Comment apprendre à utiliser Beautiful Soup et Python ?
Afin d’apprendre à utiliser Beautiful Soup, vous pouvez choisir DataScientest. Leur formation Data Analyst commence avec un module dédié à la programmation en Python, et comporte un module dédié à l’extraction de données textes et au Web Scraping.
Les autres modules de ce cursus couvrent la Dataviz, le Machine Learning, les bases de données Big Data et la Business Intelligence. À l’issue du programme, vous aurez toutes les compétences requises pour exercer le métier de Data Analyst.
Toutes nos formations adoptent une approche Blended Learning combinant coaching individuel sur notre plateforme en ligne et Masterclass. Le programme peut être complété en Formation Continue ou en mode BootCamp intensif.
À la fin du cursus, vous recevrez un certificat délivré par l’Université Paris la Sorbonne dans le cadre de notre partenariat. Parmi les alumnis, 80% ont trouvé un emploi immédiatement après la formation.
Nos programmes sont éligibles au Compte Personnel de Formation pour le financement. N’attendez plus et découvrez la formation Data Analyst de DataScientest !
Vous savez tout sur Beautiful Soup. Découvrez notre dossier complet sur le langage Python, et notre dossier sur le métier de Data Analyst.

Définitions
Qu’est-ce que la Data Science ? À quoi sert-elle ? Pourquoi est-elle importante aujourd’hui ?
Il y a beaucoup de discussions sur ce qu’est la Data Science ou Science des données. Mais, nous pouvons la résumer par la phrase suivante : « La Data Science est la discipline du 21e siècle qui convertit les données en connaissances utiles ».
La Data Science combine plusieurs domaines, dont les statistiques, les méthodes scientifiques (scientific methods) et l’analyse des données (analyzing data). Elle permet d’extraire de la valeur dans les données, de la collecte de celles-ci (Data Collections) à l’analyse prédictive (Predictive Analytics) en passant par la présentation des résultats (Data Visualization). Le praticien de la Science des données est le Data Scientist qui travaille de près avec d’autres experts du Big Data tels que le Data Analyst et le Data Engineer (Data Science Team).
Qu’est-ce que la Data Science ?
En termes simples, la Science des données consiste à appliquer l’analyse prédictive pour tirer le meilleur parti des informations d’une entreprise. Il ne s’agit pas d’un produit, mais d’un ensemble d’outils (parfois Open source) et de techniques interdisciplinaires intégrant les statistiques (statistical analysis et statistical modeling), l’informatique (computer science) et les technologies de pointe (Artificial Intelligence AI et Machine Learning models) qui aident le Data Scientist à transformer les données en informations stratégiques (actionable insights).
La plupart des entreprises sont aujourd’hui submergées de données et ne les utilisent probablement pas à leur plein potentiel. C’est là qu’intervient le Data Scientist qui met à leur service ses compétences uniques en matière de Science des données pour les aider à transformer les informations en données stratégiques significatives et en véritable avantage concurrentiel (Data Driven Marketing).
En appliquant la Data Science, une organisation peut prendre des décisions en toute confiance et agir en conséquence, car elle travaille avec des faits et la méthode scientifique, plutôt qu’avec des intuitions et des suppositions.
Que font exactement les Data Scientists ?
Les Data Scientists sont des experts dans trois groupes de disciplines :
– Les statistiques et les mathématiques appliquées
– L’informatique
– L’expertise commerciale
Si les Scientifiques des données peuvent avoir une expertise en physique, en ingénierie, en mathématiques et dans d’autres domaines techniques ou scientifiques, ils doivent également comprendre les objectifs stratégiques de l’entreprise pour laquelle ils travaillent afin d’offrir de réels avantages commerciaux.
Le travail quotidien d’un Data Scientist consiste à :
– Définir un problème ou une opportunité commerciale
– Gérer et à analyser toutes les données pertinentes pour le problème
– Construire et tester des modèles pour fournir des aperçus et des prédictions
– Présenter les résultats aux parties prenantes de l’entreprise
– Écrire du code informatique pour exécuter la solution choisie
Lorsqu’il fait du codage, il applique ses connaissances d’une combinaison de langages utilisés pour la gestion des données et l’analyse prédictive tels que Python, R, SAS et SQL/PostgreSQL.
Enfin, le Data Scientist est également chargé d’analyser et de communiquer les résultats commerciaux réels.
En raison du grand nombre de compétences spécifiques impliquées, les scientifiques de données qualifiés sont difficiles à identifier et à recruter. En outre, leur maintien au sein d’une équipe interne est coûteux pour une organisation.
Pourquoi la Data Science est-elle soudainement si importante ?
La théorie mathématique et statistique qui sous-tend la Data Science est importante depuis des décennies. Mais, les tendances technologiques récentes ont permis la mise en œuvre industrielle de ce qui n’était auparavant que de la théorie. Ces tendances font naître un nouveau niveau de demande pour la Science des données et un niveau d’excitation sans précédent quant à ce qu’elle peut accomplir :
– L’essor du Big Data et de l’Internet des objets (IoT)
La transformation numérique du monde des affaires a donné lieu à une énorme quantité de données (amounts of data) et différents jeux de données (data sets) sur les clients, les concurrents, les tendances du marché et d’autres facteurs clés. Comme ces données proviennent de nombreuses sources et peuvent être non structurées, leur gestion est un défi. Il est difficile, voire impossible pour les groupes internes (analystes d’entreprise traditionnels et équipes informatiques travaillant avec les systèmes existants) de gérer et d’appliquer cette technologie par eux-mêmes.
– La nouvelle accessibilité de l’Intelligence artificielle (IA)
L’Artificial Intelligence (Intelligence artificielle) et la Machine Learning (apprentissage automatique) qui relevaient autrefois de la science-fiction sont désormais monnaie courante et arrivent juste à temps pour relever le défi du Big Data. Le volume, la variété et la vitesse des données ayant augmenté de manière exponentielle, la capacité à détecter des modèles et à faire des prédictions dépasse la capacité de la cognition humaine et des techniques statistiques traditionnelles. Aujourd’hui, l’Intelligence artificielle et l’apprentissage automatique sont nécessaires pour effectuer des tâches robustes de classification, d’analyse et de prédiction des données.
– Les gains énormes en puissance de calcul
La Data Science ne serait pas possible sans les récentes améliorations majeures de la puissance de calcul. Une percée cruciale a été de découvrir que les processeurs informatiques conçus pour restituer des images dans les jeux vidéos seraient également adaptés aux applications d’apprentissage automatique et d’Intelligence artificielle. Ces puces informatiques avancées sont capables de gérer des algorithmes mathématiques et statistiques extrêmement sophistiqués et fournissent des résultats rapides même pour les défis les plus complexes, ce qui les rend idéales pour les applications de science des données.
– Nouvelles techniques de stockage des données, y compris l’informatique dématérialisée
La Data Science dépend d’une capacité accrue à stocker des données de toutes sortes à un coût raisonnable. Les entreprises peuvent désormais stocker raisonnablement des pétaoctets (ou des millions de gigaoctets) de données, qu’elles soient internes ou externes, structurées ou non structurées, grâce à une combinaison hybride de stockage sur site et en nuage.
– Intégration de systèmes
La Data Science met en relation toutes les parties de votre organisation. Une intégration étroite et rapide des systèmes est donc essentielle. Les technologies et systèmes conçus pour déplacer les données en temps réel doivent s’intégrer de manière transparente aux capacités de modélisation automatisée qui exploitent les algorithmes de Machine Learning pour prédire un résultat. Les résultats doivent ensuite être communiqués aux applications en contact avec la clientèle, avec peu ou pas de latence, afin d’en tirer un avantage.
Quels avantages une entreprise peut-elle tirer de la Data Science ?

La Data Science peut offrir un large éventail de résultats financiers et d’avantages stratégiques, en fonction du type d’entreprise, de ses défis spécifiques et de ses objectifs stratégiques.
Par exemple, une société de services publics pourrait optimiser un réseau intelligent pour réduire la consommation d’énergie en s’appuyant sur des modèles d’utilisation et de coûts en temps réel. Un détaillant pourrait appliquer la Science des données aux informations du point de vente pour prédire les achats futurs et sélectionner des produits personnalisés.
Les constructeurs automobiles utilisent activement la Data Science pour recueillir des informations sur la conduite dans le monde réel et développer des systèmes autonomes grâce à la Machine Learning. Les fabricants industriels utilisent la Science des données pour réduire les déchets et augmenter le temps de fonctionnement des équipements.
Dans l’ensemble, la Data Science et l’Intelligence artificielle sont à l’origine des avancées en matière d’analyse de texte, de reconnaissance d’images et de traitement du langage naturel qui stimulent les innovations dans tous les secteurs.
La Science des données peut améliorer de manière significative les performances dans presque tous les domaines d’une entreprise de ces manières, entre autres :
– Optimisation de la chaîne d’approvisionnement
– Augmentation de la rétention des employés
– Compréhension et satisfaction des besoins des clients
– Prévision avec précision des paramètres commerciaux
– Suivi et amélioration de la conception et des performances des produits.
La question n’est pas de savoir ce que la Data Science peut faire. Une question plus juste serait de savoir ce qu’il ne peut pas faire. Une entreprise dispose déjà d’énormes volumes d’informations stockées ainsi que d’un accès à des flux de données externes essentiels. La Science des données peut tirer parti de toutes ces informations pour améliorer pratiquement tous les aspects des performances d’une organisation, y compris ses résultats financiers à long terme.
Quel est l’avenir de la Data Science ?
La Data Science est de plus en plus automatisée et le rythme de l’automatisation va sûrement se poursuivre.
Historiquement, les statisticiens devaient concevoir et ajuster les modèles statistiques manuellement sur une longue période, en utilisant une combinaison d’expertise statistique et de créativité humaine. Mais aujourd’hui, alors que les volumes de données et la complexité des problèmes d’entreprise augmentent, ce type de tâche est si complexe qu’il doit être traité par l’Intelligence artificielle, l’apprentissage automatique et l’automatisation. Cette tendance se poursuivra à mesure que le Big Data prendra de l’ampleur.
L’Intelligence artificielle et l’apprentissage automatique sont souvent associés à l’élimination des travailleurs humains. Mais, ils ne font en réalité qu’accroître l’essor des Citizen Data Scientists, ces professionnels de la Data Science sans formation formelle en mathématiques et statistiques.
En conclusion, rien n’indique que l’automatisation remplacera les spécialistes des données, les ingénieurs de données et les professionnels des DataOps qualifiés. Il faut autant de créativité humaine que possible à différentes étapes pour tirer parti de toute la puissance de l’automatisation et de l’Intelligence artificielle.

La transformation digitale des entreprises est en marche ! Ce terme qui englobe tous les changements liés à l’intégration de nouvelles technologies dans la société contient le Big Data comme l’un de ses piliers les plus solides. Pour les entreprises, l’explosion des « grosses données » est au cœur des problématiques actuelles qu’elles doivent affronter. Cela nécessite la création de moyens efficaces pour les recevoir et les utiliser au mieux, permise par des professionnels aguerris des Data Sciences.
Les cabinets de conseil en stratégie sont des acteurs majeurs dans cette digitalisation de l’entreprise. Ils accompagnent les autres entreprises dans leur stratégie de transformation digitale, soit en tant que cabinets spécialisés, soit pour les cabinets généralistes en intégrant un segment dédié à leur offre d’expertise. Mais ils sont eux-mêmes sujets de cette transformation digitale et doivent intégrer de nouvelles compétences à leur cœur de métiers pour des propositions à plus forte valeur ajoutée.
Pourquoi intégrer les Data Sciences au conseil en stratégie ?
Aujourd’hui, la Data Science, ou science des données est utilisée par les entreprises comme outil d’analyse pour aider à la décision. Et plus il y a de données, plus le recours aux spécialistes de la data science est indispensable.
Le cas des cabinets de conseils en stratégie en est le parfait exemple. Ces derniers ont comme mission de répondre à une problématique précise pour le compte de leurs clients. L’expertise attendue d’eux repose sur la conduite de recherches et d’analyses stratégiques à partir de données fournies directement par les clients ou de données externes. Opérant sur une grande variété de secteurs, ils stockent donc un nombre de données très important.
Mais si les data sont historiquement au cœur du métier de consultant, les temps changent et les technologies avec. Pour fournir la meilleure analyse possible et garder un avantage concurrentiel, les cabinets se doivent d’évoluer au rythme de ces avancées. L’amélioration du CRM grâce à la personnalisation de la relation client, l’optimisation et la prédiction des coûts, la sécurisation et la détection de fraude, la vérification de l’authenticité de produits… sont tant d’exemples permis aujourd’hui par des méthodes et algorithmes très poussés au centre des outils utilisés dans les Data Sciences.
L’utilisation des Data Sciences intervient à chaque niveau de la chaine de valeur ; du début de la réflexion à la solution fournie au client en passant par le suivi. La conjoncture des 3 V qui définissent les Big Data – Volume, Vélocité, Variété – permet de mieux répondre aux due diligences et en un temps plus restreint.
C’est dans cette optique que le BCG a vu naître sa nouvelle entité dédiée à la Data Science : BCG Gamma. Avec Cedric Villani (médaille Fields 2010) comme conseiller scientifique, et l’INRIA (l’institut national de recherche en sciences du numérique) comme partenaire, le message porté par cette initiative est clair : mêler la recherche au monde de l’entreprise pour améliorer les performances. L’équipe est composée de 250 personnes : des experts scientifiques maitrisant les techniques mathématiques et statistiques liées à l’intelligence artificielle, au machine et deep learning, mais également des consultants experts dans les secteurs conseillés par le cabinet, concentrés sur l’aspect analytique des données.
Les profils des data-consultants
S’ils étaient absents du monde du conseil il y a encore 5 ans, les Data Sciences y sont aujourd’hui indispensables. Le recours à cette nouvelle science ne se fait plus seulement à travers l’utilisation ponctuelle de l’expertise d’acteurs de la tech dans le cadre de partenariats. Aujourd’hui, les Data Scientists arrivent au sein même des cabinets de conseils. Et demain, ils se mêleront à part entière aux consultants.
Chez ces férus d’informatique et de nouvelles technologies, les nouvelles façons de s’intégrer aux grands cabinets de conseil sont multiples. Toutefois, deux grandes tendances dominent : (1) être une fonction support (2) être un consultant à part entière.
L’équipe BCG Gamma réunit des doubles profils « consultants-data scientists » autour des problématiques classiques du grand groupe de conseil dans les différents secteurs où il opère. Ils sont pleinement intégrés au groupe et ont le même objectif final que tout consultant : conseiller le client en lui apportant une expertise poussée. Mais le moyen pour y parvenir diffère : « Là où un consultant utilisera Excel pour créer un modèle d’analyse, nous avons recours à des algorithmes pour modéliser des volumes de données plus complexes » (Thomas Lewiner, BCG Gamma). Aussi, à la différence du consultant type, les consultants « geeks » n’ont pas suivi un parcours en école de commerce ou d’ingénieur, mais des formations dédiées aux data sciences, en informatique, allant parfois jusqu’au doctorat (46%). Ces consultants s’inscrivent pleinement dans la transformation digitale des entreprises par leur utilisation des Data Sciences qui accélèrent et optimisent l’arrivée vers le résultat voulu.
Dans d’autres cabinets, les data scientists ne sont pas consultants mais forment une équipe bien distincte dont la vocation unique est de gérer les données.
C’est par exemple le cas de PMP ou d’EY qui se sont dotés en 2016 de leurs « Data Lab » ou « EY Digital Lab », choisissant de s’inscrire pleinement dans l’ère de la transformation digitale sans dénaturer la fonction de consultant. Ces deux laboratoires de la donnée ont comme rôle d’assurer une fonction support pour les différentes entités des groupes. Les talents de ces laboratoires s’occupent de traiter et gérer les données avant que les consultants ne les analysent pour en fournir une interprétation.
L’enjeu est de taille pour ces data scientists, car s’ils exercent leur métier sans se confondre aux consultants, ils doivent bien s’adapter à ces derniers. Pour générer un gain de temps grâce au Big Data, ils doivent donc parvenir à vulgariser leur langage afin qu’il soit exploitable au maximum et parfaitement intégré dans la chaine de valeur.